Capistrano3でタスクが二重起動してしまう時の対処法
...Capistrano3でステージ環境を変えてタスクを実行した時に、タスクが二重起動するという症状に陥った。二重でタスクが実行されるので、ラウンチするAWSインスタンスを“2つ”と設定していても“4つ”起つし、MySQLに発行するクエリも2倍になって、INSERTするレコードが重複して挿入される。一時的にファイルに書き出していた設定なども二重起動している後続タスクによって上書きされてしまい、もうデプロイはしっちゃかめっちゃかな状態だった。 解決できたので、その時の対処法を備忘録として残しておく。
原因はinvoke設定でデフォルトのデプロイ環境を指定していたためだった。
はじめ、試験環境でデプロイタスクの開発を行っていた時、Capfileに下記のような設定を書いていた。
Rake::Task[:develop].invoke invoke :developこれを書いておくと、デフォルトデプロイ環境が
developに固定化されるので、デプロイコマンドを実行するときに本来ならデプロイ環境(ステージ名)を指定して、$ cap develop deploy:task_nameのようにするところを、
$ cap deploy:task_nameと、デプロイ環境を省略できてちょっとだけ楽だったのだが、これがデフォルトデプロイ環境以外にデプロイを行う時に悪影響を及ぼしたのだ。
今回、試験環境でデプロイが上手くいったので、次に本番環境でデプロイを行うことになり、デプロイ環境(ステージ名)を
productionで実行することになった。デプロイ内容は試験環境とまったく同一だったため、デプロイタスク設定の差分はなく、ロール設定やSSH接続設定も同じだったため、config/deploy/develop.rbをコピーしてconfig/deploy/production.rbを作成していた。 この状態で、下記のようにデプロイ環境を指定してデプロイを実行した次第。$ cap production deploy:task_nameこれだと、省略されているデフォルトデプロイ環境へのデプロイも同時に起動してしまうわけです。実際には、
$ cap develop production deploy:task_nameと環境を二つ指定してデプロイを実行しているのと同じことになっているわけです。
この状態を解消するには、前述のinvoke設定を削除するだけです。 というか、複数環境に対してデプロイが発生する時は混乱の元になるんで、invoke設定とかはしない方がいいですね。
いやはや、何気に解決するまで数時間ハマってました。今後は注意しないと。
Capistrano3でEC2インスタンス新規作成から初期設定までのデプロイ(まとめ)
...ここまでAWSのEC2インスタンスを新規作成して、そのインスタンスに対しての初期設定までを、Capistrano3でタスク化することをやって来ました。難儀したものの、ようやくEC2インスタンスの準備が出来て、あとはミドルウェアやアプリケーションをインストールするだけ──というところまでたどり着きました。そこで今回は、これまでのデプロイの流れを一度総括してまとめてみようかと思います。
まず、Capistrano3を稼動させるデプロイサーバの準備から。公式のAmazon Linux環境などのEC2インスタンスをAWSマネージメントコンソール等からラウンチして、ログインしたら、Capistrano3をインストールします1。
# yum update -y # yum groupinstall -y "Development Tools" # openssl version OpenSSL 1.0.1h-fips 5 Jun 2014 # openssl version -d OPENSSLDIR: "/etc/pki/tls" # curl -L https://get.rvm.io | bash -s stable # source /etc/profile.d/rvm.sh # rvm list (※ rvm rubies と表示されればインストール完了) # ruby -v ruby 2.0.0p451 (2014-02-24 revision 45167) [x86_64-linux] # rvm install 2.0.0 -- --with-openssl-dir=/etc/pki/tls # ruby -v ruby 2.0.0p481 (2014-05-08 revision 45883) [x86_64-linux] # gem install rails --no-ri --no-rdoc # gem install capistrano # gem install capistrano_colors # gem install capistrano-ext # gem install railsless-deploy # cap --v (※ cap aborted! ~と表示されればインストール完了) # gem install aws-sdkデプロイサーバにてデプロイプロジェクトを実行するユーザを作成しておきます。デプロイタスクの内容にもよるのですが、対象のユーザはsudo権限を持っていた方が都合が良いかと思います。ユーザを作成したら、そのユーザで再ログインして、ホームディレクトリで、Capistrano3用のプロジェクトを作成します。
Capistranoのタスクを新EC2インスタンスが完全起動するまでsleepさせる
...Capistranoで新規作成したEC2インスタンスが完全に起動し切っていない状態で、そのインスタンスに対してSSHアクセスするタスクを実行すると、どこかしらでエラーになってタスクが完了しません。そこで、デプロイ対象となるEC2インスタンスの起動状態をチェックして、完全に起動していない状態の場合sleepして起動を待つようなタスクを作りました。
AWSのEC2インスタンスには3つのステータス情報があり、この全てのステータスを確認しないと、インスタンスの完全起動状態とは言えないので、注意が必要でした(下図参照)。

インスタンスが起動しているかどうかの確認は、AWSマネージメントコンソールでいうところの「Instance State」が
