DevOps時代のアジャイルでスケーラブルな開発環境をVagrant, GitHub, Travis, Chef, OpsWorksで構築する
...どうも。久しぶりです。 デベロッパーの平形です。
このブログに訪れたすべてのエンジニアの方々。 そして、エンジニア以外の方々。
とても感謝致します。 初めに言っておきますが、この記事ではコード、コマンドラインの一切は登場しません。
はじめに
私が今回お送りする内容は本当にスケーラブルな環境の構築、運用を手助けする事ができます。 連載記事で複数回に渡ってお届けしますが、この連載を読み終えそして実践していただければ、あなたは既にスケーラブルな環境で作業を行っている事でしょう。
この連載記事では、順番に必要なツールのインストール、使い方をハンズオン形式でお送りします。 実際に手を動かして実感していただく事がとても意味がある事だと思っています。 この回では、コード、コマンドラインは一切登場しません。次回以降にどんどん出てきます。 その前に**「伝えたい事があるんだ。君の事が好きだから」by小田和正**と叫ばせてください。
この記事は以下の方には不向きです。
- 俺は一生一人で生きていくんだ!と1日1回はトイレで意気込んでいる人。
- 後先の事なんか考えたくない。俺は今を生きているんだ!と週に3回は言っている人。
これらに該当する方。お疲れ様でした。出口はこちらです。
この記事は以下に該当する方に是非読んでいただきたいです。
- 開発者、インフラ担当者の方。
- これから新しいプロジェクトを立ち上げるんだけど、構成どうしようか悩んでる方。
- サーバーの台数が多くなったらどうしよう。と悩んでいる方。
- 開発要員が急に増えたらどうしよう。と悩んでる方。
- DevOpsとかスケーラブルな環境とかに興味があって、でも今ひとつ踏み出せない方。
- 上記を実践してみようとしたけど、挫折してしまった方。
- 開発環境で動いているコードがなぜか公開環境で動かなくて家に帰れない方。
- 本番反映が怖くて会社に行きたくない方。
- サーバーが落ちる事が不安で夜も眠れない方。
- 将来の事を考えると不安で不安で仕方なく、「とにかくもう、学校や家には帰りたくない〜。」by尾崎豊と口ずさんでしまう方。
それでは、夢の扉を開きましょう。
レガシーな開発と運用
- 開発環境、公開環境の構築は、構築手順書を元に手動でインストールしている。
- 公開環境のサーバー増設は1台ずつ手動でキッティングしている。
- パッチの適用、バージョンアップは手動で1台ずつ手順書を元に実行している。
- バージョン管理はしないで各自、修正ファイルをFTPでファイルをアップロードしている。
これらをヒューマンエラーなく、ストレスなく運用できるのはスーパーマンです。 そして、開発、運用メンバー全員が自分と同じスーパーマンでなければいけません。 凡人の僕には無理です。
現代の開発と運用
現代のもの凄い勢いで変化するサービス要求に耐えるには、様々なものを効率化しなければいけません。
素早くリリースしてユーザの反応を見ては仕様を変更してすぐに反映しまたリリースする。といった事も必要です。
近頃、開発運用の自動化は様々なメディアの記事で取り上げられ、賑わっています。 しかし、実際にどこまで自動化ができているのでしょうか?- バージョン管理
- 環境構築
- セキュリティパッチの適用
- バージョンアップ
- オートスケール
- 自動テスト
- 自動デプロイ
- 開発環境の配布
なかなか全部はできないですよね? でもやったほうが絶対に幸せになれます。
AWS S3を早くするフォルダ構成
...こんにちは、豊部です。
AWS S3をコンテンツデータのストレージに使う場合、転送速度が気になります。
S3は無限ともいえるストレージ領域がありますので、裏では様々な処理が行われ、
全世界で負荷をシステム全体でならすように設計されています。
このシステム全体をならす仕組みをフォルダ構成から利用できます。
ポイントは
・フォルダ名の先頭3文字でS3内で分散させている
です。
たとえば、コンテンツを3つのフォルダに分ける場合、
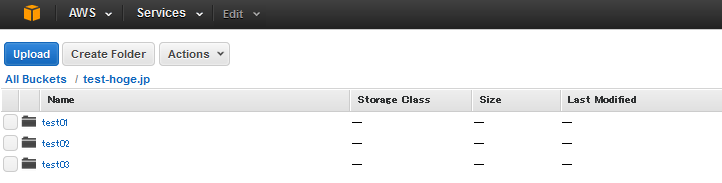
のようにしてしまうと、先頭3文字が「tes」となり、同じ場所に格納されてしまいます。
そこでフォルダ名の先頭にハッシュ値を頭につけて
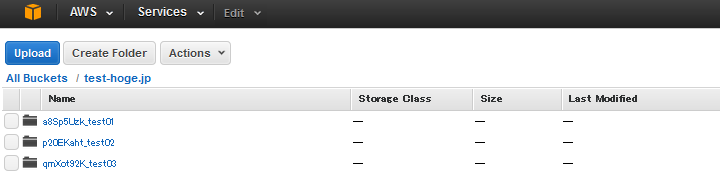
としましょう。
こうすれば、S3内で分散されて格納されるため、転送速度が向上します。
S3を配信コンテンツのストレージにする場合は、試してみてください。
AWS : EC2 C4インスタンスリリース!
