build 2016 落ち穂拾い 〜Azure編 Day 1〜
...こんにちは、Azure担当の原です。
build では数多くの発表がありましたが、まずはAzure関連から。 現地で参加したセッションの中から、特に気になったものを中心にご紹介していきます。
尚、セッションの動画や資料は「Channel 9」で公開されています。buildの3日間だけでも大量のセッションがありましたので、参加しきれなかったものはこれから見ていこうと思ってます。
https://channel9.msdn.com/Events/Build/2016
全体的な感想
基調講演にもありましたが、Azureに関する今年のキーワードは「Choice + Flexibility」「Productivity」「Enterprise Ready」だったようです。 特にインフラ系のセッションでは「Hyper-Scale」という単語が良く出てきていました。イベント中にGAの発表があった Service Fabric なんかが象徴的ですが、より大規模なアプリケーションを支える基盤を柔軟に使えるというアピールですね。
Day 1
【A Lap Around Azure’s Open Source Driven Innovation, Part I: Shipping Penguins in the Cloud | Build 2016 | Channel 9】
https://channel9.msdn.com/Events/Build/2016/B801
Open Source のいろんなソリューションがAzure上でも展開されていますよというお話。 * Open API と Swagger * MariaDB Cluster & Maxscale on Azure * Elastic Product Portfolio (Kibana, Elasticsearch, Logstash ES-Hadoop Beats) * DataStax
build 2016 に参加してきました
...はじめまして。Azure担当の原です。
3月29日~4月1日(現地時間)にサンフランシスコで開催されたマイクロソフトの技術者向けカンファレンス「build 2016」に参加してきました。
【Microsoft Build Developer Conference | March 30 – April 1, 2016】 https://build.microsoft.com/
速報的な記事はもう出揃っているかと思いますので、いきなりですが全体を通して感じたことを1つ。 今年の Build を象徴しているなと感じたビデオがこちらです。 【Microsoft Cognitive Services: Seeing AI app (audio description version)】
基調講演1日目の最後に流れたので、ご覧になった方も多いと思います。
今回のBuildで発表された Cognitive Services を使って、目が見えないエンジニアの生活をどのようにサポートしているかの実例を示した動画です。 講演中、サティアCEOが「Is technology empowering people」と何度か言っていたのはこういうことだったんですね。 テクノロジーで何ができるのか、具体論が示されたことで、デベロッパーに対しては「既にある素材でもここまでできるよ」と強く背中を押された気がします。 長丁場も終わりにさしかかって緩みかけた会場の雰囲気が一変したこの瞬間を現地で過ごせたことが、今回いちばんの収穫だったかもしれません。
今年のbuild、去年のような派手さはありませんでしたが、かつてはビジョンだけだった技術が実際に使えるSDKやAPI、HoloLensのようなデバイスとして登場するなど、確実に推進していく姿勢をはっきりと見せてくれました。それはまた、「フィードバックを求めています」というのが言葉だけで無いこと、動くコードを通じてデベロッパーと対話しようという姿勢なのだと感じられました。
このあたりは、現地を訪れたからこそ強く感じられたことのように思います。
といったような、技術はもちろんですが思わぬ角度からの刺激も受けられた3日間のイベントでした。
▼イベントの主なポイントはこちらをどうぞ。 知っておくべき Build 2016 における発表まとめ【4/4 更新】 | Microsoft Partner Network ブログ https://blogs.technet.microsoft.com/mpn_japan/2016/04/04/build-2016-announcements-summary/
4月1日は入社式&スーツDAY!
...こんにちは!
人事の市橋です。
4月1日の恒例行事
今日は2016年4月1日(金)、 新社会人・新入学の学生の方、おめでとうございます!
ISAOでは、4月1日は毎年恒例スーツDAYです。

普段はほとんどスーツを着ない私たちですが、この日はコスプレ気分でみんなスーツ!
新入社員をお祭り気分で迎え入れました。
2016年度新入社員のご紹介
今年新卒で入社したのは庄司 菫(しょうじ すみれ)さん。
お酒が大好きという彼女は、愛称・スミノフ。

3月に大妻女子大学を卒業。 管理栄養士の資格を持ちながら、IT業界への扉を開いたチャレンジ精神旺盛な一面も。
営業プロジェクト、通称SMAP (Sales&Marketing Project) をメインに活動します!
最後に
本日4月1日、新年度に合わせてISAOのコーポレートサイトもリニューアルしました。
MVS(ミッション・ビジョン・スピリッツ)をサイト自体が体現することにフォーカスしています。
バリフラットモデル、中長期ビジョンのVISION 2020、 ISAOが手がけている自社サービス、クライアントサービスのPortfolioなど、 企画・制作・開発・演出、すべてTeam ISAOの力を集結させて作りました。
是非ご覧ください。 https://www.colorkrew.com/
2016年度のISAOは、世界のシゴトをたのしくを実現するべく、ますます前進していきます。
みなさまよろしくお願いいたします!