runningであるかを判定すればOKなのですが、実際にインスタンスにSSH接続ができるかどうかの確認は「Status Checks」欄に「2/2 checks」とあるように2つのステータス(INSTANCESTATUSとSYSTEMSTATUSのreachability)が共にpassedであるかまでを確認する必要があるのです。通常、インスタンスが起動すると「Instance State」は数秒から十数秒程度でrunningになるのですが、「Status Checks」は数分程度initializingで初期化処理を行っています。このステータスが共にpassedにならないとSSHアクセスでコケます。今まで私が使っていた
checkタスクだと、「Instance State」のステータス1つしか確認していなかったので、後続タスクがSSHアクセスで中断したりしていました。それを回避するためのタスクが今回のcheckタスクになります。task :check do run_locally do created_instances_list = 'CREATED_INSTANCES' def check_instance_status(instance_ids=[]) ec2 = AWS::EC2.new AWS.memoize do ec2info = ec2.client.describe_instance_status({'instance_ids' => instance_ids}) sys_status = ec2info.instance_status_set.map { |i| i.system_status.details[0].status } ins_status = ec2info.instance_status_set.map { |i| i.instance_status.details[0].status } status = sys_status + ins_status return status.include?('initializing') ? false : true end end ec2 = AWS::EC2.new begin if test "[ -f ~/#{created_instances_list} ]" created_instances = capture("cd ~; cat #{created_instances_list}").chomp ci = created_instances.gsub(/(\[|\s|\])/, '').split(',') target_instances = ec2.instances.select { |i| i.exists? && i.status == :running && ci.include?(i.id) }.map(&:id) raise "Is not still created all instances" if target_instances.length < fetch(:instance_count) if target_instances.length == fetch(:instance_count) then # 全インスタンス起動(Instance Stateがrunning) chk_retry = 0 while !check_instance_status(target_instances) do # インスタンスステータスが全てOKでない場合は15秒待つ(※20回までリトライする) info "In preparation of the instance: Status check " + (chk_retry > 0 ? "(retry #{chk_retry + 1} times)" : "") sleep 15 if check_instance_status(target_instances) then break end chk_retry += 1 raise "Instance is not still ready. Please run the task again after waiting for a while." if chk_retry >= 20 end # ここからが全インスタンス完全起動後の処理(初回ssh接続設定) target_instance_private_ips = ec2.instances.select { |i| i.exists? && i.status == :running && ci.include?(i.id) }.map(&:private_ip_address) pkfn = fetch(:private_key_file) target_instance_private_ips.each { |var| server var, user: 'ec2-user', roles: %w{web app}, ssh_options: { keys: %W(/home/deploy-user/#{pkfn}), forward_agent: true } } end end rescue => e info e exit end end # 後続タスクのサンプル(SSHしてhostnameを表示する) on roles(:web) do info capture "hostname" end end上記設定から、後続タスクのサンプル部分を削除したタスクを、CapistranoでEC2インスタンスを作成した後のデプロイタスクの直前に挿入してやる感じです。
Capistranoで新規作成したEC2インスタンスの初期設定
...本項では、Capistranoで新規作成したEC2インスタンスへSSHで初回ログインした際の、保守用ユーザの作成、初期ユーザに対してのパスワード設定、サーバのホスト名設定など、いわゆるサーバ環境の初期設定を行うタスクを作ってみます。
その前に、ホスト名のつけ方としての色々と試してみての所感なのですが、初回SSHログイン後にそれぞれのインスタンスに対してHOSTS設定する際にEC2側にタグ付けてしていってもできるのですが、まずインスタンス作成する時にあらかじめホスト名の元となるタグを付けておいて、各インスタンスログイン後はそのタグを参照してHOST名を設定する方がスマートだと思いました。特に複数インスタンスを同時に立てる時などにホスト名に連番を振りたいとかいう時は、カウンター変数を使って回している