...今月の初め、AWS より EC2 サービスにて新しいタイプのインスタンス、 C4 インスタンスの提供開始とのアナウンスがありました。
トピックを共有したいと思います。
- Intel が AWS 専用にカスタマイズして提供している Haswell ベースの CPU を採用。
- EBS 最適化オプションを標準装備。その代りSSD ベースのインスタンスストレージは無し。
- 利用できる仮想化タイプは hvm のみ。PV (paravirtual) は利用できません。
- 拡張ネットワーキングも標準装備され、低遅延化などが施されている。
パフォーマンスの劇的な向上や新しい何かを期待されていたユーザー様は残念がっている方もいるようですが、
HVM のみのサポート、CPU、ストレージ、ネットワーク周りの底上げを行っており、インフラとして順当な進化を遂げているなぁ、というのが僕の感想です。
AWSのCloudwatchにアラート(Alarm)を設定し、監視する
...こんにちは。新人の橋本です。
これまではオンプレミスのハイブリッドクラウド(プライベート+パブリック)や物理サーバにて運用構築業務についてましたが、
AWS自体は初めて取り扱う環境ですので、その目線から、ブログを書いていきたいと思います。
今回はAWS導入後、基本的なリソース監視ができるCloudwatchの設定、およびAlarmを設定し、閾値を超えたらEメールを送付するという
ごくごく基本的な設定について記載します。
1)設定画面
EC2にてインスタンス作成後、EC2の[Instance]項目にてにてAlarm設定したいインスタンスを選択し、[monitoring]タブを選択します。
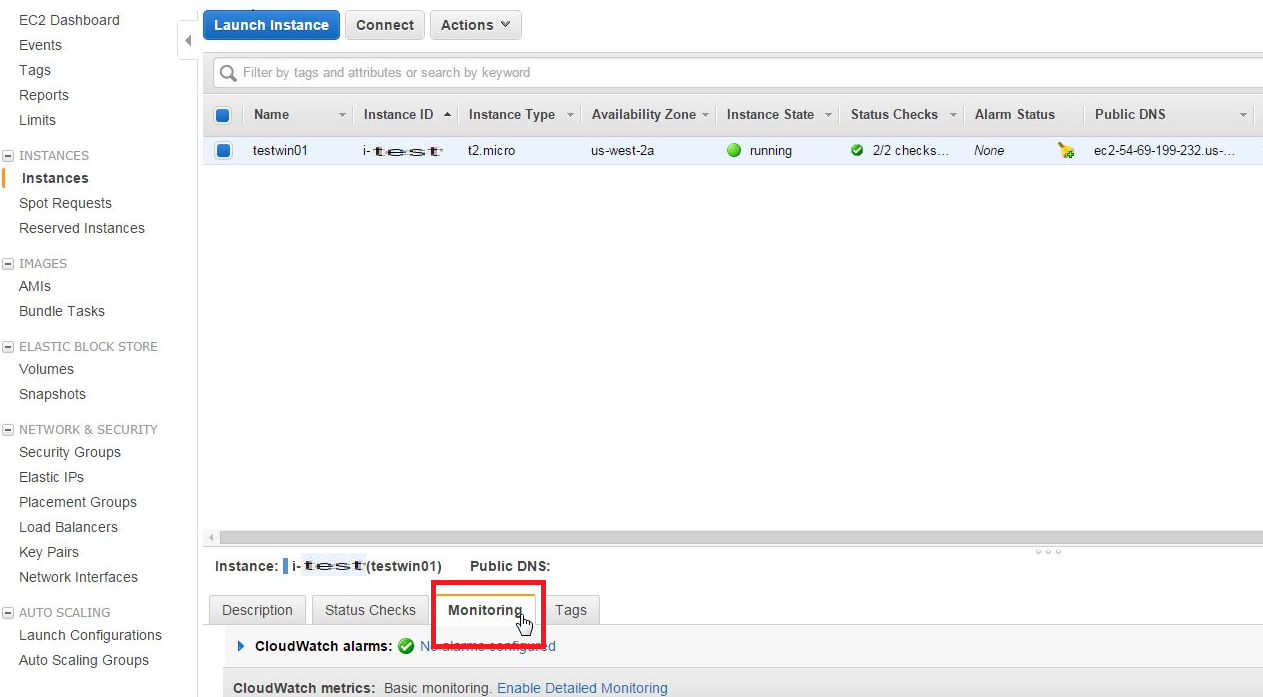
2)Alarm設定
右部分にある[Create Alarm]を選択すると、CreateAlarm画面が表示されるため、各項目を入力します。
- Send a Notification to → 別項目にて、SNS topicを作成している場合、リストに追加されます(今回は追加しません)
- Take the action → Alarm発生時のアクション。発生した場合どうするかを選択できます(今回は設定しません)
- Whenever → リストより程度(Average,Max,Minimumなど)、および項目(CPU Utilization、Disk Usageなど)を選択します
- Is → 閾値(○○パーセント以上or以下など)を設定します
- For at least → 判定条件(○分間毎に△回[Whenever]項目が[Is]だった場合にAlarmカウントする)を設定します
- Name of Alarm → Alarm名を設定します
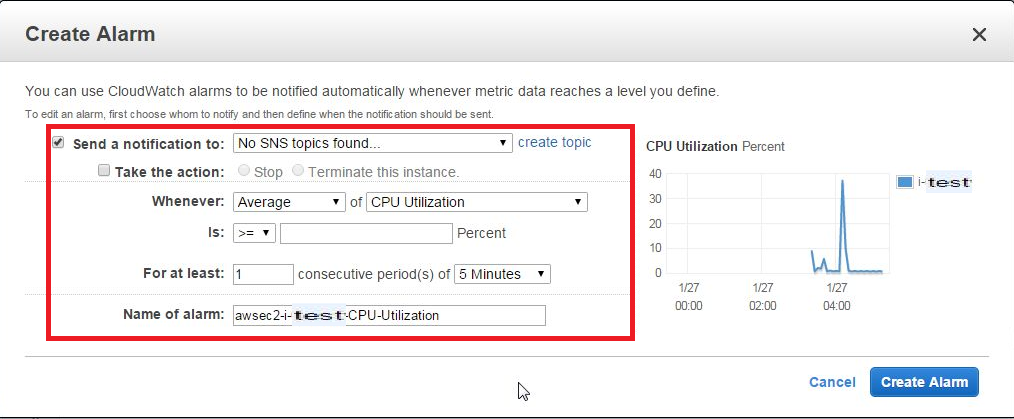
3)設定追加
各項目設定後、右下の[Create Alarm]を選択すると、Alarm項目が作成され、次の画面が表示されるので、リンクをクリックします。
4)項目追加確認
CloudWatch Management Console画面に遷移するため、項目が追加されたことを確認し、[Modify]タブをクリックします。
AWS SDK for Rubyを使ってEC2インスタンスのステータスを確認する
...アプリケーション側で、任意のAWSのEC2インスタンスについて、現在の稼働状況をリアルタイムに確認したい時がある。例えば外部アプリケーションからEC2インスタンスを起動させたり、停止させたりする場合などに、インスタンスの稼動状況を確認してステータスが変わったら次のプロセスを実行したいとかいうケースが、それに当てはまる。
SDK for Rubyでは、
AWS::EC2クラスのclient.describe_instance_statusメソッドで特定のECインスタンスのステータスを取得することができる。インスタンスのステータスにはsystem_statusとinstance_statusの2種類があって、正確な稼動状態を確認したい場合はこの2つのステータスを取得する必要がある。 そして、注意しないといけないのが、インスタンスが停止している時はステータスが存在していないということだ。つまり、停止しているインスタンスに対してclient.describe_instance_statusメソッドを実行した場合、ステータス情報が格納されているinstance_status_setオブジェクトの中身が取得できないので、それを踏まえてコーディングしないと、ステータス取得エラーとなってしまう。 例えば、停止状態のインスタンスを起動した場合のステータスを監視する時など、最初はインスタンスが停止しているので、instance_status_setオブジェクト内にステータスがないということをあらかじめ想定して処理を作る必要がある。 また、ターミネートされたインスタンスはclient.describe_instance_statusメソッドを実行する対象自体がないことので、こちらも注意する必要がある。さて、上記もろもろを踏まえてEC2インスタンスのステータス確認するRubyプログラムを作ってみた。
chkins.rb
# encoding: utf-8 require "aws-sdk" def check_instance_status ec2 = AWS::EC2.new( :access_key_id => Params[:access_key_id], :secret_access_key => Params[:secret_access_key], :region => Params[:region] ) AWS.memoize do status = [] if ec2.instances[Params[:instance_id]].exists? ec2info = ec2.client.describe_instance_status({ 'instance_ids' => [Params[:instance_id]] }) if ec2info.instance_status_set.empty? # instance has stopped status << 'stopped' message = '%s has stopped' else ec2info.instance_status_set.map { |i| sys_status = i.respond_to?