source treeを使ってgitlabを触ってみる(2)
...おはようございます。インフラ宮下です。
前回source treeのインストールと鍵の登録までを説明しましたので、今回はgitlabとの接続について説明します。 社内にgitlabがあるのでgitlabとの接続が前提となります。 (もちろんgitlabのアカウントもある想定)
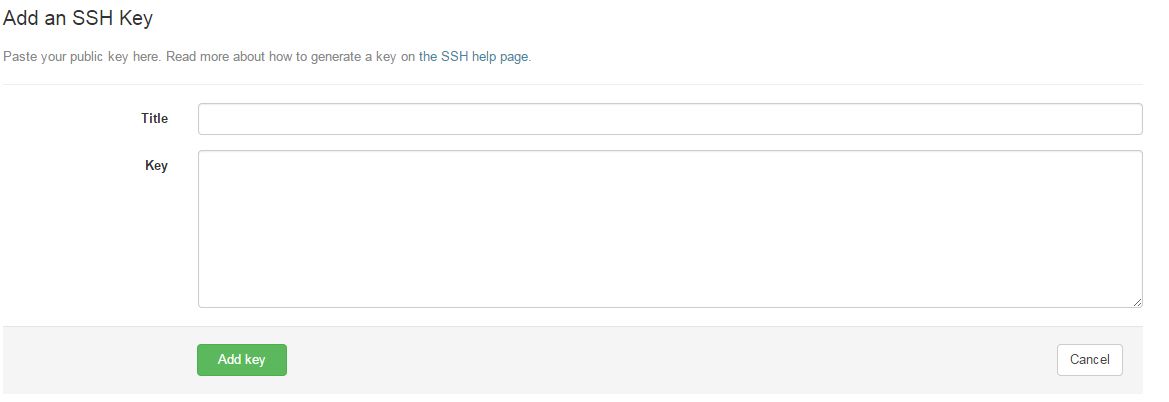
gitlabの自分profile画面のメニューで「SSH keys」を選択します。
既に登録されている鍵の一覧が確認できます。右上にある「Add SSH key」をっクリックします。

鍵登録の画面に移ったら、Titleに識別し易い名前を(入力しないと自動生成されます)入れて、Keyの所に前回作成した公開鍵を貼り付けたら「Add key」で登録します。
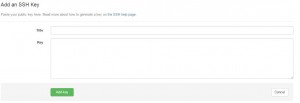
登録keyの一覧に表示されたら無事登録は完了です。
再びsource treeに戻ります。
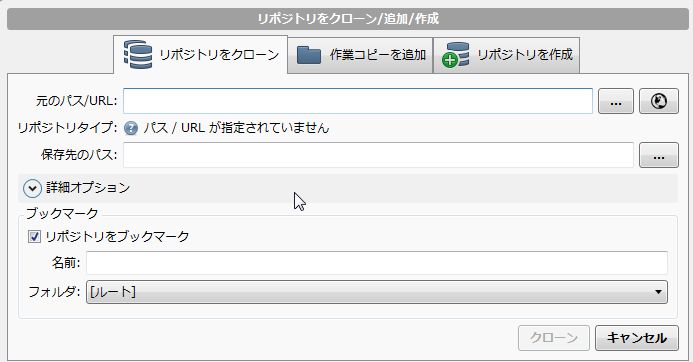
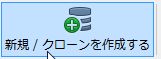
ではgitlabのリポジトリをcloneします。「新規/クローンを作成する」で開始します。
今回は、gitlabのリポジトリを使いますので、「リポジトリをクローン」タブを選択して、 ・元のパス/URLにgitlabの接続先情報を入れます。 (例:http://192.168.0.250/infra/projectX.git) 社内gitlabはhttpでの接続が出来ますが、gitであったりsshでも接続出来る方法なら何でも大丈夫です。 入力したら自動で接続確認が行われて接続成功・失敗が確認出来ます。 ・保存先のパスにクローンしたデータの保存先を指定します。 ・リポジトリをブックマークはそのまま選択状態にしておきます。 ・名前はsourcetree上で表示される名前なので、どのリポジトリかわかるような名前を付けておいてください。
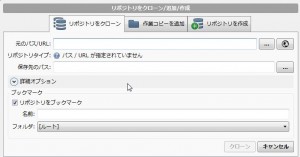
必要事項を入力したら「クローン」でスタートです。
データ量によりますが、しばらく待つと保存先のパスにクローンが完了します。

無事登録されました。これでsourcetreeからgitライフが可能となります。
基本的な作業として、pushするまではこんな感じです。 PC側でファイルの修正をすると変更アイコンに変わりますので「追加」をクリックするかファイルの所をクリックします。

初心者向けGoogle Analyticsの基本的な使い方[第一回]
...こんにちは。フロントエンド担当の鴫原(シギハラ)です。
「Google Analytics導入したけど、どうやって解析したらいいかわからない!」という初心者の方向けに、全5回にわけてGoogle Analyticsの基本的な使い方についてお話をしたいと思います。今日は第1回目となります。
<目次>
Google Analyticsとは
Googleが提供している無料のアクセス解析ツールのことです。 「1日に何人くらいの人がうちのサイトに来ているか」「始めにどのページを見たのか」「どんな検索ワードでサイトに来ているか」など自身のwebサイトの現状を知ることで、強みや改善点を分析することができます。 何かしら目的のあるwebサイトには必ず導入したほうがいいツールです。
Google Analyticsの導入
1. Google Analyticsの導入手順
導入は以下の3STEPで簡単に登録することができます!
