GitHubでpush時にAWS OpsWorksで自動デプロイする方法
...開発の平形です。
今日は、GitHubでpush時にAWS OpsWorksで自動デプロイする方法をお教えします。
OpsWorksはAWSで提供されているデプロイのサービスです。
*OpsWorksについては、こちらのサイトが詳しいです。
この話は、OpsWorksにスタックとレイヤとインスタンスが存在する前提です。
OpsWorks自体、最近触ったばかりですが、
デプロイがすごく簡単にできるという事はよくわかりました。でも、欲張りな僕は、もっと自動化できないのかな?と思ったのです。
普段、ソースはGitHubでバージョン管理しているので、
GitHubにpushしたら同時にデプロイできないのかな?と。そしたら、ビックリするほど簡単に実現できました。
GitHub側で設定が可能です。
アプリケーションのリポジトリのページの「Settings」
「Service Hooks」
AWS OpsWorks

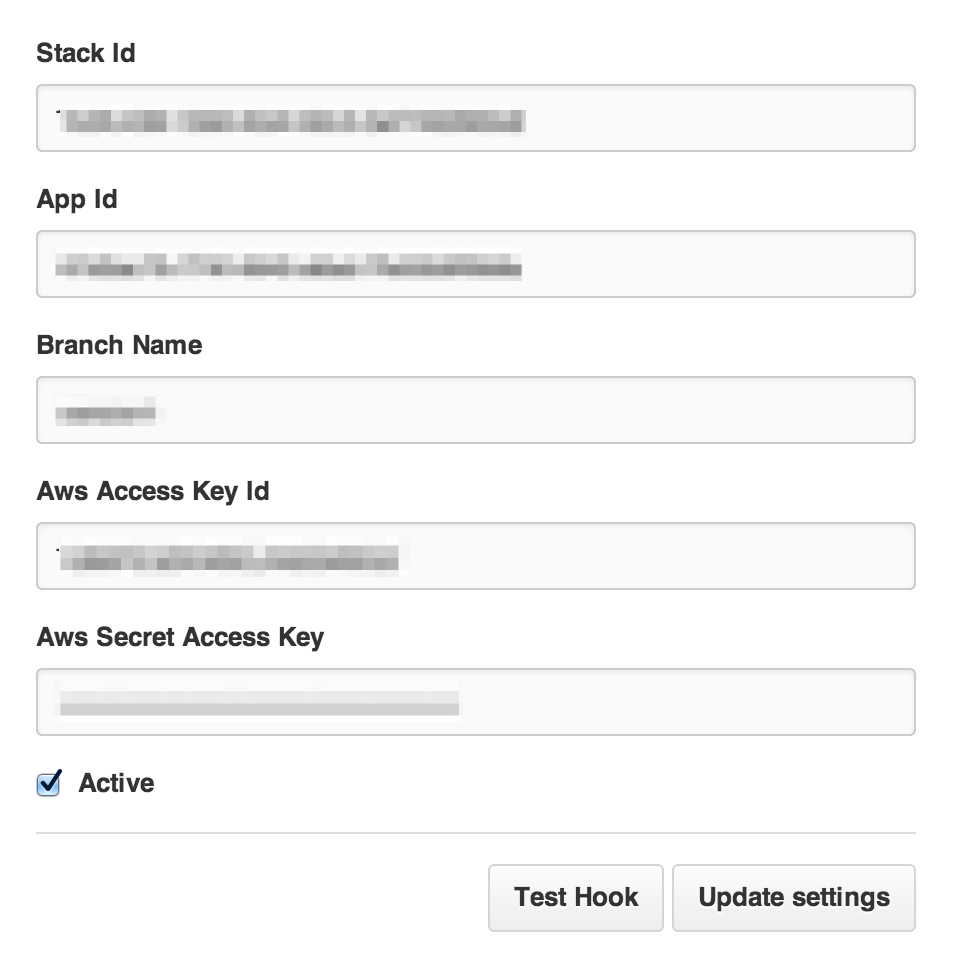
以下の項目は全て必須なので、全部入力します。
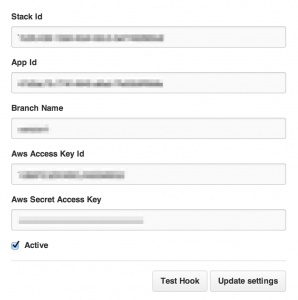
ここで、OpsWorks側の情報が必要になります。
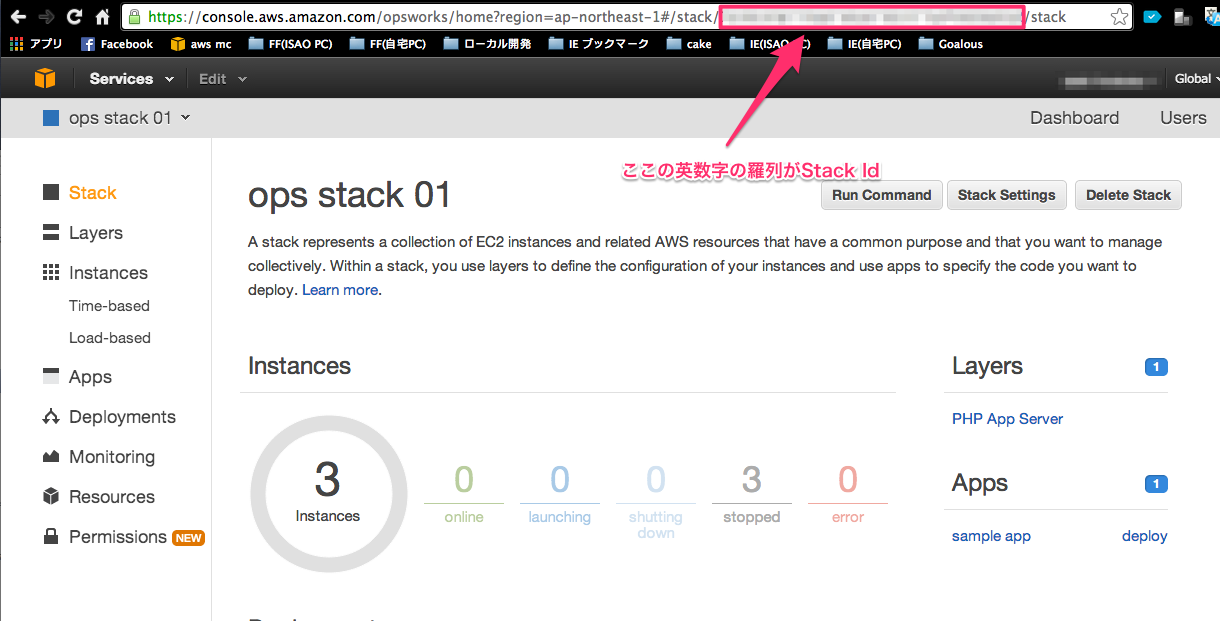
まずは、Stack Idですが、一見これがわかるところが、AWS Managed Consoleの画面上にはありません。
手っ取り早くこれを確認する方法はStackの画面のURLをみる事です。
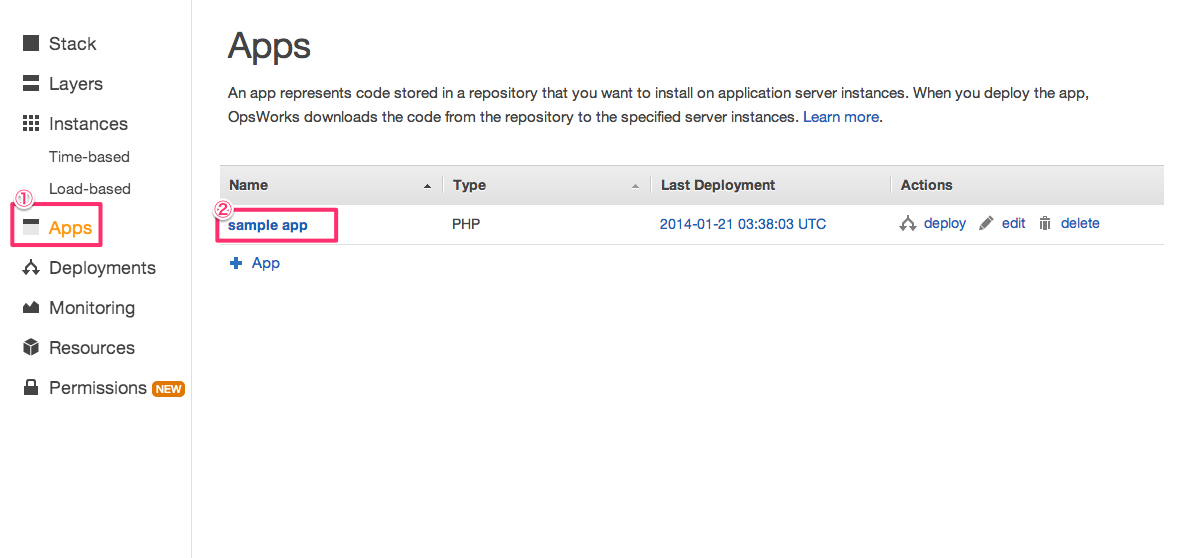
次にApp Idですが、同じくOpsWorksの画面で、「Apps」=>「アプリケーション名」をクリック
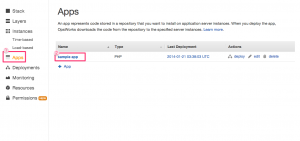
OpsWorks IDがApp Idです。
MysqlのHAとトラブル事例
...久しぶりの更新になります。プラットフォームの宮下です。
先日開催されました、July Tech Festa2013というイベントの中の1コマで何と私が発表をさせて頂きました。
その時使用した資料をアップしますので興味のある方は是非一読下さい。[slideshare id=24320385&doc=mysqlha-130716215401-phpapp02]
mysqlのHA構成のデザインパターン紹介を経験談を交えて話させて頂きました。
