Begin with Courage! Empowerment is Proof of Trust.
...Sometimes work can feel rewarding, but at what times do you feel rewarded at work?
- When doing something you enjoy?
- When you feel that growth is taking place?
- When your team is functioning properly?
While these may be important elements, wouldn’t you agree that the strongest feelings of reward are provided in situations where one has been given empowerment.
勇気を持ってはじめよう。権限委譲は、信頼の証。
...シゴトにやりがいを感じるとき
みなさん、どんなとき仕事にやりがいを感じますか?
- 自分が好きなことをやっているとき
- 成長実感があるとき
- チームワークが機能しているとき
これらは重要な要素ですが、自分に任せてもらっている状態が、最もやりがいを感じられるときではないでしょうか。
権限委譲が進まないワケ
ということは、みんながやりがいを感じて、バリバリ仕事をするためには、権限委譲をしまくればいい!ということなのですが、実際には、権限委譲が進んでいない組織は多いですよね。
なぜでしょう?
「権限委譲」とは、そもそも権限を持っている人 (上司) が、他の人 (多くの場合、部下) に決済権限を渡すということです。
上司が部下に権限委譲できない理由ってなんでしょう。
- 自分の仕事が取られてしまうから渡したくない
- 面倒くさい
- なんとなく
- 部下を信頼できていない(渡すのが不安)
などなど。
上の3つは論外ですので、こういう人はもっとちゃんと考えてもらうか、ラインから外れてもらいましょう。笑
結果、マトモな人が上司になったと仮定して、最後の「信頼できていない」さえ解消すれば、権限委譲はどんどん進むこととなります。
ちなみに、ISAOは「バリフラット」という、ヒエラルキーのない組織運営をおこなっており、上司部下という関係がありませんので、権限委譲はすべての仕事において、日常的に発生します。
信頼できるようになるためには
では、信頼できるようになるためにはどうしたらいいでしょうか。
スキルとか、経験が足りないから信頼できない?
違います。それは重要ではありません。
もっとも重要で、唯一必要なのことは、価値観の共有です。
ISAOの流儀
ISAOにとって価値観とはMVS(ミッション・ビジョン・スピリッツ)です。
- ミッション:たのしい!をうみだしとどける
- ビジョン:日本発!億人を熱くするサービス実現!
- スピリッツ:オープン、チャレンジ、キズナ
MVSを共有できている仲間であれば、ガンガン権限委譲する。それがISAO流です。
「活動をオープン」で失敗をカバーする
先ほど、スキルや経験が足りないと(失敗するから)信頼できない!?と書きましたが、 MVSをしっかり共有した上での失敗は、どんどんすればいいんです。
失敗しても、すぐに修正できれば、致命傷にはなりません。 ガンガン修正して、ガシガシ進む。
これがISAO流。
そのために必要な考え方が「活動をオープンにする」です。
ISAOでは、自分の活動をGoalous(ゴーラス)ですべてオープンにしています。
そのため、どんどん権限委譲して、どんどん失敗して、どんどん修正しながら突き進むことができるのです。
まとめ
権限委譲を推進し、やりがいのあるチームにするためには
価値観を共有し、権限委譲を進め、活動をオープンにして、ガンガン進む。
シンプルですが、これができればどんな組織も、ビジョンに向かうスピードを画期的に上げることができます。
活動をオープンにするのが難しい!? そんな方にはオススメサービス「Goalous」(宣伝)を紹介いたしますので、ぜひお問い合わせください!
勉強会を開催しました!「AWSを使っているならOpsWorksでDevOpsしよう!」、「AWS運用アレコレ」の二本立て
...こんにちは、平形です。
先日8/24、弊社で4回目の外部向けの勉強会を開催しましたので、その様子をご報告させていただきます。
今回はAWS関連のトピックを私、平形と同じく弊社エンジニアの赤川がお届けしました。

今回4回目となる勉強会も盛り上がりを増してきた事もあり、弊社代表の中村が自ら挨拶を買って出てくれました。
今回もたくさんの方々にご参加いただき、大変嬉しく思っています。
内容
今回は、
- AWSを使っているならOpsWorksでDevOpsしよう! by 平形
- AWS運用アレコレ by 赤川
の2本立てです。
イベントページはこちらのconnpassページにて
弊社では、AWS, GCP, AzureなどクラウドリソースをMSP事業、自社サービスで積極的に活用しております。今回はその中からAWSについてお話ししました。
今回の勉強会のもう一つの特徴は、スピーカーの2人とも今年第一子が誕生した新生育児パパという事です。育児と仕事の両立をして日々業務に精を出しています。
株式会社ISAOは、そんなイクメンエンジニアを応援しています!
AWSを使っているならOpsWorksでDevOpsしよう! by 平形