- Google Analyticsの公式サイト(http://www.google.com/intl/ja_ALL/analytics/index.html)にアクセスし、必要な情報を入力します。
- 登録後、コードが発行されるのでコピーをします。
- コピーしたコードをサイト内の全ページに貼り付けます。※設置場所はの直前(Google推奨)。

2. Google Analyticsの導入時に一緒に設定すべき3つのこと!
導入時に以下の3つも一緒に設定しておくと便利です。
- Googleウェブマスターツールと連携すること →通常Google Analyticsでは取得できないデータが取得できるようになります。
- 自分や関係者のアクセスを除外すること →関係者のアクセスを除外しないと真のデータが見れません!
- コードに「ga(‘require’, ‘displayfeatures’);」を追記すること →ユーザー属性(性別、年齢、興味)を取得できるようになります。
▼参考記事 ・必ず設定したい!Googleアナリティクスを導入したら最初に行うべき基本設定 http://creive.me/archives/5393/ ・最初に設定しないと絶対損する!Google Analytics 9個の必須設定&解説 http://www.find-job.net/startup/analytics-setting ・Google Analyticsでユーザーの分布レポートを有効化する手順 http://techmemo.biz/web-cheat-sheet/google-analytics-user-distribution/
まとめ
今回はGoogle Analyticsとは?からGoogle Analyticsの導入について説明をさせていただきました。 第2回からは基本的な使用方法や用語についてお話できればと思います。 最後までお付き合いいただきありがとうございました!
bashのhistoryをsyslog出力、jenkinsでビルド
...こんにちは。小宮です。 セキュリティ関連のお仕事で「実行コマンドを記録したい」という要望が最近多くなってきました。 何種類か方法はあると思いますが、今回はbash_historyに時刻を入れて一つのログにまとめてみたいと思います。
これやったあと便利に感じたのはメンテナンスの時作業時刻を報告する場合にログをgrepで解決可能というところです。
jenkinsでビルドするのは、最近はやりの継続的インテグレーションということでやってみました。 最初は心理的な障壁があったんですがやってみると結構楽で手順のもれがないので良いと思いました。 脆弱性の対応で何回かビルドすることになりましたがjenkinsジョブになってるのは便利でした。
CentOS6.5です。 jenkinsさんのジョブは以下のとおりです。 単にパラメータつきのシェルの実行です。
#!/bin/bash topdir="${HOME}/rpmbuild" rpmdir="${topdir}/RPMS/x86_64" if [ -f ${HOME}/.rpmmacros ];then echo "%_topdir ${topdir}" > "${HOME}/.rpmmacros" echo "%_signature gpg" >> "${HOME}/.rpmmacros" echo "%_gpg_name D279xxxx" >> "${HOME}/.rpmmacros" fi if [ -d ${HOME}/rpmbuild ];then mv ${HOME}/rpmbuild{,.`date +%Y%m%d.%H%M`} mkdir -p ${HOME}/rpmbuild/SRPM fi case "${TARGET}" in *.src.rpm) rpm -Uvh "${TARGET}" cp -p ${topdir}/SPECS/bash.spec{,.org} sed -i 's/make "CFLAGS=$CFLAGS -fwrapv" "CPPFLAGS=-D_GNU_SOURCE -DRECYCLES_PIDS `getconf LFS_CFLAGS`"/make "CFLAGS=$CFLAGS -fwrapv" "CPPFLAGS=-D_GNU_SOURCE -DRECYCLES_PIDS `getconf LFS_CFLAGS` -DSYSLOG_HISTORY"/g' ${topdir}/SPECS/bash.spec sed -i 's/Release: 29%{?dist}/Release: 29%{?dist}_isao_5/g' ${topdir}/SPECS/bash.spec sed -i '108s/^$/\n/g' ${topdir}/SPECS/bash.spec sed -i '109s/^$/Patch145: bash-syslog_facirity.patch\n/g' ${topdir}/SPECS/bash.spec sed -i '181s/^$/%patch145 -p1\n/g' ${topdir}/SPECS/bash.spec cd ${HOME}/rpmbuild/SOURCES/ tar xzf bash-4.1.tar.gz cp -rp bash-4.1{,.org} sed -i 's/# define SYSLOG_FACILITY LOG_USER/# define SYSLOG_FACILITY LOG_LOCAL6/g' ${HOME}/rpmbuild/SOURCES/bash-4.1/config-top.h sed -i 's!(SYSLOG_FACILITY|SYSLOG_LEVEL, "HISTORY: PID=%d UID=%d %s", getpid(), current_user.uid, line)!(SYSLOG_FACILITY|SYSLOG_LEVEL, "HISTORY: PID=%d PPID=%d SID=%d User=%s UID=%d CMD=%s", getpid(), getppid(), getsid(getpid()), current_user.user_name, current_user.uid, line)!g' ${HOME}/rpmbuild/SOURCES/bash-4.1/bashhist.c sed -i 's!(SYSLOG_FACILITY|SYSLOG_LEVEL, "HISTORY (TRUNCATED): PID=%d UID=%d %s", getpid(), current_user.uid, trunc)!