(:system_status) ? i.system_status.details[0].status : nil ins_status = i.respond_to?(:instance_status) ? i.instance_status.details[0].status : nil status << sys_status << ins_status } if status.include?('passed') # instance is running message = '%s is running' elsif status.include?('initializing') # instance is initializing message = '%s is starting' else # otherwise message = '%s is unknown status' end end else # instance has terminated status << 'terminated' message = '%s has already terminated' end puts sprintf("#{message}. status: %s", "Instance: #{Params[:instance_id]}", status) end end begin # init Params = { :access_key_id => ARGV[0], :secret_access_key => ARGV[1], :region => ARGV[2], :instance_id => ARGV[3], :timeout => ARGV[4].nil? ? 1 : ARGV[4].to_i } raise 'Parameter is missing.' if Params.values.include?(nil) for i in 1..Params[:timeout] do sleep 1 if i > 1 check_instance_status end rescue => e puts e endプログラム実行時の引数として、
Capistrano3でEC2インスタンス新規作成から初期設定までのデプロイ(まとめ)
...ここまでAWSのEC2インスタンスを新規作成して、そのインスタンスに対しての初期設定までを、Capistrano3でタスク化することをやって来ました。難儀したものの、ようやくEC2インスタンスの準備が出来て、あとはミドルウェアやアプリケーションをインストールするだけ──というところまでたどり着きました。そこで今回は、これまでのデプロイの流れを一度総括してまとめてみようかと思います。
まず、Capistrano3を稼動させるデプロイサーバの準備から。公式のAmazon Linux環境などのEC2インスタンスをAWSマネージメントコンソール等からラウンチして、ログインしたら、Capistrano3をインストールします1。
# yum update -y # yum groupinstall -y "Development Tools" # openssl version OpenSSL 1.0.1h-fips 5 Jun 2014 # openssl version -d OPENSSLDIR: "/etc/pki/tls" # curl -L https://get.rvm.io | bash -s stable # source /etc/profile.d/rvm.sh # rvm list (※ rvm rubies と表示されればインストール完了) # ruby -v ruby 2.0.0p451 (2014-02-24 revision 45167) [x86_64-linux] # rvm install 2.0.0 -- --with-openssl-dir=/etc/pki/tls # ruby -v ruby 2.0.0p481 (2014-05-08 revision 45883) [x86_64-linux] # gem install rails --no-ri --no-rdoc # gem install capistrano # gem install capistrano_colors # gem install capistrano-ext # gem install railsless-deploy # cap --v (※ cap aborted! ~と表示されればインストール完了) # gem install aws-sdkデプロイサーバにてデプロイプロジェクトを実行するユーザを作成しておきます。デプロイタスクの内容にもよるのですが、対象のユーザはsudo権限を持っていた方が都合が良いかと思います。ユーザを作成したら、そのユーザで再ログインして、ホームディレクトリで、Capistrano3用のプロジェクトを作成します。
Capistranoのタスクを新EC2インスタンスが完全起動するまでsleepさせる
...Capistranoで新規作成したEC2インスタンスが完全に起動し切っていない状態で、そのインスタンスに対してSSHアクセスするタスクを実行すると、どこかしらでエラーになってタスクが完了しません。そこで、デプロイ対象となるEC2インスタンスの起動状態をチェックして、完全に起動していない状態の場合sleepして起動を待つようなタスクを作りました。
AWSのEC2インスタンスには3つのステータス情報があり、この全てのステータスを確認しないと、インスタンスの完全起動状態とは言えないので、注意が必要でした(下図参照)。

インスタンスが起動しているかどうかの確認は、AWSマネージメントコンソールでいうところの「Instance State」が