AWSのデプロイサービスの一つOpsWorksについて実際の業務で得た知見を発表しました。
AWS運用アレコレ by 赤川
 AWSの障害対応など日々1,000台単位のEC2の運用を行なっている中から得られた運用のコツなどを発表しました。
AWSの障害対応など日々1,000台単位のEC2の運用を行なっている中から得られた運用のコツなどを発表しました。懇親会の様子

秋葉原名物の万世のハンバーグサンドです。
大変美味しく頂きました。

今回も多彩な領域のエンジニアの方々とお話しでき、有意義な交流会となりました。
Don’t remind me! The Secret Tactic of the Best Built Teams
...Do you give reminders?
Has a team member ever given you a reminder to finish the tasks you were working on?
The habit of team members giving each other reminders will not result in the best built team.
Why is that?
Why is it that a team that gives reminders cannot be the best built?
Let’s assume you have 5 tasks.
最強のチームはリマインドなし!
...リマインド、してますか?
いきなりですが、みなさんはチームで仕事するときに、他の人に「あれやってくれた?」とリマインドすることありますか?
他の人にリマインドするのが習慣になっているチームは、最強にはなれません。
なぜでしょう?
なぜリマインドするチームは最強になれないのか
例えば、自分が持っているタスクが5つあるとしましょう。
もちろん、チームは連動して機能しているはずなので、自分と関わりのある他の人のタスクは10個くらいはあるでしょう。
リマインドするのも、されるのも当たり前のチームではどうなるでしょう。
まず、個人が管理しなくてはいけないタスクは15になります。 かつ、リマインドされるのが癖になっているので、「誰かがリマインドしてくれるだろう」と自分自身のタスクの納期のコントロールが甘くなります。
では、リマインドなしのチームではどうなるでしょう。
個人が管理しなければならないタスクは5つのみです。
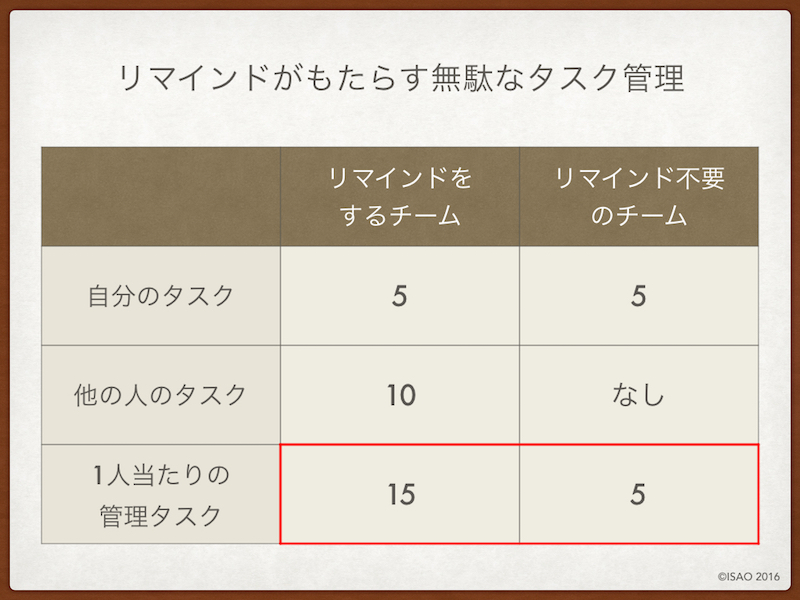
そして、リマインドされないことがわかっているので、皆が自分のタスクに対して責任感をもつことになり、納期を守る意識が高まります。
リマインドなしの利点まとめ
まとめると、リマインドなしチームの利点は3つあります。
- 個人が管理するタスクが減って、自分のやるべきタスクに集中できる
- 個人個人が責任を持つことで、納期を守れるようになる
- グレーゾーンがなくなり、より効率のいい連携ができるようになる
どうすればリマインドなしチームになれるのか
実は、リマインドなしチームになるのは簡単です。
常にタスクが誰にあるのかを、はっきりすること。
そして、タスクを持っている人以外は、そのタスク管理をしない。というよりタスクそのものを忘れてしまえばいいのです。
チームで仕事をしていると、タスクは少しずつ進化をしながら引き継がれていきます。
他の人にタスクが渡っているときは、思い切って忘れてしまいましょう。
それが、最強のチームへの第一歩となるのです。
社会人でも遅くない、キャリアを切り拓く4つのキーワード
...職業をどう選ぶ?
『あなたの職業、会社をどうやって選びましたか?』
この質問に明確に答えられる社会人はどのくらいいるでしょうか。
- これから社会人になる人
- いまからのキャリアをどう伸ばしていこうか考えたり、悩んだりしている若い人
そんな人にこの記事を読んでもらえると嬉しいです。
かくいう僕自身も、社会人になった時、そんなに明確に自分のやりたいことや職種を分析して、自分のキャリアを歩み始めたわけではなかったことをお伝えしておきます。笑
社会人になって20数年たったいま、「どういうキャリアを選ぶか、こう考えたらいい」という考え方が少しまとまってきたので、お話ししたいと思います。
まず、どんな職業があるのか知ろう
例えば、世の中に10の職業があったとして、3つしか知らずにそのひとつを選ぶのと、10の職業全部知った上で選ぶのは、どちらがよりよい選択ができるでしょうか?
3つしか知らない人は、その中で職業を選びますが、もしかすると他の7つの職業のうちにその人にもっと合った職業があるかも知れませんね。
そうです。 まずは自分にとって可能性がある職業を知らなければいけません。
知ってるってどういうこと?
10種類の職業を知ったら、その中で自分の進む道を選ぶ段階に進みます。
でも、そもそも何をもって、本当にその職業について知っているといえるのでしょうか。
4つの切り口で、それぞれの職業を考えてみるのです。
- 好きかどうか
- 給料
- 将来性
- 確実性
選ぶ!
ここまできたら、もう簡単です。 4つの切り口を埋めて、分析をして、選ぶだけです。
この手順を動画にしてみました。
わからない時は、調べたり人に聞いたりして、情報を埋めていきましょう。
ちなみに、ISAOでは全員の等級を公開していますので、職種・レベルによってどのくらいの給料をもらっているかは一目瞭然です。
自分の会社だけだと偏るので、社外の人とも積極的に話して情報を集めましょう。
- 職業を洗い出し、分析する
- 自分の重視する項目のプライオリティをつける
- 全体を見て総合評価して
- 選ぶ!
もう社会人になってる人にも有効な、キャリアプランの作りかたでした。
祝『バリフラット』商標取得!世界のシゴトを楽しくするために。
...自己紹介
こんにちは! ISAOの高井です。 はじめてIsaBに投稿しますので、かんたんに自己紹介をします。
人事、法務、総務を担当しています。 2009年3月入社なので、早いものでISAOに入って7年半経ちました。
さて、以前、当社代表の中村が紹介しましたバリフラットモデル。 https://blog.colorkrew.com/super_flatmodel/
この7月に商標登録が完了しました!