(SYSLOG_FACILITY|SYSLOG_LEVEL, "HISTORY (TRUNCATED): PID=%d PPID=%d SID=%d User=%s UID=%d CMD=%s", getpid(), getppid(), getsid(getpid()), current_user.user_name, current_user.uid, trunc)!g' ${HOME}/rpmbuild/SOURCES/bash-4.1/bashhist.c diff -crN bash-4.1.org bash-4.1 > ${HOME}/rpmbuild/SOURCES/bash-syslog_facirity.patch rpmbuild -ba ${topdir}/SPECS/bash.spec ;; *) echo 'environment variable TARGET must be set.'; exit 1;; esacTARGETにしたパラメータは以下です。
http://vault.centos.org/6.5/updates/Source/SPackages/bash-4.1.2-15.el6_5.2.src.rpmAWSとVPN接続したら応答が無くなる時の対応
...おはようございます。インフラ宮下です。
AWSのVPCとオフィスをVPNで接続するケースは良くありますが、構成によってはダウンロードしたconfigではうまく動作しない事があります。 今回は、以下の環境の時に変更しなければいけなかった設定をまとめたいと思います。
1)AWSの接続環境
[shell]リージョン:シンガポール ルータ:YAMAHA RTX 1200 経路情報:Static[/shell]
2)VPNのconfigを確認
VPN Connectionsを作成した後にconfigをダウンロードすると設定項目として、IKE・IPSec・Tunnel Interface・Static Route の4項目がありますのでそれぞれの内容について確認しましょう。
・IKE
[shell] tunnel select 1 ipsec ike encryption 1 aes-cbc ipsec ike group 1 modp1024 ipsec ike hash 1 sha ipsec ike pre-shared-key 1 text y7Nn93e7fJHWQrUaabbccdd112233[/shell]
IKEについては、configそのまま流用で問題ないでしょう。keyは個々に違いますので正しいKeyにしてください。 トンネル番号は、既に「1」を使っている場合は違う数字にしてください。(以降のID表記も忘れずに変える)
・IPSec
[shell] ipsec tunnel 201 ipsec sa policy 201 1 esp aes-cbc sha-hmac ipsec ike duration ipsec-sa 1 3600 ipsec ike pfs 1 on ipsec tunnel outer df-bit clear ipsec ike keepalive use 1 on dpd 10 3[/shell]
opsだけどgitを使ってみた~その1
...こんにちは。小宮です。 opsだけどgitを使ってみた~その1ということで、githubもgitlabもgitも初心者なので忘れないようにメモ。 今回はたどたどしくpushするところくらいまでにします。branch切ってみるとこは初回から書くとおなかいっぱいになりそうなので。 たぶんその2までです。その2はbranchとtagとconfrictのことを書いています。
背景とメリットデメリット
・背景 昨今の継続的インテグレーションだとかでchefでサーバ構築の需要があってその流れ弾に当たった機会を得たため、 そのリポジトリをバージョン管理する必要が生じましてgitをつかうことに。最初は会社のエンタープライズ版のgithubに保存してもらっていたんですが、 VPN経由でのやり取りの需要からgitlabの導入を行うことになりました。 ・gitのメリット ヒストリ追わなくていい。見える化。ファイル内の差分が見やすいので確認がブラウザで容易に可能になる ・gitのデメリット 同僚がつかいはじめてくれない(必要にせまられないと忙しくてスルー傾向) まあなんか気持ちはわかります。私もきっかけは半ば強制的な感じでした。
githubとgitlabの違い gitコマンド的にはあんま変わんない気もしますが、制度がオープン(エンタープライズはクローズ可)かクローズでいけるか、 gilabの場合は容量制限もディスク容量とかの環境次第でユーザ権限を細かく設定できたりなどするのがいい感じです。 もっというとVPN越しにしかつながらないようにしたいとかの自由がききます。共有Webサービスつかうか自前構築のつかうかの差です。 gilab導入の手間は最近はchefで気軽に入るレシピもあり軽減されてきたようです。
githubの場合、二段階認証をなんとかする
詳細な説明は省きますが、まずgithubに登録して会社のgithubの二段階認証をなんとかします →会社で用意していただいたマニュアルのとおりに実施。 要はgmailの2段階認証みたいなことで携帯にSMS通知が届いて認証する仕組みのセットアップです。
接続するホストでsshの鍵の作成と、作成した公開鍵の登録をgithub側のユーザプロファイルで行います。
pushするホストでgitを初期設定する
まずgitコマンド打つ人のユーザ情報を登録です。
git config --global user.email "komiyay@xxxxx"` git config --global user.name "Yxxx Komiya"設定ファイルにメモリ制限やスレッド数を指定しないとOutOfMemoryエラーが出ます。
$ vi ~/.gitconfig [user] email = komiyay@xxxxx name = Yxxx Komiya [core] packedGitWindowSize = 128m packedGitLimit = 128m [pack] windowMemory = 128m threads = 2 deltaCacheSize = 128m packSizeLimit = 128m※m1.smallくらいでこの設定にしました。t1.microだとメモリエラー出ました。
超絶簡単で便利なVagrantを使ってみよう!
