そうだ、HTTP/2に移行しよう(実践編)
...こんにちは、エンジニアの吉田です。
前回そうだ、HTTP/2に移行しよう(OpsWorks編)の記事を執筆しましたが、今回はその続編となります。 (前回から時間が経ってしまい申し訳ないです汗)
前回はHTTP/2に移行する為にAWS OpsWorksを用いたChef12スタックでの シンプルな環境を構築するところまでお伝えしました。 しかし実際はChef12スタックは、Chef11以前のスタックと違い それまでのレシピの運用方法を変えなければなりません。 今回は、現場でのOpsWorks Chef12スタックにおける課題の解決にフォーカスした実践編となります。
実践編
その1. OpsWorksのChef12スタックでコミュニティクックブックを利用したレシピを実行する
Chef12スタックで最も注意しなければならない点は、レシピを実行する際に 利用するコミュニティクックブックの参照が自動的に行われなくなったことです。 試しにコミュニティクックブックを利用したレシピをそのまま実行しようとしたら 「コミュニティクックブック?そんなの見つからないよ!」と怒られます。
なので解決方法としてはコミュニティクックブックを含んだクックブックアーカイブを事前に作成し s3にアップロードした場所を参照するようにします。
コミュニティクックブックを含んだクックブックアーカイブを作成
[前提条件] アーカイブ作成にはBerkShelfをインストールしている必要があります。 もし無い方はChefDKをインストールするか、もしくはGemでBerkShelfをインストールしてください。 ChefDK: https://downloads.chef.io/chefdk Gem:
gem install berkshelf[手順] 1. ローカルでクックブックのディレクトリに移動する
2.
berks packageコマンドを実行してアーカイブを作成する デフォルトだとcookbooks-1506749951.tar.gzといったタイムスタンプ付きのアーカイブが出来上がります。 もしファイル名を指定したい場合はberks package {ファイル名}.tar.gzのようにコマンドを実行します。3. アーカイブを格納する為のs3バケットを作成する