とても緊張してしまって肝心のトラブル事例がお話出来ませんでした。このブログでは、包み隠さずトラブルのレポートが出来ればと思います。
今回のテーマは、小宮先生のレポートを多分に活用させて頂いています。
次回こそは、私の成果を発表したいもんです。それではまた近いうちに更新します。
mysqlパフォーマンス改善への道(その1、現状の確認)
...パワー不足のmysqlをチューニングしてみます。
こんばんわ。プラットフォーム担当の宮下です。
今回は、バックアップ兼集計用に稼働しているmysqlのレプリケーションンサーバの
パフォーマンス改善していきたいと思います。
これまでにもいくつか対策はしてきましたが、まずは環境をおさらいします。◇稼働してる環境は、AWSのEC2でlargeインスタンスを使用しています。
サービスは、OpenPNEを使用したSNSのサービスとなります。対象のMysqlはバックアップとデータ集計が目的で稼働しています。
(本番サービスでは使用していません)◇mysqlのバージョンはちょっと古くて「5.0.77」になっています。multiで起動させていていて
この他に開発環境用のmysqlも稼働していたりします。 ちなみに今の遅延秒数は、「1512561 秒」でまだ増加中です。◇これまでに変更した点ですが、
「innodb_buffer_pool_size」を512Mから2028Mまで増加、
「innodb_flush_log_at_trx_commit」を2から0に変更、
(リカバリの精度よりもスループットを優先)
「key_buffer_size」を32Mから300Mに変更、
「query_cache_size = 0」にして無効化しました。
効果は、DISKのI/Oが半分くらい減りましたが、遅延解消とまではいってません。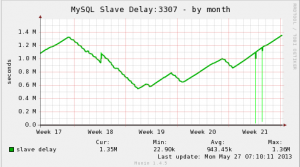
遅延が日々増えています。たまに減る事もありますが要因は分かりません。
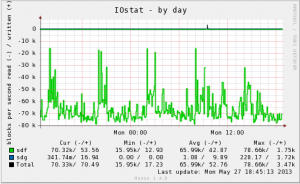
常にDISKのread I/Oが大量に発生しています。
原因ははっきりしていて、DBデータに画像や動画データが格納されている為となります。
buffer pool sizeでは収まり切らないデータサイズなので常にDISKのread/writeが発生しています。
またMyISAMとInnodbが混在していてリソースが効率的に利用出来ていない事や、
OpenPNEが「delete aaa filename LIKE ‘%bbb%’」というクエリを大量に発行している事