...こんにちは。デベロッパーの平形です。
はじめに
この記事ではVagrantの使い方を解説します。 なお、この記事は連載の続きになりますので、まだご覧になっていない方は、以下の記事を初めに読む事をおすすめします。 DevOps時代のアジャイルでスケーラブルな開発環境をVagrant,GitHub,Travis,Chef,OpsWorksで構築する
Vagrantとは?
Vagrant(ベイグラント)は、FLOSSの仮想開発環境構築ソフトウェア[1]。VirtualBoxをはじめとする仮想化ソフトウェアやChef(英語版)やSalt(英語版)、Puppetといった構成管理ソフトウェアのラッパーとみなすこともできる。 Vagrantを用いると、構成情報を記述した設定ファイルを元に、仮想環境の構築から設定までを自動的に行うことができる[2]。当初はVirtualBoxをターゲットとしていたが、1.1以降のバージョンではVMwareなどの他の仮想化ソフトウェアやAmazon EC2のようなサーバー環境も対象とできるようになった[3]。Vagrant自身はRubyで作成されているが、PHPやPython、Java、C#、JavaScriptといった、他のプログラミング言語の開発においても用いることができる[4][5]。 引用元:wiki
なぜVagrantなの?
まず現状の課題からお話します。 こんな事ってありませんか?
- 開発者のPCのOSがバラバラで環境構築の手順書作るのめんどくさい。
- てかWindowsの事なんか考えたくもないよ。
- ハンズオンの時にみんなの環境が違うから、みんな挙動が違って嫌になる。
Vagrantを使うとこんな事ができます。
- コードによる仮想マシンのOS指定、ネットワーク設定、利用するシステムリソースの指定。
- Chefなどの構成管理ツールを利用して環境構築する事ができる。
以下のメリットがあります。
- 複数の開発者に共通の開発環境を配布できる。
- 仮想マシンの設定が1つのファイルで管理する事ができるので、認識しやすい。
- WindowsでもMacでもLinuxでも共通の開発環境を提供できる。
vagrant使うのって面倒だと思いますか? めちゃくちゃ簡単です! まだ使ったことない人は、とりあえずインストールしてください!