4. 手順3で作成したバケットにアーカイブをアップロード
AWS CLIのS3コマンドが便利です。
aws s3 cp cookbooks.tar.gz s3://{バケット名}実行後、S3にアーカイブファイルがアップロードされていることを確認します。
EC2からStorage Gateway経由でS3をNFSマウント
...こんにちは、インフラ担当の赤川です。
AWSの最新情報(英語版)にて、StorageGatewayを利用してEC2からS3マウントが可能になるとのアナウンスされました。
今回のアップデートにより、これまでの問題が解消できるのかベンチマークを取ってみました。
準備した環境
クライアント
比較するために以下A〜C3つのインスタンスを準備しました。
A.FileGateway経由でS3バケットをnfsマウントしたディレクトリをDocumentRootとしたインスタンス B.s3fsでS3バケットをマウントしたディレクトリをDocumentRootとしたインスタンス C.ローカルディスク内にDocumentRootを配備したインスタンス
各インスタンスにhttpdをインストール。 サーバ毎にDocumentRootを変更。
StorageGateway
Gatewayの要件はこちら
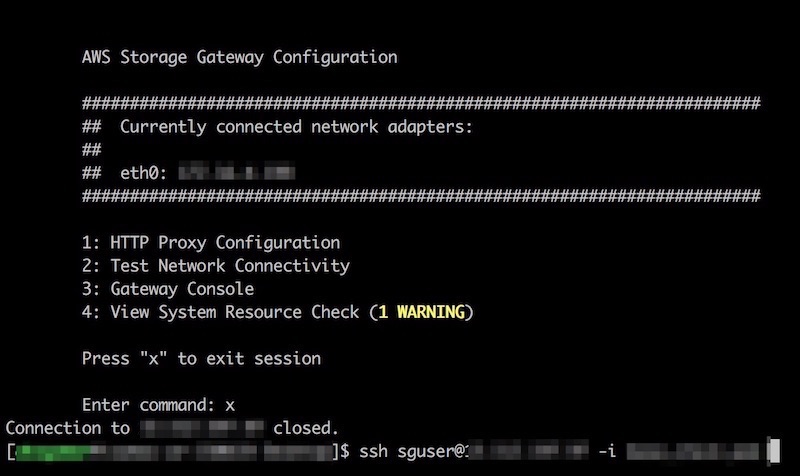
・・・なのですが、 読まないで進めたらいつまで経ってもGatewayインスタンスに接続できませんでした。 sshでGatewayインスタンスに接続すると、ご丁寧にvCPUが足りんと警告が。ちゃんと読んでスペックを確認しましょう。 (この画像はCPUでWarningですが、メモリ足りない場合はCriticalが出ていました。)
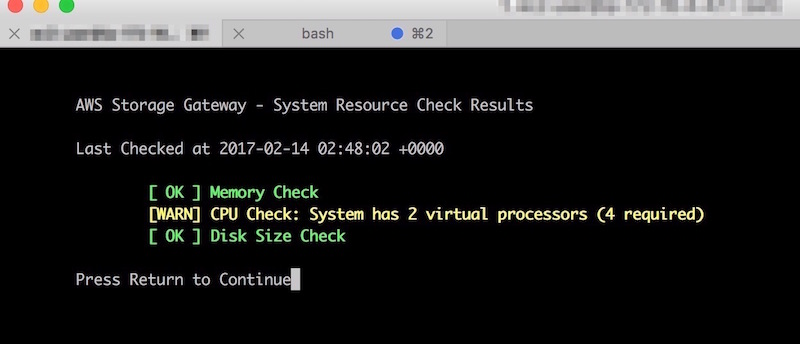
ちなみにGatewayインスタンスへのssh接続ユーザのデフォルトは「sguser」です。
S3
マウントするバケットを事前に作成しておきます。
FileGateway設定
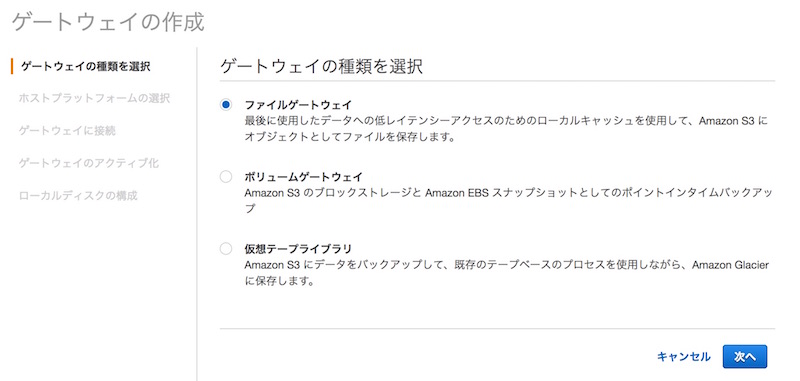