ec2.instances.create()時にそのカウンターの数値を転用できるので簡単でした。ということで、インスタンス作成時にタグを追加する方法ですが、# タグ情報 set :host_name, 'deploy-client' ~(中略)~ created_instances = [] cnt = 0 while cnt < fetch(:instance_count) do i = ec2.instances.create( ~(中略)~ ) sleep 10 while i.status == :panding i.tags['Name'] = [ fetch(:host_name), format("%02d", cnt+1) ].join('-') created_instances << i.id cnt += 1 end ~(省略)~── と、
ec2.instances.create()の後でタグを付けてやればOKです1。 今回はこのNameタグの値をその後のタスクでインスタンスのホスト名として利用します。いきなり横道に逸れましたが、本題に戻ります。 初回SSH時のタスクとして、前回作成した
initタスクを使います。流れとしては、デプロイサーバ側で新たに作成するユーザ用のキーペアを作成しておいて、デフォルトユーザにてSSHログイン後、まず保守用の新規ユーザアカウントを作成ます。その後、そのユーザに公開鍵認証によるSSH設定を行い、デフォルトユーザにはパスワードを設定してsudo権限を剥奪、ホスト名を設定して一旦ログアウトしています。 まず、タスク設定前に各種パラメータを定義します。Capistranoで新規作成したEC2インスタンスにSSH接続する
...前回に引き続き、Capistranoで新たに作成したEC2インスタンスにSSHでログインしてみます。
まず、事前準備として、AWS側で新規インスタンス用のキーペアを作成しておきます。AWSマネージメントコンソールの「EC2」メニューから「NETWORK & SECURITY」カテゴリの「Key Pairs」メニューで、キーペアを作成できるので、必要に応じて作成してください。本項の例では、「deploy-test」というCapistranoが稼動しているデプロイ環境用インスタンスで使用しているキーペアを使います。

そして、利用するキーペアのプライベートキーファイル(本項例では
deploy-test.pemファイル)をCapistranoを実行するデプロイ環境のデプロイを実行するユーザのホームディレクトリ(本項例では/home/deploy-user/)にアップロードしておきます1。 アップロードしたプライベートキーには適切な読み込み権限を付与しておく必要があるので、ファイルのパーミッションを変更します。$ cd ~ $ chmod 600 deploy-test.pem $ ls -l *.pem -rw------- 1 deploy-user deploy-user 1692 Jul 2 10:18 deploy-test.pemデプロイ設定ファイル
config/deploy.rbは下記のように修正。# config valid only for Capistrano 3.1 lock '3.2.1' # AWS SDK for Ruby を読み込む require 'aws-sdk' # AWS SDK用の設定 AWS.config({ :access_key_id => '<AWS ACCESS KEY ID>', :secret_access_key => '<AWS SECRET ACCESS KEY>', :region => 'ap-northeast-1', }) # AMIのimage_id # Amazon Linux AMI 2014.03.2 (HVM) set :ami_image_id, 'ami-29dc9228' # 作成するInstance数 set :instance_count, 2 # 作成するInstanceタイプ set :ec2_instance_type, 't2.micro' # 作成先のAvailability Zones set :availability_zones, [ 'ap-northeast-1a', 'ap-northeast-1c' ] # 作成先のsubnet_id(必要に応じて) set :subnet_ids, [ 'subnet-********', 'subnet-********' ] # 使用するキーペア名 set :key_pair_name, 'deploy-test' # プライベートキーファイル set :privert_key_file, 'deploy-test.pem' # 利用するセキュリティグループID set :security_groups, [ 'sg-********', 'sg-********', 'sg-********', 'sg-********' ] # Capistranoデフォルトのタスクを削除する framework_tasks = [:starting, :started, :updating, :updated, :publishing, :published, :finishing, :finished] framework_tasks.each do |t| Rake::Task["deploy:#{t}"].clear end Rake::Task[:deploy].clear desc 'Launch an EC2 instance to each availability zone different' task :launch do run_locally do ec2 = AWS::EC2.new created_instances = [] cnt = 0 while cnt < fetch(:instance_count) do if cnt.even? then current_az = fetch(:availability_zones)[0] current_sn = fetch(:subnet_ids)[0] else current_az = fetch(:availability_zones)[1] current_sn = fetch(:subnet_ids)[1] end i = ec2.instances.create( :image_id => fetch(:ami_image_id), :monitoring_enabled => false, :availability_zone => current_az, :subnet => current_sn, :key_name => fetch(:key_pair_name), :security_group_ids => fetch(:security_groups), :disable_api_termination => true, :instance_type => fetch(:ec2_instance_type), :count => 1, :associate_public_ip_address => true ) sleep 10 while i.status == :panding created_instances << i.id cnt += 1 end execute "echo -n #{created_instances} > ~/CREATED_INSTANCES" end endでは、インスタンスラウンチタスクを実行してみます。