runningであるかを判定すればOKなのですが、実際にインスタンスにSSH接続ができるかどうかの確認は「Status Checks」欄に「2/2 checks」とあるように2つのステータス(INSTANCESTATUSとSYSTEMSTATUSのreachability)が共にpassedであるかまでを確認する必要があるのです。通常、インスタンスが起動すると「Instance State」は数秒から十数秒程度でrunningになるのですが、「Status Checks」は数分程度initializingで初期化処理を行っています。このステータスが共にpassedにならないとSSHアクセスでコケます。今まで私が使っていた
checkタスクだと、「Instance State」のステータス1つしか確認していなかったので、後続タスクがSSHアクセスで中断したりしていました。それを回避するためのタスクが今回のcheckタスクになります。task :check do run_locally do created_instances_list = 'CREATED_INSTANCES' def check_instance_status(instance_ids=[]) ec2 = AWS::EC2.new AWS.memoize do ec2info = ec2.client.describe_instance_status({'instance_ids' => instance_ids}) sys_status = ec2info.instance_status_set.map { |i| i.system_status.details[0].status } ins_status = ec2info.instance_status_set.map { |i| i.instance_status.details[0].status } status = sys_status + ins_status return status.include?('initializing') ? false : true end end ec2 = AWS::EC2.new begin if test "[ -f ~/#{created_instances_list} ]" created_instances = capture("cd ~; cat #{created_instances_list}").chomp ci = created_instances.gsub(/(\[|\s|\])/, '').split(',') target_instances = ec2.instances.select { |i| i.exists? && i.status == :running && ci.include?(i.id) }.map(&:id) raise "Is not still created all instances" if target_instances.length < fetch(:instance_count) if target_instances.length == fetch(:instance_count) then # 全インスタンス起動(Instance Stateがrunning) chk_retry = 0 while !check_instance_status(target_instances) do # インスタンスステータスが全てOKでない場合は15秒待つ(※20回までリトライする) info "In preparation of the instance: Status check " + (chk_retry > 0 ? "(retry #{chk_retry + 1} times)" : "") sleep 15 if check_instance_status(target_instances) then break end chk_retry += 1 raise "Instance is not still ready. Please run the task again after waiting for a while." if chk_retry >= 20 end # ここからが全インスタンス完全起動後の処理(初回ssh接続設定) target_instance_private_ips = ec2.instances.select { |i| i.exists? && i.status == :running && ci.include?(i.id) }.map(&:private_ip_address) pkfn = fetch(:private_key_file) target_instance_private_ips.each { |var| server var, user: 'ec2-user', roles: %w{web app}, ssh_options: { keys: %W(/home/deploy-user/#{pkfn}), forward_agent: true } } end end rescue => e info e exit end end # 後続タスクのサンプル(SSHしてhostnameを表示する) on roles(:web) do info capture "hostname" end end上記設定から、後続タスクのサンプル部分を削除したタスクを、CapistranoでEC2インスタンスを作成した後のデプロイタスクの直前に挿入してやる感じです。
Capistranoで新規作成したEC2インスタンスの初期設定
...本項では、Capistranoで新規作成したEC2インスタンスへSSHで初回ログインした際の、保守用ユーザの作成、初期ユーザに対してのパスワード設定、サーバのホスト名設定など、いわゆるサーバ環境の初期設定を行うタスクを作ってみます。
その前に、ホスト名のつけ方としての色々と試してみての所感なのですが、初回SSHログイン後にそれぞれのインスタンスに対してHOSTS設定する際にEC2側にタグ付けてしていってもできるのですが、まずインスタンス作成する時にあらかじめホスト名の元となるタグを付けておいて、各インスタンスログイン後はそのタグを参照してHOST名を設定する方がスマートだと思いました。特に複数インスタンスを同時に立てる時などにホスト名に連番を振りたいとかいう時は、カウンター変数を使って回している