まずはStorage GatewayのメニューからFile Gatewayを作成します。
GatewayのタイプはEC2を選択します。 赤枠で囲ったボタンをクリックするとEC2起動画面が開きます。
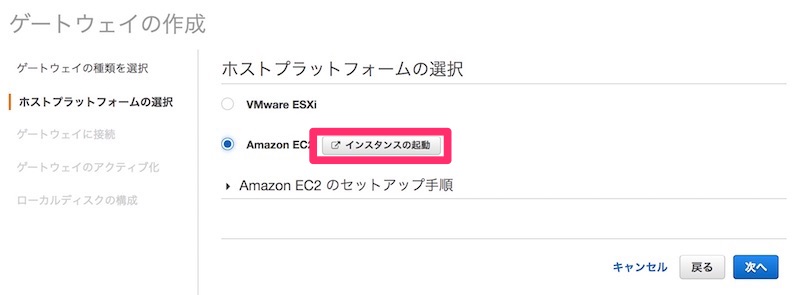
どうやらGateway用のAMIが用意されているようです。 前述の注意点を気にしながらインスタンスを作成します。
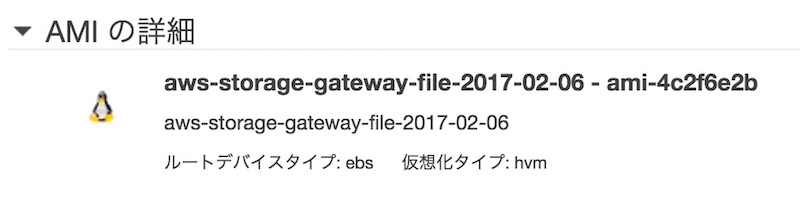
インスタンスを作成したらFile Gatewayの画面に戻ります。 Gateway IPアドレスを求められるので先ほど作成したインスタンスのIPを指定します。 続いてアクティベートも実行されます。
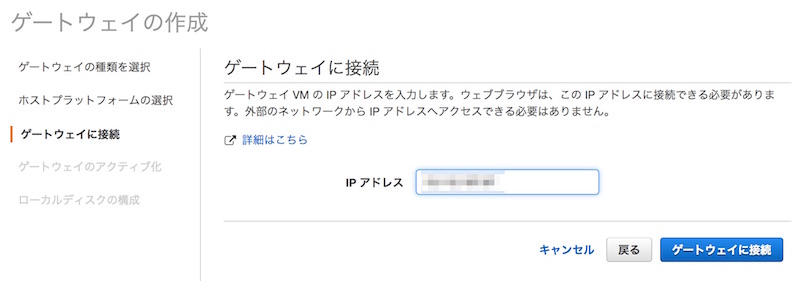
次にファイル共有の設定を実施します。 作成したGatewayを選択して「ファイル共有の作成」をクリック。
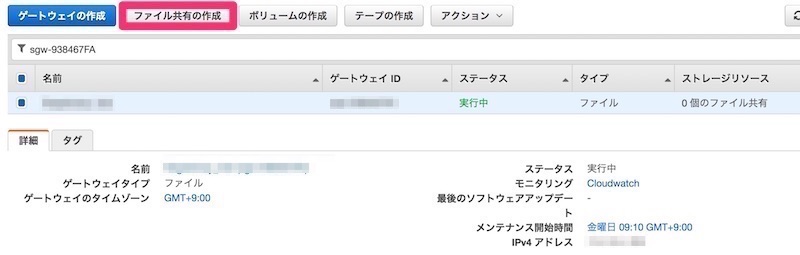
マウントするS3バケット名を入れます。 また、S3へ接続できるIAMロールも設定しておきます。
AWS S3を早くするフォルダ構成
...こんにちは、豊部です。
AWS S3をコンテンツデータのストレージに使う場合、転送速度が気になります。
S3は無限ともいえるストレージ領域がありますので、裏では様々な処理が行われ、
全世界で負荷をシステム全体でならすように設計されています。
このシステム全体をならす仕組みをフォルダ構成から利用できます。
ポイントは
・フォルダ名の先頭3文字でS3内で分散させている
です。
たとえば、コンテンツを3つのフォルダに分ける場合、
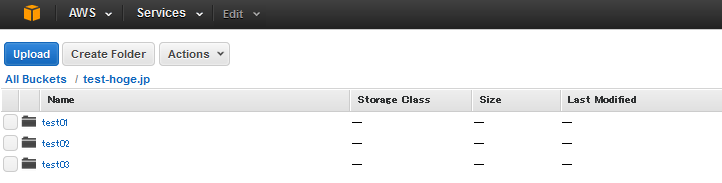
のようにしてしまうと、先頭3文字が「tes」となり、同じ場所に格納されてしまいます。
そこでフォルダ名の先頭にハッシュ値を頭につけて
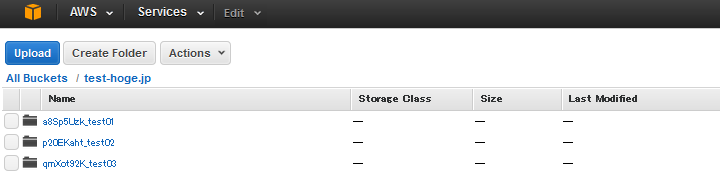
としましょう。
こうすれば、S3内で分散されて格納されるため、転送速度が向上します。
S3を配信コンテンツのストレージにする場合は、試してみてください。