CapistranoでAWS EC2インスタンスをデプロイする時の注意点
...前回のデプロイ設定ファイルで新たに作成されたEC2インスタンスには、キーペアやセキュリティグループなどが設定されていなかったため、そのままでは作成したインスタンスにSSHでアクセスできませんでした…1orz
その後、色々とデプロイ設定を修正して、作成したEC2インスタンスにSSHでログインするところまで出来たので、その経緯を備忘録として書いてみた次第。 まぁ、CapistranoでAWSのEC2インスタンスを作成する際…というより、「AWS SDK for Ruby」でEC2インスタンスを作成する時の注意点…に近いのかもしれない。
まず、前回の
config/deploy.rbからインスタンスラウンチのタスク部分を見てみる。desc 'Launch an EC2 instance to each availability zone different' task :launch do run_locally do ec2 = AWS::EC2.new created_instances = [] cnt = 0 while cnt < fetch(:instance_count) do if cnt.even? then current_az = fetch(:availability_zones)[0] current_sn = fetch(:subnet_ids)[0] else current_az = fetch(:availability_zones)[1] current_sn = fetch(:subnet_ids)[1] end i = ec2.instances.create( :image_id => fetch(:ami_image_id), :availability_zone => current_az, :subnet => current_sn, :instance_type => fetch(:ec2_instance_type), :count => 1 ) sleep 10 while i.status == :panding created_instances << i.id cnt += 1 end execute "echo -n #{created_instances} > ~/CREATED_INSTANCES" end end作成するインスタンスに対して、AvailabilityZoneとSubnetの設定しかしていないので、そりゃあアクセス不能になります。最低限、セキュリティグループを設定して、外部からのアクセス経路を確保して、キーペアを設定して認証ユーザがログイン可能にしてあげる必要はあります。あとは、PublicIP(PublicDNS)を自動で割り振られるようにして、インターネットからのアクセスも出来るようにしておくあたりまでが、最小設定となるかと。
PV InstanceからHVM Instanceへ変換(CentOS6)
...準備するもの
① EC2 Instance(CentOS6)既存の動いているものでもOK ② 変換元のRoot deviceのSnapshot ③ ②から作成したEBS Volume (SSDのほうが作業が早い) ③ 空のEBS Volume (SSDのほうが作業が早い)
DEVICEの確認
# fdisk -l |grep dev Disk /dev/xvda: 10.7 GB, 10737418240 bytes Disk /dev/xvdb: 4289 MB, 4289200128 bytes Disk /dev/xvdf: 10.7 GB, 10737418240 bytes <-PV環境のRoot device Disk /dev/xvdg: 10.7 GB, 10737418240 bytes <-空のEBS Volume作業開始
1.PVのDiskを縮小し、コピー容量を減らす
Capistranoで異なるAvilabilityZoneにEC2インスタンスをラウンチする
...前回、
次回はデータベースの作成や初期設定を直前タスクとして挿入して、さらにWordPressの設定ファイルの書き換え、GitHubからWordPressテーマをダウンロードするところまでやってみようと思います。
とか云っていたのですが、都合によりCapistrano3を使ってAWSのEC2インスタンス作成を行ったので、そのTIPSを残しておこうかと思います。 今回は、デプロイ用のEC2インスタンスから公式のAMIを利用してAvailabilityZonesが異なるエリアにそれぞれEC2インスタンスを立ててみました。試験的に、AMIは最新のインスタンスタイプ「t2.micro」に対応した「Amazon Linux AMI 2014.03.2 (HVM)」を利用して、Tokyoリージョンの1aと1cのAvailabilityZoneにそれぞれ2台ずつ、合計4インスタンスを同時に立ててみます。
※ 事前準備として、インスタンスを立てるAWSアカウントにてVPCやSubnet等EC2インスタンスを作成する上で必要最小限の設定をしておく必要があります。特に今回は異なるAvailabilityZoneへのインスタンスを立てるのでそれぞれのゾーンにSubnetを設定しておく必要があります。
さて、早速デプロイの手順です。 はじめに、デプロイ環境(サーバ)の設定を行うため、