SXSW 2016で見つけた、本気で欲しいIoTデバイスTOP5
...前回の記事はこちら SXSW 2016 現地レポート〜基本編〜
こんにちは、ISAO マーケティング担当の中嶋あいみです。
SXSW(サウス・バイ・サウスウエスト)では、 ITパーソンやマーケターなら誰でもワクワクしてしまう新しいプロダクトに出会えます。
実はSXSWで新たに発表されるプロダクトやサービスは一部で、 既にクラウドファンディングのKickstarterやIndiegogoで公開されていたりするものが大半です。
とはいえ、話題のものが一同に集まって、しかも実際に触れることができ、 その場でフィードバックが得られるというのは、出展者にも来場者にも他には無いチャンスです。
Finalist ShowcaseとTradeshowは宝の山
プロダクトにお目にかかれる機会は大きく2つ。
- Interactive Innovation Awards Finalist Showcase
- Tradeshow
Interactive Innovation Awards Finalist Showcase

Interactive Innovation Awards (インタラクティブ イノベーション アワード) は、 SXSWのITセクションの目玉的イベント。
13もの分野から最もイノベーティブなプロダクトやサービスがInteractiveの最終日に表彰されます。
そのファイナリストたち65点を集めたショーケースということで、注目度がかなり高いです。
にも関わらず、 ショーケースは5日間のうちの1日、しかも3時間しかないので、会場はかなりの混雑でした。
確実に見たかったら、オープン前に並びましょう!
Tradeshow(トレードショー)

前回の記事でも触れましたが、大規模かつ種類豊富な展示会です。
日本・韓国・スペイン・ブラジルなど、たくさん出展する国はエリアがまとまっています。
日本は東大の学生らのスタートアップ、Todai to Texasが毎年出展しています。
IoT、流行ってるけど実際使う?
いろんなデバイス・ガジェット・サービスを見ていて、どれも素晴らしいアイデアや技術だと思いますが、
正直、
『面白い!けど・・・使うかな?』
SXSW 2016 現地レポート〜基本編〜
...こんにちは、ISAO マーケティング担当の中嶋あいみです。
私たちは今週、アメリカ・テキサス州・オースティンにいました。
目的はSXSW(サウス・バイ・サウスウエスト)!
今回、ISAOとしては初めてのSXSWに、けいすけ・としき・あいみの3人が行かせていただきました。