インストール
VirtualBox
VagrantではVirtualBoxなどの仮想化ソフトウェアを使って仮想マシンを立ち上げる事になります。 今回はVirtualBoxを利用します。
ここからダウンロードしてインストール。
Vagrant
ここからダウンロードしてインストール。
クイックスタート
OSはubuntu 12.04(32bit)にします。
まず作業場所のディレクトリを作ります。
$ mkdir vagrant_test $ cd vagrant_test次にVagrant用の設定ファイルを作成します。
$ vim Vagrantfile以下を
Vagrantfileに貼り付けてください。# -*- mode: ruby -*- # vi: set ft=ruby : Vagrant.configure("2") do |config| config.vm.box = "hashicorp/precise32" end仮想マシンを起動します。
remotediff
...各環境間での /etc/hosts をdiffする場合のmemo
Cloud上でサーバを大量に作成したあと、confの比較チェックするときなどに。
・ローカル同士(/etc/hosts.backupと比較)
$ diff /etc/hosts /etc/hosts.backup・ローカル<->リモート(xxx-web01)
$ diff /etc/hosts <(ssh xxx-web01 cat /etc/hosts)・リモート(xxx-web01) <-> リモート(xxx-web02)
$ diff <(ssh xxx-web01 cat /etc/hosts) <(ssh xxx-web02 cat /etc/hosts)・ローカル<->リモートで復数サーバ(xxx-web01~10)
$ for SRV in xxx-web0{1..9} xxx-web10 > do > echo ${SRV} > diff /etc/hosts <(ssh ${SRV} cat /etc/hosts) > donesource treeを使ってgitlabを触ってみる(1)
...おはようございます。インフラの宮下です。
社内で稼働中のgitlabがあるのですが、CLI使える人が少ないせいかgitしている人が思った以上に少ないのに困ってます。 最近はWindowsのツールでも充分にGitの体験が出来るようですので、今回は「SourceTree」を紹介したいと思います。 アンチCLIの方は「SourceTree」でも十分git操作可能ですのでまず手始めに利用してみては如何でしょうか。
そもそもGitの意味がわからないという人はごめんなさい。いずれgitの構築も誰かが書いてくれると思いますので今回は割愛します。 git知識としてはとってもわかりやすい下記サイトをご覧ください。
分散型バージョン管理システムなので、みんなで使ってたまにはデグレしたりと苦い経験をしておいた方が良いと思ってます。 バックアップとかしっかりしておけば傷は浅く済むと思います… chefと連携しても良いと思いますし、configを管理してバージョンや差分を管理するでも良いですし、単にreadme的な手順を管理するでも何でも用途は良いと思います。
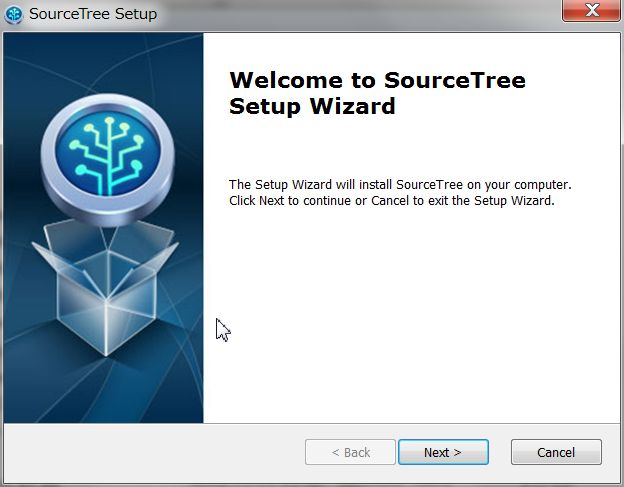
1)SourceTreeをインストールする
Source tree公式サイトから今回はwindows7版のファイルをDownloadします。

ダウンロードした実行ファイル「SourceTreeSetup_1.6.13.exe」をダブルクリックしてインストールを開始します。
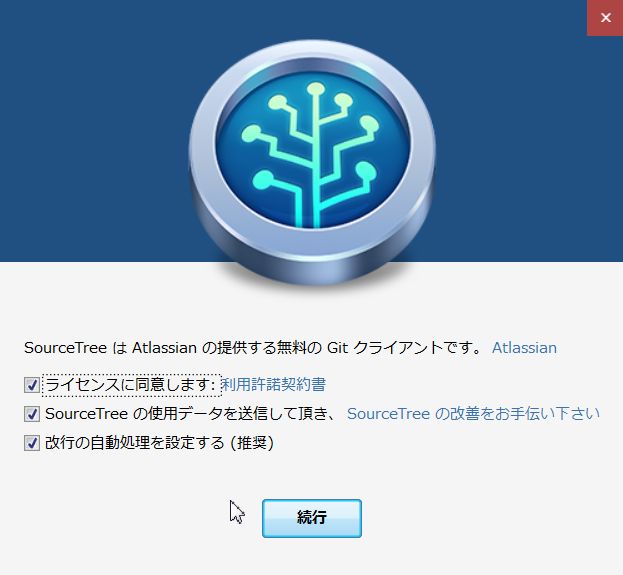
ほぼ流れにのってインストールするだけで終わります。
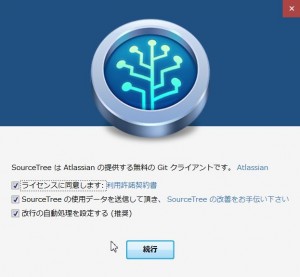
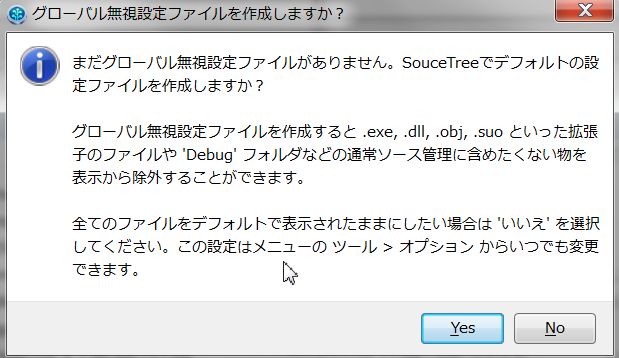
「グローバル無視設定ファイル」の作成を聞かれますが「Yes」「No」今の所どちらでも良いです。 今回は「Yes」にして進みます。
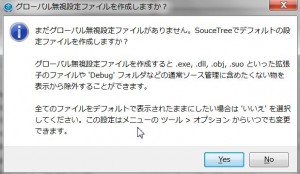
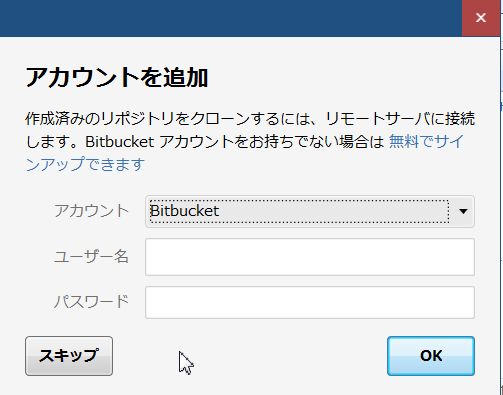