今回は、「バリフラット」という言葉が生まれた背景と商標登録までの流れをお伝えします!
「バリフラット」という言葉の誕生
誕生したのは、2015年9月28日。 社内でネーミングを募集し、ディスカッションして決めました。 そのディスカッションの過程もこちらで公開しています。
この「バリフラット」という響き、みなさんはどのように感じますか?
最初にこの言葉を聞いたとき、超フラットさを表すものとして、ストレートすぎると思いましたが、次第に語感にとても惹かれました。
「バリ」とは、言わずもがな博多弁の強調を表す言葉。 この「バリ」と、階層のない組織を表す言葉「フラット」が結びついたバリフラット。
これ以上わかりやすく、そして、印象に残る言葉はないと感じました。 やはり、ネーミングはわかりやすさと印象に残るものがよいですね。
社内外への発信から、商標登録へ
2015年10月1日(誕生してからわずか3日後!)、 「バリフラット」モデルを全社員に公表し、同時にプレスリリースを発信しました。
プレスリリース後、当社のこともバリフラットのことも知られていませんので、あまり反応はありません。ただ、少しずつですが、メディアからの取材を受けるようになりました。
一方、社内においては、思った以上に「バリフラット」が頻繁に使われ、あたかも組織モデルの一般的な名称のように感じられるようになりました。
そのような中、今年2月、当社で新たなサービス「Goalous」をリリースしました。
「Goalous」はゴールコラボレーションツールで、当社の社員全員がお互いの目標と日々のアクティビティをオープンに知ることができます。そして、「バリフラット」な組織においては「Goalous」がかなり有益なものです。
私たちとしては、この機会に「Goalous」だけでなく、「バリフラット」をもっと世の中に知ってほしい!という想いから、商標登録することに決めました。
登録することを決めたら、さっそく、登録可能かどうかの調査へ。
調査の結果、誰も出願・登録をしていなかったので、手続き自体は、スムーズに。
そして、7月8日、「バリフラット」が商標登録されたのです。
バリフラットに対する想い