SXSW(サウス・バイ・サウスウエスト)とは?
今年で30周年を迎える世界的なカンファレンス。

もともとは音楽フェスティバルから始まり、 今では音楽・映画だけでなくIT業界の見本市・スタートアップの登竜門としても知られています。
日本では知名度が今ひとつですが、 1月にラスベガスで開催されるCES (Consumer Electronics Show) に参加するような企業には、親和性は高いと思います。
業界プロフェッショナルとクリエイターのためのフェスティバルであり見本市でありカンファレンスです。 1987年にミュージックからスタートし、94年には世界に先駆けてインターネットとデジタルのコミュニティを取り込み現在の形に変化してきましたが、その核=COREは常にクリエイター、イノベイターがキャリア広げるために世界中から集い、お互いのアイディアを学び合い、共有しあうためのプラットフォームとして役割を担うことにあります。 年毎に規模が拡大し、今日では10日間でのべ10万人、約380億円の経済効果をもたらす、世界最大級のビジネスフェスティバルに成長しています。
引用元:http://sxsw.jp/about-sxsw/今年の開催は3月11日(金)〜20日(日)。 全10日間が、以下3つのセクションで構成されています。
- Interactive - Music - Film
私たちが参加したのはIT・Tech系のInteractive(インタラクティブ)。
まだスタートアップだった頃に TwitterやFoursquareが有名になるきっかけとなったのもSXSW。
これから流行るサービスをいち早く目にすることができることに加え、 普段会うことのできない世界の著名人の講演に参加できることも魅力です。
2016年のSXSW、目玉は?
出発1週間前に公式メルマガから驚きのニュースが。
なんと初日のKeynote(基調講演)にオバマ大統領が登壇!
時はアメリカ大統領選の予備選挙真っ只中。 現職の大統領を見られるなんて、おそらく一生に一回のチャンスでしょう。
SXSWは基本的にワークショップ以外は全て予約はできず 人気の講演は当日に並ぶしかないのですが さすがにオバマ大統領は人が殺到してしまうので抽選制でした。
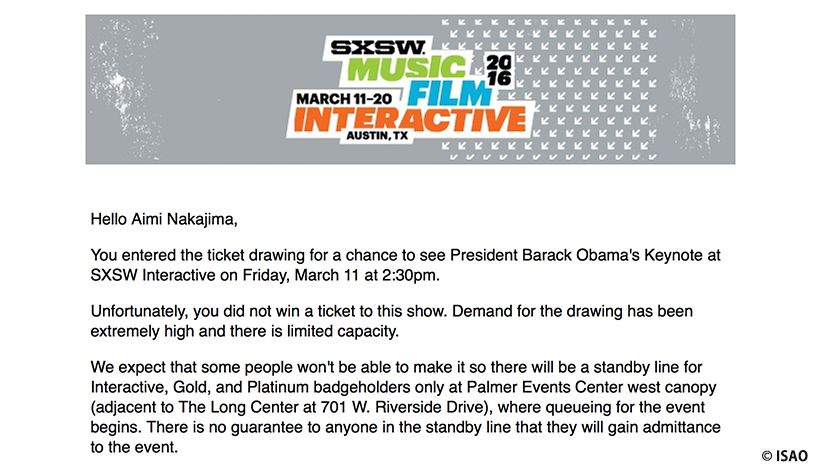
残念ながら抽選には外れてしまい、画面でのパブリックビューイング。