ec2.instances.create()時にそのカウンターの数値を転用できるので簡単でした。ということで、インスタンス作成時にタグを追加する方法ですが、# タグ情報 set :host_name, 'deploy-client' ~(中略)~ created_instances = [] cnt = 0 while cnt < fetch(:instance_count) do i = ec2.instances.create( ~(中略)~ ) sleep 10 while i.status == :panding i.tags['Name'] = [ fetch(:host_name), format("%02d", cnt+1) ].join('-') created_instances << i.id cnt += 1 end ~(省略)~── と、
ec2.instances.create()の後でタグを付けてやればOKです1。 今回はこのNameタグの値をその後のタスクでインスタンスのホスト名として利用します。いきなり横道に逸れましたが、本題に戻ります。 初回SSH時のタスクとして、前回作成した
initタスクを使います。流れとしては、デプロイサーバ側で新たに作成するユーザ用のキーペアを作成しておいて、デフォルトユーザにてSSHログイン後、まず保守用の新規ユーザアカウントを作成ます。その後、そのユーザに公開鍵認証によるSSH設定を行い、デフォルトユーザにはパスワードを設定してsudo権限を剥奪、ホスト名を設定して一旦ログアウトしています。 まず、タスク設定前に各種パラメータを定義します。Capistranoで新規作成したEC2インスタンスにSSH接続する
...前回に引き続き、Capistranoで新たに作成したEC2インスタンスにSSHでログインしてみます。
まず、事前準備として、AWS側で新規インスタンス用のキーペアを作成しておきます。AWSマネージメントコンソールの「EC2」メニューから「NETWORK & SECURITY」カテゴリの「Key Pairs」メニューで、キーペアを作成できるので、必要に応じて作成してください。本項の例では、「deploy-test」というCapistranoが稼動しているデプロイ環境用インスタンスで使用しているキーペアを使います。

そして、利用するキーペアのプライベートキーファイル(本項例では
deploy-test.pemファイル)をCapistranoを実行するデプロイ環境のデプロイを実行するユーザのホームディレクトリ(本項例では/home/deploy-user/)にアップロードしておきます1。 アップロードしたプライベートキーには適切な読み込み権限を付与しておく必要があるので、ファイルのパーミッションを変更します。$ cd ~ $ chmod 600 deploy-test.pem $ ls -l *.pem -rw------- 1 deploy-user deploy-user 1692 Jul 2 10:18 deploy-test.pemデプロイ設定ファイル
config/deploy.rbは下記のように修正。# config valid only for Capistrano 3.1 lock '3.2.1' # AWS SDK for Ruby を読み込む require 'aws-sdk' # AWS SDK用の設定 AWS.config({ :access_key_id => '<AWS ACCESS KEY ID>', :secret_access_key => '<AWS SECRET ACCESS KEY>', :region => 'ap-northeast-1', }) # AMIのimage_id # Amazon Linux AMI 2014.03.2 (HVM) set :ami_image_id, 'ami-29dc9228' # 作成するInstance数 set :instance_count, 2 # 作成するInstanceタイプ set :ec2_instance_type, 't2.micro' # 作成先のAvailability Zones set :availability_zones, [ 'ap-northeast-1a', 'ap-northeast-1c' ] # 作成先のsubnet_id(必要に応じて) set :subnet_ids, [ 'subnet-********', 'subnet-********' ] # 使用するキーペア名 set :key_pair_name, 'deploy-test' # プライベートキーファイル set :privert_key_file, 'deploy-test.pem' # 利用するセキュリティグループID set :security_groups, [ 'sg-********', 'sg-********', 'sg-********', 'sg-********' ] # Capistranoデフォルトのタスクを削除する framework_tasks = [:starting, :started, :updating, :updated, :publishing, :published, :finishing, :finished] framework_tasks.each do |t| Rake::Task["deploy:#{t}"].clear end Rake::Task[:deploy].clear desc 'Launch an EC2 instance to each availability zone different' task :launch do run_locally do ec2 = AWS::EC2.new created_instances = [] cnt = 0 while cnt < fetch(:instance_count) do if cnt.even? then current_az = fetch(:availability_zones)[0] current_sn = fetch(:subnet_ids)[0] else