「バリフラット」という言葉が誕生したのは、前述のとおり2015年9月28日。 1年前には、世の中にはなかった言葉です。
その言葉がこうして商標登録されるのは、ネーミング案をとりまとめ、また商標登録手続きを主導した者として感慨深いものがありますね。
世の中には、様々な組織モデルが存在し、バリフラットモデルの組織体に類似する組織モデルのすでにあります。最近ですと、EC最大手のザッポス導入している「ホラクラシ―型組織」が注目されています。
「ホラクラシー」(holacracy)とは、従来の中央集権型・階層型のヒエラルキー組織に相対する新しい組織形態を示す概念で、階級や上司・部下などのヒエラルキーがいっさい存在しない、真にフラットな組織管理体制を表します
引用:「ホラクラシー」とは? - 『日本の人事部』 https://jinjibu.jp/keyword/detl/725/
「バリフラット」と「ホラクラシ―」の違いがなんなのか? ということを聞かれることもありますが、「バリフラット」モデルを導入して1年経っておらず、まだ試行錯誤な状況。 ホラクラシ―型組織と比較するのもおこがましいです。。。
ただ、いつの日か、「バリフラット」が組織モデルとして世の中で称されるときがくるといいなぁと思います。 ただ、それ以上に、「バリフラット」な組織で、当社が成長し、世の中にはなくてはならない企業にしていきたい。
オリンピックウィークは、スーパーフレックス!
...リオ五輪、開幕!
みなさん、寝不足になりながらオリンピック見てますか? 日本勢はすでに10個以上のメダル (8/9 AM現在) を獲得し、盛り上がっていますね。 特に日本がメダル取れそうな種目はライブで観たいですよね!
『リオは地球の真裏で、時差が12時間。今回のオリンピックは週末以外、観戦するのが結構難しいよね。。』
そんな話を今週月曜日に、社員の一人が言い出して、ISAOでは急遽こうすることにしました。
オリンピック期間はスーパーフレックス!
この際フレックスのコアタイムとか完全に無視して、 自慢のジョイフルスタジオで、パブリックビューイングしよう!となりました。
第1回パブリックビューイング
早速、今日は10時過ぎから競泳 男子200m 自由形 決勝を観戦!


残念ながら荻野選手は7位でしたが、みんなでわいわい観戦、とても楽しい時間となりました。
この制度を始めるとき
思い立って5分で決めて、社内にマイク持ってアナウンスしたら、思いもよらない大拍手をしてもらいました。
普段のプレゼンの時には、拍手なんてされないので、嬉しいけれど複雑な気持ちになりましたが (笑)
これはいいと思ったので、今後もW杯のときや、その他重要な大会があるときは、パブリックビューイング@ISAO、どんどんやっていきたいと思います。
リモートワークと未来
...気がつくと子供が4人になっていた。
こんにちは。プログラマーの古山です。
上から8歳、5、1、1。驚くべきことに下の二人は双子ちゃん。
日本が抱えるトッププライオリティな問題、少子化への貢献を考えれば手厚いサポートを期待してもバチはあたらないのではないか。。と思いつつ現実は厳しいのです。
私も妻の実家も遠く離れて親パワーには頼れない現状。
二人でなんとかしなければならないんだけど、まあ小学校にあがるまでは急に熱だして保育園に預かってもらえなくなったり、熱が1日で治るとかなにそれどこのファンタジーだし、そのうち有休尽きたりとか、非常にしんどくつらいです。
そもそも子育てに対しクリティカルな形で父親が関わる事に対し、社会の理解がまだまだ足りていない、具体的には仕事は常にトッププライオリティ。
トラブルがあるなら残業してリカバーするのが当然という空気がそこはかとなく漂っています。
この空気が残っているうちは、母親は父親をあてにすることができず結局負担は減らず、家庭崩壊の危機です。
話によれば、小学校入ってからも危機は続くらしい。恐るべし。
そして真に恐るべしなのはけっして我が家だけではなくこれが日本のふつーの子育て風景だということ。
弊社所属三児のママがリコメンドしてくれた記事 涙無くしては読めません 小4の壁 http://toyokeizai.net/articles/-/126281
これが少子化の国、日本のリアル。
そんな崩壊まっしぐらな我が家に、会社が救いの手を差し伸べてくれました。 それが、リモートワーク。
リモートワークのメリット
通勤時間が短くなる
通勤に2時間弱かかっていたが半分以下に。の時間を双子の相手にまわせばみんなにっこり。 いや幼児なんで起きてる時間の半分くらいは泣きまくりなんですけれども。
通勤時間を基準に考えれば在宅がベストなんですが、家にはいろいろ誘惑が多いのです。 それはもういろいろ。また家に居るんだから病気の子供を看病しながらだって仕事できるぜ!といいつつ、だいたい幼児は熱があるだけであってむしろ保育園に行きたくないからわざと熱出しているんじゃないかと思うほど元気にころげまわるので、実際は仕事なぞできるはずもなく。
なにもできないまま、翌日のカタストロフを迎える….なんて未来予想図を避けるためにもリモートワークなのです。これ大事。
集中できる
話しかけられない。 毎日続くと人恋しくなって自分から見ず知らずの人に話しかけにいっちゃうんじゃないかと思うほどの孤独。 それでいて周囲には働いている人々。 適度な背景としてのホワイトノイズ。これだけでゾーンに入れる確率30%アップ。
確率が上がるだけで確実に入れるわけではないんだけれども。 使っているコワーキングスペースの椅子は若干硬いがそれ以上の価値が有る、と思います。
全社会議に最前列で参加できる
会議はどうすんねん!という当たり前な疑問にも弊社バックオフィスチームはぬかりなく対応しております。 ツールはSkype for Buinness。 そのカメラを最前列に設置して頂いているため誰よりも前の席でプレゼンを鑑賞できるという、たぶん誰も思っても見なかったリモートワークのメリット。