ちなみに、別日にはミシェル夫人も登壇されていました。
帰国日だったので、残念ながらこちらも拝見できず。
SXSWのプログラム
Interactiveは主にこのような構成です。
- Session (セッション)
- Pitch Events (ピッチ)
- Meet Ups (ミートアップ)
- Workshops (ワークショップ)
- Keynotes (基調講演)
- Tradeshow (トレードショー)
- Lounge (特設ラウンジ)
- Party (パーティー)
Session (セッション)
セッションの中でも、登壇する人数で分かれています。
Be Professional〜プロフェッショナルになる~
...プロフェッショナル化と市場価値の関係
会社、組織には、様々な職種の人がいます。
技術系、営業系、管理系、事業系など。
ですが**「プロフェッショナル」**であることに関して、あまり職種とは関係なく意識しなければならないことがあります。
そして、どの職種であっても**「プロフェッショナル」であることが自分自身の市場価値を高めること**に密接に結びついています。
プロフェショナルとは何か
では「プロフェッショナル」とは何か。
会社やチームが行っている「事業」に、尖った専門性を持って貢献すること。
この一点です。
どのように貢献するかは職種によって違いますが、自分の仕事がどういうルートでどのようにチームと事業に貢献しているかを考えることがまずは第一歩です。
そのためには、まず収益を含めてビジネス概観を知る必要があります。 そして、そのビジネスがどんな構造で成り立っているかを知る。
その構造の中で、自分の仕事はどこにどのように、どんなインパクトを与えているか、これを考える。
技術力が高い
交渉がうまい
事務作業がはやい
これらはそれそのものが評価されるべきものではありません。
その高い技術力、そのうまい交渉、その素早い事務作業、これらがチームや事業によい影響を与えている事が、その人の価値と言えるのです。
視点を上げて、専門性を高める
視点を高くしてチーム全体の仕事を考えていきながら、自分の専門分野を高めていく
これがプロフェッショナルへとつながる考え方、キャリアを作る第一歩になるのです。
いつも上機嫌のススメ
...上機嫌、していますか?
いきなりですが、みなさんはいつも上機嫌でしょうか?
ISAOリーダー訓の1つ目に挙げているように
「上機嫌」であることはリーダーに限らずビジネスパーソンの**”スキル”**として非常に大切だと考えています。ISAOリーダー訓
- いつも上機嫌
- メンバーの成長に執念を燃やすこと
- 成長の為に変革を恐れないこと
- 思考停止しない
- 明るく、ポジティブ
- サボらない、率先垂範
- クリーンであること
- 厳しく、やさしいこと
- 常に高い視点で判断する
- できない理由ではなく、できる方法を考える
- 作業に埋もれない
- 毎日組織を前進させる
- 間違ったら素直に認め、すぐ修整
- 業績向上に執念を燃やす
- 起こったことは全て自分の責任とする覚悟を持つ
- 手柄はメンバーやチームのもの、のメンタリティ
- ISAO全体のことを常に考える
- 常に短期、中期、長期のビジョンを持って行動する
- 「いつも上機嫌でなんかいられるか」
- 「なぜ上機嫌でなければいけないんだ」
なんていう意見もあるとは思います。
でも、ボクは「上機嫌でいること」というのはISAOの中で理屈抜きにとても大切にしていきたいし、そういう人を評価もしていきたいと思っています。
上機嫌がうみだすポジティブなスパイラル
上機嫌は周りのメンバーの笑いを作り出す。
笑いがあればいい雰囲気になる。
ポジティブになる。
どんどんチャレンジしたくなる。
ポジティブ、チャレンジ、笑い・・これらは僕がISAOの中で追求し続けたいものなのです。
リーダーこそ、上機嫌
特に、リーダーは**”いつも”**上機嫌であることは重要。
なぜならば、リーダーは不機嫌なメンバーに対して注意をすることは可能ですが、リーダーに周りのメンバーが注意することは難しいからです。
自分がリーダーで「もしかして不機嫌なこと、あるかも」と思った人、どうしたら上機嫌になれるか考えてみましょう。
楽しいから笑うのではない。笑うから楽しいのだ
これは、アメリカの心理学者ウィリアム・ジェームス氏の言葉だそうですが、要は努力することで上機嫌になれるんだ、ということだと理解できます。
どんな上機嫌を目指すのか
それはただニコニコしているという受身の上機嫌ではなく、
周りの人とどんどん関わり、どんどん一緒に熱中していく、という能動的な上機嫌。周りの人と楽しく関わっていく為には、ジョークを言える能力も含めたコミュニケーションスキルがとても重要で、これは意識してスキルアップしていくべきものです。
ここで誤解して欲しくないのは「能弁でなくてはならない」ということではない、ということです。
言葉が少なくても上機嫌なコミュニケーションができればいいのです。
上機嫌な人には人が集まってくる。情報も集まってくる。相談もされる。
なぜなら、みんな楽しく仕事をしたいから。
そうやってみんなの中心になれる人はより大きな素晴らしい仕事ができるステージが用意される。
イラスト入り名刺、できました
...全社員イラスト化プロジェクト
こんにちは、ISAO PR担当の中嶋です。
先日、ISAOの新しい名刺が完成しました!

デフォルメバージョンも。

**『全社員イラスト化プロジェクト』**を立ち上げて、1人ひとり描き下ろしています。
イラスト名刺作成のステップ
手書きのラフから・・・

線画にして・・・

色をつけて完成!

イラスト名刺への想い
初めてお会いする方に、顔を覚えてもらえるように・・・との想いで、 総勢7名のISAOクリエイターたちが自主的に立ち上げたチャレンジプロジェクト!