current_az = fetch(:availability_zones)[1] current_sn = fetch(:subnet_ids)[1] end i = ec2.instances.create( :image_id => fetch(:ami_image_id), :monitoring_enabled => false, :availability_zone => current_az, :subnet => current_sn, :key_name => fetch(:key_pair_name), :security_group_ids => fetch(:security_groups), :disable_api_termination => true, :instance_type => fetch(:ec2_instance_type), :count => 1, :associate_public_ip_address => true ) sleep 10 while i.status == :panding created_instances << i.id cnt += 1 end execute "echo -n #{created_instances} > ~/CREATED_INSTANCES" end endでは、インスタンスラウンチタスクを実行してみます。
CapistranoでAWS EC2インスタンスをデプロイする時の注意点
...前回のデプロイ設定ファイルで新たに作成されたEC2インスタンスには、キーペアやセキュリティグループなどが設定されていなかったため、そのままでは作成したインスタンスにSSHでアクセスできませんでした…1orz
その後、色々とデプロイ設定を修正して、作成したEC2インスタンスにSSHでログインするところまで出来たので、その経緯を備忘録として書いてみた次第。 まぁ、CapistranoでAWSのEC2インスタンスを作成する際…というより、「AWS SDK for Ruby」でEC2インスタンスを作成する時の注意点…に近いのかもしれない。
まず、前回の
config/deploy.rbからインスタンスラウンチのタスク部分を見てみる。desc 'Launch an EC2 instance to each availability zone different' task :launch do run_locally do ec2 = AWS::EC2.new created_instances = [] cnt = 0 while cnt < fetch(:instance_count) do if cnt.even? then current_az = fetch(:availability_zones)[0] current_sn = fetch(:subnet_ids)[0] else current_az = fetch(:availability_zones)[1] current_sn = fetch(:subnet_ids)[1] end i = ec2.instances.create( :image_id => fetch(:ami_image_id), :availability_zone => current_az, :subnet => current_sn, :instance_type => fetch(:ec2_instance_type), :count => 1 ) sleep 10 while i.status == :panding created_instances << i.id cnt += 1 end execute "echo -n #{created_instances} > ~/CREATED_INSTANCES" end end作成するインスタンスに対して、AvailabilityZoneとSubnetの設定しかしていないので、そりゃあアクセス不能になります。最低限、セキュリティグループを設定して、外部からのアクセス経路を確保して、キーペアを設定して認証ユーザがログイン可能にしてあげる必要はあります。あとは、PublicIP(PublicDNS)を自動で割り振られるようにして、インターネットからのアクセスも出来るようにしておくあたりまでが、最小設定となるかと。
PV InstanceからHVM Instanceへ変換(CentOS6)
...準備するもの
① EC2 Instance(CentOS6)既存の動いているものでもOK ② 変換元のRoot deviceのSnapshot ③ ②から作成したEBS Volume (SSDのほうが作業が早い) ③ 空のEBS Volume (SSDのほうが作業が早い)
DEVICEの確認
# fdisk -l |grep dev Disk /dev/xvda: 10.7 GB, 10737418240 bytes Disk /dev/xvdb: 4289 MB, 4289200128 bytes Disk /dev/xvdf: 10.7 GB, 10737418240 bytes <-PV環境のRoot device Disk /dev/xvdg: 10.7 GB, 10737418240 bytes <-空のEBS Volume作業開始
1.PVのDiskを縮小し、コピー容量を減らす
Capistranoで異なるAvilabilityZoneにEC2インスタンスをラウンチする
...前回、
次回はデータベースの作成や初期設定を直前タスクとして挿入して、さらにWordPressの設定ファイルの書き換え、GitHubからWordPressテーマをダウンロードするところまでやってみようと思います。
とか云っていたのですが、都合によりCapistrano3を使ってAWSのEC2インスタンス作成を行ったので、そのTIPSを残しておこうかと思います。 今回は、デプロイ用のEC2インスタンスから公式のAMIを利用してAvailabilityZonesが異なるエリアにそれぞれEC2インスタンスを立ててみました。試験的に、AMIは最新のインスタンスタイプ「t2.micro」に対応した「Amazon Linux AMI 2014.03.2 (HVM)」を利用して、Tokyoリージョンの1aと1cのAvailabilityZoneにそれぞれ2台ずつ、合計4インスタンスを同時に立ててみます。