config/deploy/test.rbを編集します。 今回は動的に作成したEC2インスタンスをデプロイ環境とするため、事前のサーバ設定ができません。というのも、AWSで立ち上がる新規インスタンスにはElasticIPを付与しないので、毎回PublicIPが異なり、エンドポイントURLも動的に変わってしまうためです。なので、今回はインスタンスが起動した後にCapistoranoのタスクにて対象サーバを設定するようにします。 初期のサーバ設定は不要となるので、記述をコメントアウトしておきます。なお、SSHのオプションだけは最終的に共通で利用する予定なので残しておきます(今回のデプロイタスクでは使いませんが…)。$ vim config/deploy/test.rb#role :app, %w{deploy@localhost} #role :web, %w{deploy@localhost} #role :db, %w{deploy@localhost} set :ssh_options, { keys: %w(/home/deploy/.ssh/id_rsa), forward_agent: true, }今回のデプロイでは、「AWS SDK for Ruby」を利用するので、あらかじめSDKをインストールしておきます。
$ sudo gem install aws-sdk次に、
config/deploy.rbにデプロイ内容を設定します。$ vim config/deploy.rb# config valid only for Capistrano 3.1 lock '3.2.1' # AWS SDK for Ruby を読み込む require 'aws-sdk' # AWS SDK用の設定 AWS.config({ :access_key_id => '<AWSアカウントのACCESS KEY ID>', :secret_access_key => '<AWSアカウントのSECRET ACCESS KEY>', :region => 'ap-northeast-1', # EC2 Instanceを作成するリージョン }) # AMIのimage_id # Amazon Linux AMI 2014.03.2 (HVM) set :ami_image_id, 'ami-29dc9228' # 作成するInstance数 set :instance_count, 4 # 作成するInstanceタイプ set :ec2_instance_type, 't2.micro' # 作成先のAvailability Zones set :availability_zones, [ 'ap-northeast-1a', 'ap-northeast-1c' ] # 作成先のsubnet_id set :subnet_ids, [ 'subnet-********', 'subnet-********' ] # Capistranoデフォルトのタスクを削除する framework_tasks = [:starting, :started, :updating, :updated, :publishing, :published, :finishing, :finished] framework_tasks.each do |t| Rake::Task["deploy:#{t}"].clear end Rake::Task[:deploy].clear desc 'Launch an EC2 instance to each availability zone different' task :launch do run_locally do ec2 = AWS::EC2.new created_instances = [] cnt = 0 while cnt < fetch(:instance_count) do if cnt.even? then current_az = fetch(:availability_zones)[0] current_sn = fetch(:subnet_ids)[0] else current_az = fetch(:availability_zones)[1] current_sn = fetch(:subnet_ids)[1] end i = ec2.instances.create( :image_id => fetch(:ami_image_id), :availability_zone => current_az, :subnet => current_sn, :instance_type => fetch(:ec2_instance_type), :count => 1 ) sleep 10 while i.status == :panding created_instances << i.id cnt += 1 end execute "echo -n #{created_instances} > ~/CREATED_INSTANCES" end end desc 'Check the activation status of new instances' task :check do created_instances_list = 'CREATED_INSTANCES' run_locally do ec2 = AWS::EC2.new begin if test "[ -f ~/#{created_instances_list} ]" created_instances = capture("cd ~; cat #{created_instances_list}").chomp ci = created_instances.gsub(/(\[|\s|\])/, '').split(',') target_instances = ec2.instances.select { |i| i.exists? && i.status == :running && ci.include?(i.id) }.map(&:private_ip_address) if target_instances.length == 0 then raise "No created instances" end target_instances.each { |var| server var, user: 'ec2-user', roles: %w{web app} } end rescue => e info e exit end end end task :deploy => :check do run_locally do info roles(:all) info 'Next task of deploy on new instances' # deploy start end end実際にインスタンスのラウンチをしてみる。