などが解決すべき課題がたくさんあります。現状を整理した事で、次回からは一つずつ改善対策を実施していきたいと思います。
AmazonEBSでraid0を組んだ時のパフォーマンス検証
...AmazonEBSでraid0を組んだ時のパフォーマンス検証
EBSを組むと早いはなしを検証したい
testでマルチ、ラージなら結構こうかある説がある模様。
既存移行の方法も検討(バイナリログ等のディレクトリ分けるところからかと。)公式のユーザガイド(EBSPerformance)
EBS自体が冗長構成組まれているのでraid0でいいと思われる。インスタンスディスク(ローカルディスク、エフェメラルディスク)を使ってRAID0
EBSでRAID0を組むことは、RAID10(ミラーのストライプ)と同等であるLargeインスタンス以上であれば、1台よりも2台の方がディスクI/O性能が目に見えて上がりました
エフェメラルディスク(stopすると消えるほうのディスク)でraid0したい場合の起動コマンド例
[shell] ec2-run-instances ami-e965ba80 –region us-east-1 –key id_rsa –group sg-a4866fcc –placement-group test –instance-type cc2.8xlarge -b “/dev/sdb=ephemeral0” - b “/dev/sdc=ephemeral1” -b “/dev/sdd=ephemeral2” “/dev/sdf=ephemeral3” [/shell] ・ラージでEBSディスクを2つ追加して起動してログインする
[shell] # df -h Filesystem Size Used Avail Use% Mounted on /dev/xvde1 9.9G 867M 8.5G 10% / none 3.7G 0 3.7G 0% /dev/shm # ls -l /dev/xv* brw-rw—- 1 root disk 202, 65 Mar 21 02:15 /dev/xvde1 brw-rw—- 1 root disk 202, 80 Mar 21 02:15 /dev/xvdf brw-rw—- 1 root disk 202, 96 Mar 21 02:15 /dev/xvdg find /dev -type b -print [/shell] してみたがそれらしい名前のは上記のみ。

{kind=link}
{kind=link}