publicのリポジトリ設定をすると接続する事が出来ます。アカウントがあればアカウント・ユーザ名・パスワードを入力してください。 今回の用途は自社内のgitlabとの接続なので「スキップ」します。
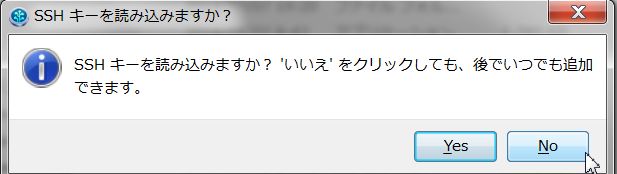
最後にSSHキーの読み込みをするか聞かれます。既に持っている場合は登録しても良いですが後でも出来るので「No」としておきます。
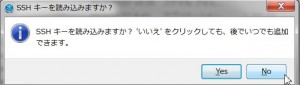
2)SSH鍵を作成して登録
gitlabにつなぐ為に作業PCの鍵を登録します。
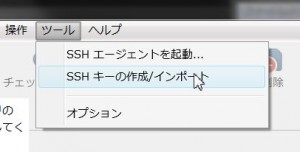
SourceTreeを起動してまずはSSH鍵の作成と登録を行います。 既に作成した鍵がある場合はあえて作成する必要はありません。
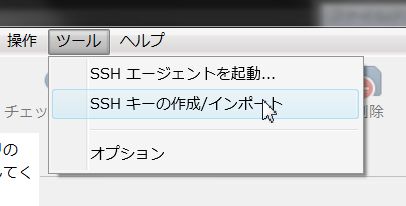
「ツール」→「SSHキーの作成/インポート」でPuttyKeyGeneratorを起動します。
「Generate」をクリックしたらマウスをたくさん動かしていると鍵の作成が完了します。
innodb_stats_on_metadata=1でディスク容量激増とCPU負荷が発生
...こんにちは。小宮です。 ある日chefのレシピをなおしていると、同僚がこんなことをいってきました。
「おきゃくさまがphpmyadminのinformation_schemaのリンクをクリックしたとたんに サイトが重くなってディスク容量が数十GBも増えて今下がって落ち着いたって言ってます。 なにか原因わかりますか?」phpmyadminでinformation_schemaをクリックするのが危険過ぎる - K52.NIKKI ver3.0というのが添えられていました。
よくわからなかったので現象を呟いたところ、親切なMySQLのACE(えーす)のyoku0825さんがinnodb_stats_on_metadata=1があやしいんじゃないかと教えてくれました。 ググってみたところ、innodb_stats_on_metadata に要注意 - TAKUMI SAKAMOTO’S BLOGというページを見かけて何が起きたかわかった気になったのでした。
起きたことの予測: ・テーブルの更新状況が統計情報更新の発生条件に達している状態だった ・information_schemaのリンクをクリックすることでshow table status相当の統計情報更新のきっかけになるクエリが走った ・統計情報更新のためにANALYZE_TABLE相当の処理が走った ・ディスクがあふれたのはテーブルのコピーがtmpdirに作られたためで挿げ替えられて処理が完了したために使用率が下がった ・cpu負荷はALTER相当のTABLEメンテナンス処理とそれに伴うディスクI/Oによるものと考えられる
innodbの統計情報更新の発生条件については、漢のブログに書いてあるのをみつけました。いつもありがとうございます。 めでたしめでたし。とこれだけだと物足りないのでちょっと足します。
どのバージョンでONかOFFかについて、公式のマニュアルをみると5.6.6からOFFでそれ以前はONのようです。
つぎに仮にinnodb-stats-on-metadataを0にしたばあいメンテナンスを自分で行う必要が生じるけどどうしたらええんやという話について。
基本メンテ入れて統計情報更新するだけならANALYZE TABLEするかデフラグもしたいならALTER TABLEしたほうがいいです。 InnoDBのOPTIMIZEは内部的にALTERが実行されるだけなのでREADのロックがかかるのが嫌ならALTER TABLE使うといいです。 データ(とスペック)を極力本番同様にした試験環境でかかる時間を見積もるのがオススメです。 表にマニュアルのリンクを貼っておきました。左は5.1日本語で右は5.6英語のリンクです。
・参考サイト innodb_stats_on_metadata に要注意 - TAKUMI SAKAMOTO’S BLOG 漢(オトコ)のコンピュータ道: 大人のためのInnoDBテーブルとの正しい付き合い方。 漢(オトコ)のコンピュータ道: ALTER TABLEを上手に使いこなそう。 MySQLトラブル解析入門 テーブル メンテナンス ステートメント MySQL :: MySQL 5.5 Reference Manual :: 13.7.2 Table Maintenance Statements Percona Toolkit pt-online-schema-change でサービス無停止スキーマ変更 | 外道父の匠 pt-online-schema-changeを安全につかう - Around the World