Capistrano3でWordPressのデプロイをしてみる
...Capistrano3を使って、自ホストに最新版のWordPressをデプロイしてみたのでその手順をログとして残しつつ、デプロイツール「Capistrano」の理解を進めていこうと思います。 事前準備として、デプロイ用の環境をAmazonEC2にt2.microインスタンスとしてラウンチして、WordPressが動作する環境(Apache+MySQL+PHP)、Rubygem(とRVM)、そしてCapistrano3のインストールまで出来ている状態で記載しています(この辺の事前準備の手順も後日TIPSとしてまとめたいと思っていますが、今回は省略します)。
さて、早速手順に入ります。 はじめに、デプロイプロジェクト用のディレクトリを作成して、Capistranoをインストールします。
$ cd ~ $ mkdir test-project $ cd test-project $ cap install STAGES=test mkdir -p config/deploy create config/deploy.rb create config/deploy/test.rb mkdir -p lib/capistrano/tasks CapifiedCapistrano3ではマルチステージデプロイ機能がデフォルトでONになっているので、単に
cap installを行っただけだと、productionステージとstagingステージが作成されてしまいます。 今回はテスト用に自分のローカルホストのみを対象にデプロイを試すので、testステージのみのプロジェクトを環境変数STAGESの引数に指定します1。次にCapistranoの初期設定を行います。必要ならば、プロジェクトディレクトリ直下に作成された
Capfileを編集します。$ vim Capfile今回はrvmやrbenvをデプロイに使わないので、編集項目はありません2。
続いて、デプロイ環境(サーバ)の設定を行うため、
config/deploy/test.rbを編集します。$ vim config/deploy/test.rb ---- role :app, %w{deploy@localhost} role :web, %w{deploy@localhost} role :db, %w{deploy@localhost} set :ssh_options, { keys: %w(/home/deploy/.ssh/id_rsa), forward_agent: true, }そして、
config/deploy.rbにデプロイ内容を設定します。Google Glass Word Lens と Play game
...Google Glassレポートその2です。
前回は借り物でしたが、今回は Google Glass Explorer Edition Ver 2.0 を自社で購入してのレビューです。
すごい!代表カッコイイ!!!まず、借りていたver1と今回のver2の違いについて。
ggっても明確な情報は捕まりません。
Google Glass 2 offers minor but important hardware updates
一番よくまとまっていると思われたのが、↑のサイト。
で、その情報によれば
- イヤホンが付いてくる
Glassはメガネのツルにあたる部分に骨伝導スピーカーが付いています。
大体はこれで事足りると思うのですが、聞こえない場合の手段が追加された形だと思います。
より万人向けに。素晴らしいことです。- 処理速度10%向上
ほんの少しですがパフォーマンスが向上している模様。
イイネ!
ちなみに重たいアプリを動かしていると熱くなり使用を控えるようメッセージが出るのは変わりませんでした。
残念…続いて前回おざなりなレビューをした2つのアプリの使い方について

OK glass が表示されている状態で、Glassの右こめかみのあたりをタップ。
インストールされているアプリを切り替えられる状態になります。
メガネのツルの部分を左右にスワイプし目的のアプリを探します。
Word Lensを見つけたら、すかさずタップ。Google Glass ファーストインプレッション
...噂のGoogle Glass。USでは既にかなり楽に入手できるようになっています。
んが、日本では買えません。なぜ買えないんだぁー!
リスクのある並行輸入業者に頼めということでしょうか。
いや、無理です。(Glassのお値段的に)でも、持っている人は持っているんですよねぇ。
Early Adopterな方々との情報格差がまた広がる…そんな絶望感を抱えながら、我社の代表にダメ元で相談したところ、期間限定ではありますが、Glassをお知り合いの方から借りてくれるとのこと!
ありがとうございます!さすがです!!そんなこんなで触らせて頂いたGoogle Glassの感想です。
120%私見です。ご容赦下さい。さて、メガネ型のウェラブルデバイスといえば、どうしても期待してしまうのがAR。
拡張現実ではないでしょうか。
↑こんなの。
現実を上書きし、世界の有り様を拡張してしまう….サイバー!!(鼻血ブー
Google Glassはどこまでそんな世界を引き寄せてくれるのでしょうか?
ワクワクしながら、試してみました。結果:
Google Glassは ARを実現するツールではない。まあ、ある程度分かっていた事ではあるのですが、Glassは視界の右上に小さなディスプレイを追加するものです。
決して存在しないものをあたかも存在するかのように感じさせてくれるデバイスではありません。
ただ、それでもなお、この製品が市場に受け入れられ順調に成長を続けていけば、いずれは万人が思い浮かべるARの世界を実現するようなデバイスにたどり着くかもしれない…そんな可能性は感じました。このデバイスの可能性を試すには、アプリを追加する必要があります。
ところがアプリを追加するために必要なAndroidアプリ、MyGlassは日本からはダウンロードできません。
なってこった。しょうがないので野良アプリをインストールします。
私は以下からダウンロードしました。あくまで自己責任でお願いします。
アプリを起動しBluetoothでペアリングすれば準備完了。
ワシワシアプリをインストールしましょう。私がインストールしたアプリの中で特に気になったのは以下の2つです。
首の動きで操作するのが新しい!そして若干ARぽい。
見たものを翻訳できる!