最近、名刺交換が楽しみになりました。
全社員イラスト化まであと100人近くいますが、全員揃うのを心待ちにしています!
今日からやめよう。組織が陥る権威主義
...権威主義、反権威主義者とは?
株式会社ISAO代表取締役、中村圭志です。
突然ですが、僕は**”反”権威主義者**です。
これまでいろいろな組織の中で仕事をしていて、個人的にも違うと思っていて、 且つこれからもそういうことのないチームで仕事をしていきたいと思っています。
「権威主義」の定義から見ていきましょう。
権威主義(けんいしゅぎ)とは、権威に服従するという個人や社会組織の姿勢、思想、体制である。
権威を強調する体制は、権威を軸にしたヒエラルキーを形成してエリート主義を持ち、実質的な権力や階級として固定化する場合もある
引用:https://ja.wikipedia.org/wiki/権威主義要は、強者やポジションのある人を無批判に受け入れる、という意味ですね。
組織における権威主義とは?
大企業だけでなく中小企業でもありがちなのが、こんな文化、先入観です。
- 役職や上位の肩書がある人(代表・役員・部長・課長など)の意向が絶対であること
- 部下に対して、反論を許さない”雰囲気”がある
- 上位のポジションにある人がその権威を持って、優越的に部下に接している
一言で言うと、威張ることです。
みなさんの会社、組織でもありませんか?
もしくは、ご自身がそういった振る舞いをしていませんか?
身近にもある不必要な"威張り"
いつもは会社で腰が低くて丁寧なのに、タクシーの運転手や飲食店の店員とかに、なぜか高圧的な話し方する人がいますよね。
自分は若いのに、自分の親くらいのタクシーの運転手さんに「xxx 行ってくれる?」みたいな人を見ると、お前は何者だよ!って思います。
年下相手ならいいということではありませんが、特に人生の先輩に対して礼を失した態度はまったくもってダメだと思います。
仕事でもこちらが発注者(優位な立場)のとき、発注先の人にぞんざいな口の利き方をする、
これも同じです。
そういう人は、相手そのものではなく、相手のポジションしか見ていません。
上司が部下に度を超えた偉そうな態度を取るのも同じことです。
相手が自分より立場が弱いので、上から目線で話をするのです。
部署の立場が弱い人とか、後輩に必要以上にきつくあたったり、ひどい口の利き方をするのも同じ。
そういう人に会った時、どう思うでしょう。
きっと、その人の機嫌を損ねるのは得策ではないので、適当にオアイソはしますが、その人と一緒に仲間になって成功しようとは決して思わないでしょう。
”反”権威主義者のススメ
ISAOでは、こういった権威主義がないように運営していきたいと強く思っています。
これは、バリフラットモデルを導入する前から宣言しています。
フラットで、でもお互いにリスペクトのある関係。
余談ですが、ISAOスピリッツのオープンとキズナはこういったことも表現しています。
ISAO Spirits(価値観)
- 新しきに挑み拓く
- 自分の仕事を愛し誇る
- オープンにつながる
- 見えないものを見る
- 家族的キズナ
誰にも遠慮せず、みんながどんな立場であろうと堂々と発言をする。
と同時に、お互いへのリスペクトを忘れない。
そんなチームでありたいと強く思っています。

Goalous(ゴーラス) が、ローンチされました。
...こんにちは。きくちです。トップ写真の手前のどこかにいる、ご存知きくちです。 本日2月15日、Goalous ( ゴーラス ) がローンチされました。 https://goalous.com サービスカラーがちょいと濃い目のレッドなので、家族的すぎる社員のみんながレッドを体にあしらって出社してくれました!っていう集合写真です。Pepperくんが帽子をかぶって駆けつけて来てくれたのには、さすがに驚きましたね。パンツだけレッドな人もいたんですが、ちょっと遠慮してもらいました。こんなロゴです。
 Goalousとは、「Goal( 目標 )でいっぱい」という意味合いで、形容詞的な表現として「-ous」を後ろにくっつけて命名された名称です。その名の通り、Goalousはゴール達成のための社内SNSです。
Goalousとは、「Goal( 目標 )でいっぱい」という意味合いで、形容詞的な表現として「-ous」を後ろにくっつけて命名された名称です。その名の通り、Goalousはゴール達成のための社内SNSです。Goalousでなにができるのか?
【ゴール達成を目指す全社員とのコミュニケーションを通して、“だれが・なんのために・なにをした”を理解し合うことで、協力による成果をだすことができる】、これがGoalousでできることです。 ゴールとは、「将来的に成し遂げようとして設けた目印」を指します。目印ですから、なんのために・いつまでに・どの程度という要素が含まれます。Goalousでは、個人が設定したゴールがすべてのメンバーにオープンにされます。すべてのゴールがオープンになると、従業員の目指す方向が広範囲に明らかになります。だれが、何を成すために存在しているのか。これは働く上では、とてもベーシックな情報です。ゴールが明確でなければ、『協力』が発生しにくい状態となります。だって、何がしたいかよくわからないわけですからね。
1分の動画でイメージをつかんでください。
チームで最も大事なこととは?
何かを成し遂げようと協力する集団のことを、「チーム」と呼んでいます。これは、単に人の集合体を示す「グループ」という表現とは、分別して認識されるものです。 チームで最も大事なことはなんでしょうか? 話をよく聞く?褒め合う?意見を否定しない?どれでもありません。正解は、「お互いをわかりあうべく心血を注ぐこと」です。それでは、どうしたらお互いをわかりあえるのでしょうか。我々は、「まずはゴールである」と考えています。チームとは何かの達成を望むものなので、その「何か」をまず認識しないことにはスタート地点に立てません。したがって、まずゴールなんです。
Goalousの特徴は?
ゴールはわかった。それでチーム力がバンバンでるのか?いいえ、これだけでは不十分です。「で、なにしてるの?」という要素が不足しています。「明日の朝までに富士山の山頂に到達したい」というゴールがあって、「で、あなたはなにしてるの?」という認識がなければ、協力への糸口がありません。チームとは協力する集団ですから。さっき富士山に登り始めたのか、もう少しで山頂なのか、どこか体調が悪いのか、はたまたまだお家でくつろいでいるのか…。これがわからないと、あなたの役割も能力も、思いもなにも伝わりません。 Goalousでは、写真付きのアクションでゴールへの「今」を即座に共有できます。