知らないクラスタの人々と知り合いになれる、かもしれない
どうも個人事業主クラスタの方々が多いと思われる私が使っている空間。 イベントも数多く企画されている。 エンジニアという人種はその仕事の本質的に内向的だったりする人が多いんじゃないかと思いますが、強制的にフラグを立てるチャンスが多いんじゃないでしょうか。
きっと会社のオフィスに閉じこもっていてはありえなかった出会いがある、、、と妄想中。
仕事の未来はこの先にあるという確信
実はこれが一番大事だと思っています。
今はまだ子育てや介護世代向けのソリューションという位置づけですが、場所や時間に囚われない、国を、言語を、Timezoneすらまたいでチームを組んで働くという未来は、会社組織が順調に成長すれば必ずやってくる避けうることのできない確定した事項です。 そうでなくても日本語市場は減少の一途なわけですし、海外市場をターゲットにするためにもチームのグローバル化は必須でしょう。
仮に日本というドメスティックなエリア内に限定しても、過疎化する地方を活性化するためにリモートワークが強力な力を発揮することでしょう。
さらば満員の通勤電車。さらば過密のメガロポリス。
ヨーロッパで最もクールなTechカンファレンス『Tech Open Air 2016』参加レポート
...先日の女1人でも怖くない、『世界に触れる旅』3つの極意に反響をいただき、ありがとうございます!
今回は、予告したイベントレポートです。
45秒でわかるTOA
2016年7月13日(水)〜15日(金) ドイツ・ベルリンでおこなわれたTech Open Air 2016に参加してきました!
ショートムービーを作ってみたので、まずはこちらで雰囲気をご覧ください。
Tech Open Air とは?
『ヨーロッパで最もクールなTechカンファレンス』 とも言われるこのイベント。 http://toa.berlin/
ヨーロッパのスタートアップを牽引しているドイツのベルリンで開かれます。
公式のOverviewでもわかるように、 2012年にスタートした比較的新しいカンファレンスですが、毎年急拡大しています。
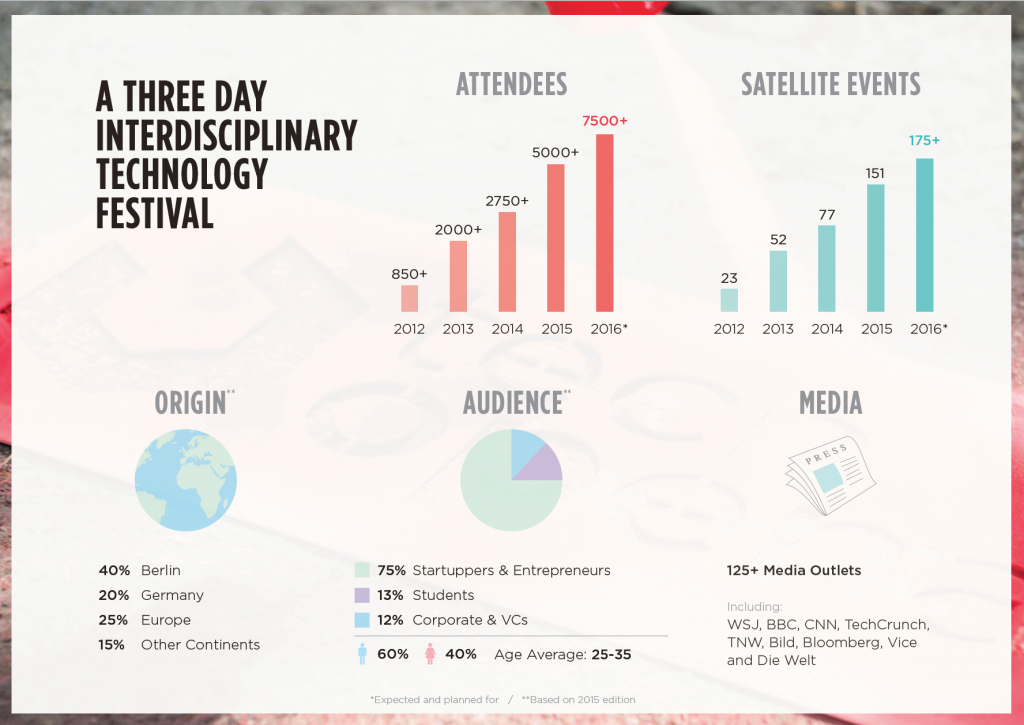 引用元:http://toa.berlin/wp-content/uploads/2016/06/TOA16_overview_X.compressed.pdf
引用元:http://toa.berlin/wp-content/uploads/2016/06/TOA16_overview_X.compressed.pdf日本人は、ゼロではありませんがほとんど見かけませんでした。
現地でお会いしたGoodpatchさんのベルリンオフィスで働くお2人もドイツの方です。