これは…未来ぽい!WordPressのサイトが重くなった時のプラグインパフォーマンス検証
...とある多国語サイトをWordPressで構築している時に、結合試験もほぼ終わったあたりで、構築サイト全体のパフォーマンス・チューニングをしていた時の備忘録です。
対象のサイトは規模がそんなに大きくなかったので、AWSのm3.mediumのインスタンスに構築していたのだが、開発途中からサイト全体のパフォーマンスが落ちて、だいぶ重いサイトになって来てました。サイトのパフォーマンス検証「GTmetrix」でのレポートを見ると、サイト内で利用している画像のレスポンスがレイテンシー食っているという結果しか出ず、とりあえずは出来る限りの画像最適化を行って、フロントエンドのパフォーマンスはだいぶ良くなったのだが、WordPressの管理画面は重いまま変わらなかった。WEBサーバ側で静的コンテンツのGZIP圧縮や、.htaccessを利用せずにhttpd.conf内に設定を移行など、諸々対応してみたが効果はなかった。他にMySQLTunerでDBの設定を検証・チューニングしてみたが、特に変化なし。
う~む、CloudWatchを見るとCPU使用量がやけに大きいので、AWSインスタンスの非力さが原因なのかも…そうなると、最終的にはm3.mediumインスタンスからc3系へのインスタンス変更が必要かも知れないなぁ…とか考えていたのだが、そもそも開発中のサイトで社内の数人しかアクセスしない管理画面が重いというのは根本的に別の要因があるはず。サイト全体に関わるものというと、テーマかプラグインかしかない。そこで、導入しているプラグインのパフォーマンス検証を行ってみたところ、ビンゴ!…パフォーマンス低下の原因はプラグインだった。今回プラグインのパフォーマンス検証に利用したのが「P3(Plugin Performance Profiler)」だ。プラグインのパフォーマンスを検証するのに別のプラグインを入れるというのも変な話だが、このP3プラグインはWordPressサイト内でのプラグインやテーマのパフォーマンスを細かいところまでスキャン・レポーティングしてくれるかなり優秀なものだ。導入も簡単で、プラグインをダウンロードして有効化すればいつでも管理メニューの「ツール」からパフォーマンススキャンができる。
このP3プラグインでスキャンした結果はこうなった。
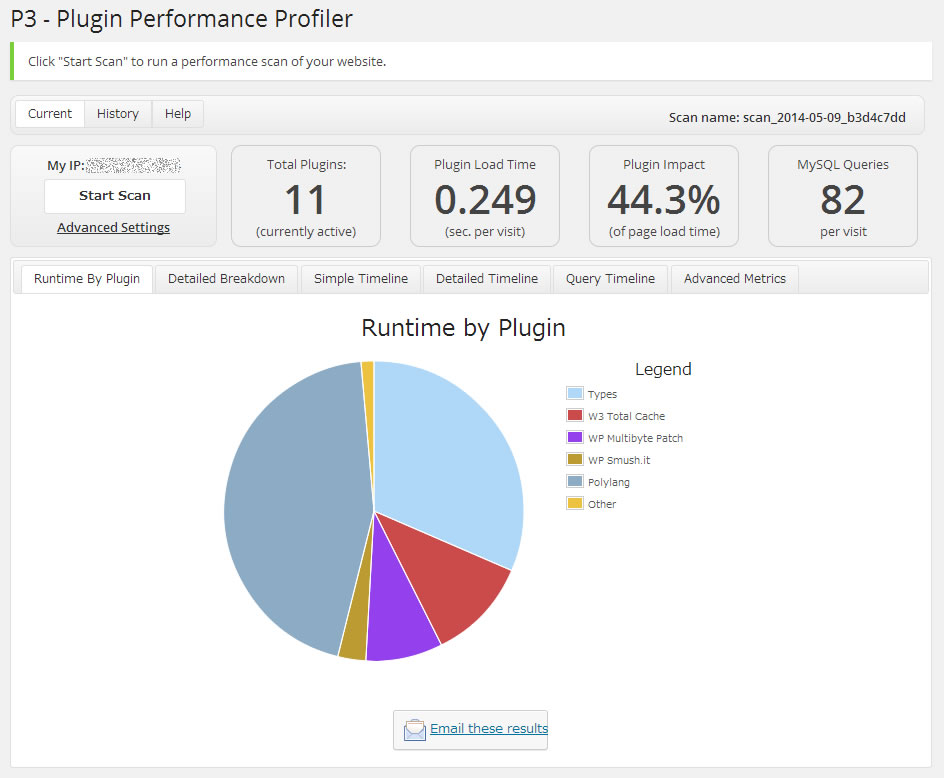
多言語化プラグインの「Polylang」とカスタム投稿タイプ系プラグインの「Types」がランタイムを圧迫しているのがわかる。さすがに多言語サイトなので「Polylang」は外せないが、カスタム投稿タイプ系のプラグインは同系プラグインが多いので差し替え可能だ。「Types」は「Polylang」に公式対応しているプラグインなので採用していたのだが、たかだかカスタム投稿の拡張をするだけで、ここまでランタイムを占有されてはちょっと使い勝手が良いとは言えない。
そこで、「Types」プラグインを外して、同系で使い慣れている「Custom PostType UI」プラグインを導入してみた。
「Types」で占有されていたランタイムがなくなり、プラグインロードタイムやプラグインインパクトが改善された。管理画面の体感速度も数十倍に向上し、本来のサクサク編集できるUXが復活した。プラグイン一つでここまでパフォーマンスが変わるものなんだなぁ…と実感できました。
今回の件から、今後WordPressサイトを作る際には、プラグインの機能よりもパフォーマンスを重視して選定した方が良いと私的には思えました。なぜなら、プラグインの機能で足りないものは後からいくらでも追加することができるが、プラグインのコアに依存するパフォーマンスを改修するのは非常に困難だからです。
特に管理画面が重いと、サイトを運用するWEB担当者のモチベーションがかなり下がってしまうので、ちょっと機能不足でもストレスなく運用できる管理画面の方が喜ばれるのではないだろうか。AWS認定ソリューションアーキテクト–アソシエイトレベル受験体験記