他の社内SNSとなにが違う?
上記の特徴的な機能は、「フォトアクション」と呼ばれています。単なる情報交換にすぎない他のSNSとは、まったく異なる機能があることがおわかりでしょうか。Goalousは、「ゴールでつながる社内SNS」なのです。ゴールがメンバーによって作られ、そのゴールをフォローやコラボすることでゴールとつながります。コラボとは、共通のゴールを目指す仲間のことです。ゴールに対してフォトアクションすることで、写真とともにホームフィードに掲載されて、みんながたのしくチェックできます。もちろん、他のSNSにあるような、特定のメンバーをグルーピングして閉じた空間で情報交換することももちろん可能ですが。
後発のSNSですね?
確かに、、、トゥワしかに後発かもしれません。しかし、ニュースフィードを中心としたSNSというWebツールの持つ力をさらに押し広げてビジネスの場にいかすという可能性を信じていますし、その開拓に挑戦していきたいと考えております。ゴールをオープンにする。アクションもオープンにする。気軽にリアクションする。みんなで目指す。みんなでわかり合う。そして、シゴトをたのしく!これです。
テスト利用はどうすればいい?
期間限定ですべての機能を「無料」で公開しています。ぜひご登録いただき、使ってみてください!こちら( https://goalous.com )からどうぞ。
掲載報告:月刊人事マネジメント2月号
...こんにちは!
人事の市橋です。
昨日のブログに続き、ISAOバリフラットモデルの記事掲載のご報告です!
掲載のご報告
掲載されたのは、1991年1月創刊、今年で25年目を迎えた**『月刊人事マネジメント』2月号**

Goalous PR 前澤俊樹
ここでは、ISAO創業の歴史から、バリフラットモデルを取り入れた経緯、 代表取締役の中村圭志や、ISAO経営陣の想い、 そして、2月15日にリリースされる社内SNS『Goalous』のことまで触れていただき、 とても読み応えのある内容になってます。
本誌は書店等で販売してないので、皆さんの目に触れる機会は少ないですが、 もし機会があれば、是非読んでいただきたいです。
取材のお申し込み
株式会社ISAOでは、媒体に問わずいつでも取材受付中です!
こちらのお問い合わせフォームか pr@isao.co.jpまでお問い合わせください。
PR担当:市橋、前澤、中嶋
掲載報告:アイデム人と仕事研究所 制度探訪
...こんにちは
ISAO PR担当の中嶋です。
最近バリフラットモデルやISAOの文化、制度について お問い合わせいただくことが増えてきました!
掲載のご報告
昨日は、先日のブログでご紹介した、バリフラットモデルの取材記事が公開されました。
掲載されたのは、人材の採用・育成・活用・定着に資する情報を提供する 『アイデム人と仕事研究所』の制度探訪です。
バリフラットモデルの内容だけでなく、 なぜISAOが組織のフラット化、オープン化にこだわるのか、 代表取締役の中村圭志や、ISAO経営陣の想いの部分にたくさん触れていただいています!