FuelPHP + Ansible で超ラクラク開発/運用 - FuelPHPのインストール編
...開発者でも簡単にインフラ構築できる時代が来ました。Ansibleという強力な環境構築ツールを利用すれば簡単に環境構築ができます。
環境構築のツールはそのほかchef, puppet, dockerなど様々ですが、なぜAnsibleを選択したのかは以前筆者が書いた以下の記事を参考にしてください。
Qiita ソフトウェアエンジニアからみた環境構築自動化ツールの比較、感想
PHPのフレームワークも近年人気を増しているLalavel, 定番CakePHP, 超高速PhalconなどありますがなぜFuelPHPを選んだかというと機能が豊富なことと日本語の情報がたくさんあるからです。単純に好みです。
これからFuelPHP + Ansibleを使った開発のノーハウを次のような順で紹介しようと思っています。
- パート1:FuelPHPのインストール編
- パート2:メンテナンスモード切り替え編
- パート3:デプロイ編
- パート4:開発/本番環境の運用時の構成、注意点
以下の開発環境をベースに説明させていただきます。また、Ansibleの概念を知っている人向けです。
- MacOS X 10.10.2
- ansible 1.7.2
- FuelPHP 1.7
※ ansibleのインストール手順はGoogle検索するとたくさん出てきますので割愛させていただきます。
AnsibleでFuelPHPをインストールするPlaybookを実行するためには~/role/ロール名/配下にその手順をyaml形式で書く必要があります。以下、~/role/ロール名/task/main.ymlの処理内容です。
- name: ①Copy the code from repository git: repo={{ repository }} dest={{ root_dir }} accept_hostkey=yes sudo: no - name: ②comporser self-update shell: php composer.phar self-update chdir={{ root_dir }} - name: ③comporser update shell: php composer.phar update chdir={{ root_dir }} - name: ④set fuel_env. shell: env FUEL_ENV=production php oil -v chdir={{ root_dir }} - name: ⑤create link. file: path={{document_root_path}} src={{fuel_public_dir_path}} state=link - name: ⑥db migrantion. shell: FUEL_ENV=production php oil refine migrate chdir={{ fuel_dir_path }}処理内で使用される {{ }} 中は変数名が入ります。 変数の定義は/role/ロール名/vars/main.ymlに記述します。上記の内容ですと
VirtualBoxでCSSが更新されない時の対処法
...VirtualBoxで構築したローカル仮想環境で 更新したCSSがブラウザキャッシュを削除しても適用されず、 確認できない状況に陥ったので、備忘録的に残しておきます。
apacheの設定が要因のようで、 httpd.conf に以下の設定をすることで解決しました。
EnableMMAP Off EnableSendfile Off
apacheのドキュメントは以下リンクをご参考ください。 https://httpd.apache.org/docs/2.2/mod/core.html#enablemmap https://httpd.apache.org/docs/2.2/mod/core.html#enablesendfile
Amazon RDS for Auroraプレビュー利用開始!