...おはようございます。インフラの宮下です。
ゴールデンウィーク突入の直前に「AWS 認定ソリューションアーキテクト – アソシエイトレベル」を受験しましたので、
試験の手続き方法や勉強内容について守秘義務に反しない程度にご紹介します。○ 試験の事、そして申込みまで
試験範囲は、Blueprintが公開されていますので正確な情報はそちらを確認してください。
blueprint現時点での出題配分は下記の通りで、Blueprintでは一つ一つ細かく説明がなされています。
時間の限られている社会人は、勉強の基本はBlueprintを見て戦略を練るのが最短距離とい言うのが私の方針です。1.0 Designing highly available, cost efficient, fault tolerant, scalable systems 60%
2.0 Implementation/Deployment 10%
3.0 Data Security 20%
4.0 Troubleshooting 10%Blueprintを一読した印象では、単純にサービスを知っているだけでは厳しそう、という印象でした。
実際に試験を申し込まないと受験できませんので、申込方法を説明します。
AWSのページで案内している通りKryterion社が試験を提供しています。
ここでの注意点は、英語ページのままサインアップすると試験が英語版しか出てきません。
サイトが日本語ページである事を確認してサインアップしましょう。(英語版を希望する時は逆に英語でサインアップする)サインアップ後に「試験のお申し込み」で「AWS 認定ソリューションアーキテクト-アソシエイトレベル」を選択すると 試験会場の選択そして日時の選択になります。
私は、池袋の会場で申し込みました。池袋の地理に明るい自分はすぐに分かりましたが、不慣れな人は
場所はしっかりと確認しておいた方が良いかもしれません。
大塚方面を線路沿いに進み、公園の向かい向かいにあるそんなに大きくないビルの中になります。
試験日程ですが、まだ会場がそれほど多くないせいか直近1週間は結構混んでいます。
1~2週間先をゆとりをもって予約をするのが良いと思います。試験を申し込んだら完了メールが来ますので、印刷して当日は必ず持参しましょう。
結構大事な事がかいてあります。
「受験者認証コード」を提示しないと受験できなかったり、身分証明書を2種類用意するとか○ 試験対策について
nginxでヘルスチェックのアクセスログを出力させない設定
...おはようございます。インフラの宮下です。
今回はnginxのログ関連の設定になります。目次
はじめに
apacheで良く実施する、setenvの定義を利用して特定NWから来るログを出力しないような設定をnginxでも実施したかったのですが同じ機能が無かったので調べてみました。 使い道としては、ロードバランサーのヘルスチェックや監視サーバからの接続など、ログに出力しない方が都合が良い時に利用できます。 解析するには不要ですし、余計なDISK I/Oも抑えられます。
ngx_http_geo_moduleとは
ドキュメントの通りIPアドレスを変数としてセットできます。
一般的に使われるのは、特定の国のNWは接続拒否するような時にこのモジュールを使う事が多いようです。 そのような場合は、includeして大量に登録された別ファイルで管理する事も可能です。nginxへの設定
nginx.confに設定します。
[shell]# vi nginx.conf http { include mime.types; (中略) # not access_log IP’s geo $no_log { default 0; 172.0.1.0/24 1; } server { (中略) location / { root /var/www/html; index index.cgi index.php index.html index.htm; if ($no_log) { access_log off; } } }[/shell]