全文を読むにはアイデムの会員登録が必要ですが、是非読んでいただきたいです。
取材のお申し込み
株式会社ISAOでは、媒体に問わずいつでも取材受付中です!
こちらのお問い合わせフォームか pr@isao.co.jpまでお問い合わせください。
PR担当:市橋、前澤、中嶋
勇気を出して初めてのランチ
...ISAOのおもしろ制度を紹介します
こんにちは!ISAO人事担当の市橋です。
ISAOには5つのスピリッツがあって、 その中に「家族的キズナ」というものがあります。
今日はそんなISAOの「家族的キズナ」を深める取り組みをご紹介します!
その名も・・・
勇気を出して初めてのランチ
略して**「勇気ランチ」**です。
勇気ランチって?
ISAOは約200人のメンバーが働いているので、 「顔は知ってるけど話したことない!」って人が結構います。
バリフラットモデルを導入したタイミングで、 以前の階層やプロジェクトの垣根を越え、新たなコラボレーションやシナジーを生みだすことを目的として、 昨年10月から勇気ランチを始めました。
ルールはいたって簡単。
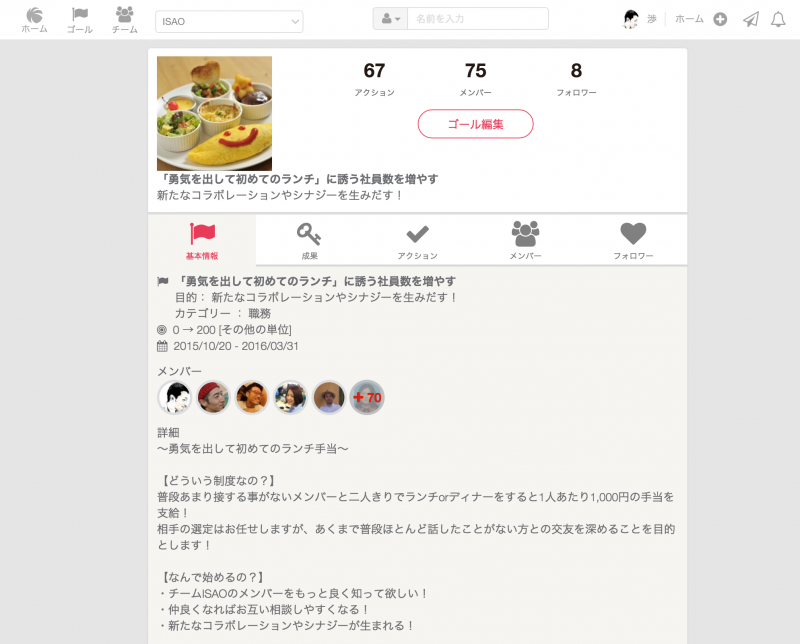
- 社内SNSGoalousで僕が作った「勇気ランチに行く人を増やす」のゴールにコラボ
- 普段接する機会がない社員を誘って、2人きりでランチに行く
- 2人でランチに行ったら仲良く写真を撮って、ゴールにアクションとして投稿
- 2人分のランチ代として、1人あたり1,000円の手当を支給
人事担当として感じること
始めてもうすぐ4ヶ月経ちますが、既に60組以上のメンバーが勇気ランチに行ってます。
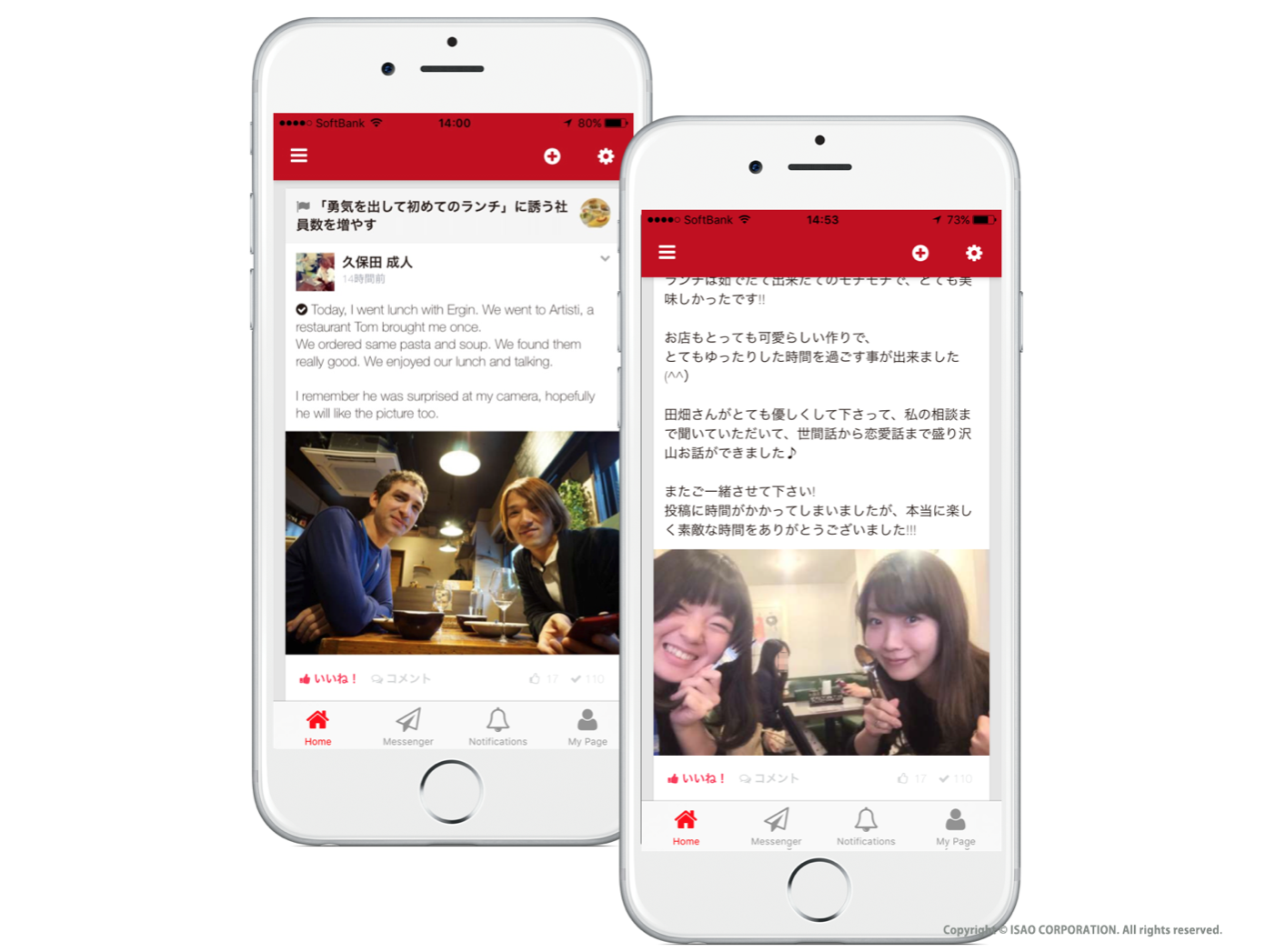