※ 事前準備として、インスタンスを立てるAWSアカウントにてVPCやSubnet等EC2インスタンスを作成する上で必要最小限の設定をしておく必要があります。特に今回は異なるAvailabilityZoneへのインスタンスを立てるのでそれぞれのゾーンにSubnetを設定しておく必要があります。
さて、早速デプロイの手順です。 はじめに、デプロイ環境(サーバ)の設定を行うため、
config/deploy/test.rbを編集します。 今回は動的に作成したEC2インスタンスをデプロイ環境とするため、事前のサーバ設定ができません。というのも、AWSで立ち上がる新規インスタンスにはElasticIPを付与しないので、毎回PublicIPが異なり、エンドポイントURLも動的に変わってしまうためです。なので、今回はインスタンスが起動した後にCapistoranoのタスクにて対象サーバを設定するようにします。 初期のサーバ設定は不要となるので、記述をコメントアウトしておきます。なお、SSHのオプションだけは最終的に共通で利用する予定なので残しておきます(今回のデプロイタスクでは使いませんが…)。$ vim config/deploy/test.rb#role :app, %w{deploy@localhost} #role :web, %w{deploy@localhost} #role :db, %w{deploy@localhost} set :ssh_options, { keys: %w(/home/deploy/.ssh/id_rsa), forward_agent: true, }今回のデプロイでは、「AWS SDK for Ruby」を利用するので、あらかじめSDKをインストールしておきます。
$ sudo gem install aws-sdk次に、
config/deploy.rbにデプロイ内容を設定します。$ vim config/deploy.rb# config valid only for Capistrano 3.1 lock '3.2.1' # AWS SDK for Ruby を読み込む require 'aws-sdk' # AWS SDK用の設定 AWS.config({ :access_key_id => '<AWSアカウントのACCESS KEY ID>', :secret_access_key => '<AWSアカウントのSECRET ACCESS KEY>', :region => 'ap-northeast-1', # EC2 Instanceを作成するリージョン }) # AMIのimage_id # Amazon Linux AMI 2014.03.2 (HVM) set :ami_image_id, 'ami-29dc9228' # 作成するInstance数 set :instance_count, 4 # 作成するInstanceタイプ set :ec2_instance_type, 't2.micro' # 作成先のAvailability Zones set :availability_zones, [ 'ap-northeast-1a', 'ap-northeast-1c' ] # 作成先のsubnet_id set :subnet_ids, [ 'subnet-********', 'subnet-********' ] # Capistranoデフォルトのタスクを削除する framework_tasks = [:starting, :started, :updating, :updated, :publishing, :published, :finishing, :finished] framework_tasks.each do |t| Rake::Task["deploy:#{t}"].clear end Rake::Task[:deploy].clear desc 'Launch an EC2 instance to each availability zone different' task :launch do run_locally do ec2 = AWS::EC2.new created_instances = [] cnt = 0 while cnt < fetch(:instance_count) do if cnt.even? then current_az = fetch(:availability_zones)[0] current_sn = fetch(:subnet_ids)[0] else current_az = fetch(:availability_zones)[1] current_sn = fetch(:subnet_ids)[1] end i = ec2.instances.create( :image_id => fetch(:ami_image_id), :availability_zone => current_az, :subnet => current_sn, :instance_type => fetch(:ec2_instance_type), :count => 1 ) sleep 10 while i.status == :panding created_instances << i.id cnt += 1 end execute "echo -n #{created_instances} > ~/CREATED_INSTANCES" end end desc 'Check the activation status of new instances' task :check do created_instances_list = 'CREATED_INSTANCES' run_locally do ec2 = AWS::EC2.new begin if test "[ -f ~/#{created_instances_list} ]" created_instances = capture("cd ~; cat #{created_instances_list}").chomp ci = created_instances.gsub(/(\[|\s|\])/, '').split(',') target_instances = ec2.instances.select { |i| i.exists? && i.status == :running && ci.include?