...Amazon RDS for Auroraでプレビューが始まりました。
Auroraとは…MySQLと互換性のあるデータベースエンジン(MySQL5.6)で、 高性能の商業用データベースの可用性およびスピードと オープンソースデータベースのコスト効率性および簡素性を併せ持っています。 Amazon Auroraは、MySQLの5倍の性能を持ち、 同様の機能や可用性を提供している商用データベースの10分の1の価格との事です。
現在プレビュー利用待ちです。
プレビュー利用したら感想等伝えようと思います。
ELBでssl転送してnginxでクライアント認証とssl終端してProxyProtocolで送信元IPを取得する
...こんにちは。 タイトル長いですがだいたい成功して時がたったので需要があるかはわかりませんが記録しておきます。
お時間あるときにどうぞ。
目的としては、以下のとおりです 外部ELB→nginx(ssl終端かつクライアント認証)→内部ELB→app
つまり、クライアント認証したいけどELBにその機能はないのでtcp443転送してnginxでやるが上位サーバでとれる送信元IPがELBのIPになってしまう為 ELBでProxyProtocolを有効化してnginxでssl終端しつつProxyProtocolをListenして送信元IPをログに出したいという話です。
securityGroupやインスタンス作るなどの部分は省略します。
1.elbをawscliで作成、proxy-protocol設定
参考:
AWS ELBのProxy Protocolを触ってみた Enable or Disable Proxy Protocol Support - Elastic Load Balancing 今更 VPC で 複数の AZ をまたいだ ELB を試す(2)〜 awscli を使って 〜 - ようへいの日々精進 XP
・elb作成
profile=xxxxx elbname-ext=xxxx-elb securitygrops="sg-xxxxxxxx sg-yyyyyyyy" subnets="subnet-xxxxxxxx subnet-yyyyyyyy" sudo bash -c "aws elb create-load-balancer --load-balancer-name ${elbname-ext} --listeners Protocol=TCP,LoadBalancerPort=443,InstanceProtocol=TCP,InstancePort=443 --subnets ${subnets} --security-groups ${securitygrops} --profile ${profile}"※外部ELBはTCP443からTCP443に転送するだけで証明書を入れない感じの設定にします
DevOps時代のアジャイルでスケーラブルな開発環境をVagrant, GitHub, Travis, Chef, OpsWorksで構築する
...どうも。久しぶりです。 デベロッパーの平形です。
このブログに訪れたすべてのエンジニアの方々。 そして、エンジニア以外の方々。
とても感謝致します。 初めに言っておきますが、この記事ではコード、コマンドラインの一切は登場しません。
はじめに
私が今回お送りする内容は本当にスケーラブルな環境の構築、運用を手助けする事ができます。 連載記事で複数回に渡ってお届けしますが、この連載を読み終えそして実践していただければ、あなたは既にスケーラブルな環境で作業を行っている事でしょう。
この連載記事では、順番に必要なツールのインストール、使い方をハンズオン形式でお送りします。 実際に手を動かして実感していただく事がとても意味がある事だと思っています。 この回では、コード、コマンドラインは一切登場しません。次回以降にどんどん出てきます。 その前に**「伝えたい事があるんだ。君の事が好きだから」by小田和正**と叫ばせてください。
この記事は以下の方には不向きです。
- 俺は一生一人で生きていくんだ!と1日1回はトイレで意気込んでいる人。
- 後先の事なんか考えたくない。俺は今を生きているんだ!と週に3回は言っている人。
これらに該当する方。お疲れ様でした。出口はこちらです。
この記事は以下に該当する方に是非読んでいただきたいです。
- 開発者、インフラ担当者の方。
- これから新しいプロジェクトを立ち上げるんだけど、構成どうしようか悩んでる方。
- サーバーの台数が多くなったらどうしよう。と悩んでいる方。
- 開発要員が急に増えたらどうしよう。と悩んでる方。
- DevOpsとかスケーラブルな環境とかに興味があって、でも今ひとつ踏み出せない方。
- 上記を実践してみようとしたけど、挫折してしまった方。
- 開発環境で動いているコードがなぜか公開環境で動かなくて家に帰れない方。
- 本番反映が怖くて会社に行きたくない方。
- サーバーが落ちる事が不安で夜も眠れない方。
- 将来の事を考えると不安で不安で仕方なく、「とにかくもう、学校や家には帰りたくない〜。」by尾崎豊と口ずさんでしまう方。
それでは、夢の扉を開きましょう。
レガシーな開発と運用
- 開発環境、公開環境の構築は、構築手順書を元に手動でインストールしている。
- 公開環境のサーバー増設は1台ずつ手動でキッティングしている。
- パッチの適用、バージョンアップは手動で1台ずつ手順書を元に実行している。
- バージョン管理はしないで各自、修正ファイルをFTPでファイルをアップロードしている。
これらをヒューマンエラーなく、ストレスなく運用できるのはスーパーマンです。 そして、開発、運用メンバー全員が自分と同じスーパーマンでなければいけません。 凡人の僕には無理です。
現代の開発と運用
現代のもの凄い勢いで変化するサービス要求に耐えるには、様々なものを効率化しなければいけません。
素早くリリースしてユーザの反応を見ては仕様を変更してすぐに反映しまたリリースする。といった事も必要です。
近頃、開発運用の自動化は様々なメディアの記事で取り上げられ、賑わっています。 しかし、実際にどこまで自動化ができているのでしょうか?- バージョン管理
- 環境構築
- セキュリティパッチの適用
- バージョンアップ
- オートスケール
- 自動テスト
- 自動デプロイ
- 開発環境の配布
なかなか全部はできないですよね? でもやったほうが絶対に幸せになれます。