その中で実際に仕事上のコラボレーションが生まれたり、 共通の趣味を発見したり、生年月日が全く同じことが分かったり!
どんどんキズナが深まってます。
ちなみに人事の私は対象となる社員があまりいなかったりするんですが、つい先日誘われました!
数カ月前に入社したIT業界(というかデスクワーク)初めての20代の女の子。
何だか偉そうにこれからのキャリアとか、人生とか、その他趣味のこととか色々話しました。
年齢はもちろん、キャリアも考え方も人それぞれ。
色んな人と二人で話ができて、新しいことに気づいたりできる、これもこの勇気ランチの醍醐味だったり。
こういう取り組みをやると、みんなが積極的に活用してくれるのが、ISAOの良いところです!
今日はどんなペアが勇気ランチに行くか、とても楽しみです。
バリフラットモデルの取材を受けました
...こんにちは
ISAO PR担当の中嶋です。
バリフラットモデルを導入して、早くも3ヶ月が経ちました!
お陰さまで、最近取材のお申し込みが急増しています。
本日は、代表取締役の中村圭志が取材を受けました。

バリフラットモデルを始めて組織はどう変わった?
「世界のシゴトをたのしく」とは?
ISAOのおもしろ制度
- 勇気を出して初めてのランチ
- TGIF
- MVS研修
など、たくさんお話させていただきました。
取材していただいたフリーライターの島田様には 「非常に興味深く、楽しいお話でした」とコメントを頂戴しています!
媒体に掲載された際は、こちらでお知らせいたします。
取材のお申し込み
株式会社ISAOでは、媒体に問わずいつでも取材受付中です!
こちらのお問い合わせフォームか pr@isao.co.jpまでお問い合わせください。
PR担当:市橋、前澤、中嶋