(i.id) }.map(&:private_ip_address) if target_instances.length == 0 then raise "No created instances" end target_instances.each { |var| server var, user: 'ec2-user', roles: %w{web app} } end rescue => e info e exit end end end task :deploy => :check do run_locally do info roles(:all) info 'Next task of deploy on new instances' # deploy start end end実際にインスタンスのラウンチをしてみる。
AWS認定ソリューションアーキテクト–アソシエイトレベル受験体験記
...おはようございます。インフラの宮下です。
ゴールデンウィーク突入の直前に「AWS 認定ソリューションアーキテクト – アソシエイトレベル」を受験しましたので、
試験の手続き方法や勉強内容について守秘義務に反しない程度にご紹介します。○ 試験の事、そして申込みまで
試験範囲は、Blueprintが公開されていますので正確な情報はそちらを確認してください。
blueprint現時点での出題配分は下記の通りで、Blueprintでは一つ一つ細かく説明がなされています。
時間の限られている社会人は、勉強の基本はBlueprintを見て戦略を練るのが最短距離とい言うのが私の方針です。1.0 Designing highly available, cost efficient, fault tolerant, scalable systems 60%
2.0 Implementation/Deployment 10%
3.0 Data Security 20%
4.0 Troubleshooting 10%Blueprintを一読した印象では、単純にサービスを知っているだけでは厳しそう、という印象でした。
実際に試験を申し込まないと受験できませんので、申込方法を説明します。
AWSのページで案内している通りKryterion社が試験を提供しています。
ここでの注意点は、英語ページのままサインアップすると試験が英語版しか出てきません。
サイトが日本語ページである事を確認してサインアップしましょう。(英語版を希望する時は逆に英語でサインアップする)サインアップ後に「試験のお申し込み」で「AWS 認定ソリューションアーキテクト-アソシエイトレベル」を選択すると 試験会場の選択そして日時の選択になります。
私は、池袋の会場で申し込みました。池袋の地理に明るい自分はすぐに分かりましたが、不慣れな人は
場所はしっかりと確認しておいた方が良いかもしれません。
大塚方面を線路沿いに進み、公園の向かい向かいにあるそんなに大きくないビルの中になります。
試験日程ですが、まだ会場がそれほど多くないせいか直近1週間は結構混んでいます。
1~2週間先をゆとりをもって予約をするのが良いと思います。試験を申し込んだら完了メールが来ますので、印刷して当日は必ず持参しましょう。
結構大事な事がかいてあります。
「受験者認証コード」を提示しないと受験できなかったり、身分証明書を2種類用意するとか○ 試験対策について
CloudFormationを使いredmineのインスタンスを起動する
...おはようございます。インフラの宮下です。
社内向けredmineが古いのでリプレイスを検討しています。
できるだけ手間をかけずに検証環境を用意したいと思い、AWSのcloudformationを使って
redmineを用意してみました。目次
はじめに
現在稼働しているredmine環境が物理サーバにバージョンがRedmine 1.1.2.stable (MySQL)ととても古いので最終的には入替まで実施したいと思います。
CloudFormationでインスタンスを作成する
ManagementConsoleからCloudformationの画面を開きます。
「Create Stack」で新規作成を開始します。・Name→管理しやすい名前を自由につける。
・Template→Use sample templateの中のSingleInstanceSamplesの中から「Redmine Project Management System」を選ぶ。
※検証環境なので今回は最小化された構成で構築します「Next Step」で次に進みます。
Specify Parametersにそれぞれ値を入れていくのですが、デフォルトではkeyを指定する事ができませんでした。
という事で一旦「Back」で戻ります。
amazonが公開している下記のテンプレートをローカルPCに保存します。
https://s3.amazonaws.com/cloudformation-templates-us-east-1/Redmine_Single_Instance.template
サンプルとの違いは、KeyNameの定義が入っているだけですのでSSHログインしないというのであれば
この作業は不要です。[shell](8行目) “KeyName”: { “Description” : “Name of an existing EC2 KeyPair to enable SSH access to the instances”, “Type”: “String”, “MinLength”: “1”, “MaxLength”: “255”, “AllowedPattern” : “[\\x20-\\x7E]*”, “ConstraintDescription” : “can contain only ASCII characters.” },