参加費は?
私は最も早いEarly Birdで3月に購入したので、€237(税・手数料込み)でした。 この手のカンファレンスの中ではかなり安いほうですね。
最終的には€450以上になるので、早めに購入がおすすめです。
Early Birdだと€10相当のフードチケットももらえ、ランチ代も浮かせることができました。
会場は?
年によって違うようですが、今年はFunkhaus Berlin。
1956~1990の間、東ドイツの放送局だったそうで、クラシカルな雰囲気漂うホール。
建物内に4つ、中庭に2つの会場があります。

公式アプリでスケジュールを確認しながら、中と外をうろうろ。
サテライト以外は1つの会場内での行き来なので、とても楽です。
『Open Air』の名前のとおり、外は開放的でまるでアウトドアフェス!

SXSWがTech業界のFUJI ROCK FESTIVALだとすると、TOAはNatural High Campって感じです。 (フェス好きの人ならわかるはず!)
第3回外部向け勉強会『React+Reduxで作るSPA』を開催しました
...初めまして、SMAPリーダーの吉岡真人です。
SMAPって何? ・ ・ ・ ですよね??? Sales&Marketing Projectを無理して略してSMAPですw
91年生まれの若手エンジニアが登壇
今回のテーマはReact+Reduxで作るSPA
ISAOへ入社して1年が経った弊社若手エンジニア@saekis が、なんと自ら手を挙げて登壇いたしました(^^)!

前日風邪をひいてしまい、延期した当日の事前練習はトーン低めでしたが何とかやり抜きました。
本番に強い男だな (ホッ)
当日使用した資料はこちら。
受付〜開始時間まで、自慢の社内バーカウンターで、Welcomeドリンクが出るというスタイル!

私自身、初めて体験しましたが、頭が少し柔らかくなり、なかなか良いですね。
もっともっと良くなる勉強会に、どんどんチャレンジしていきたくなりました。
ISAO Meetup名物『今月のミート』は!?
そして勉強会後の楽しみになってきました、懇親会の肉メニュー。
今回はSMAPリーダーとして負けられないチョイス。
知る人しか知らない近所のとんかつ藤芳です~
Pokemon GOのポケストップにも出ていますよ!
勉強会の予約人数通り購入したら、いっぱい余ったああああ(TT) もっともっと魅力ある勉強会とISAOになるぞおおおお
次回は8月下旬開催予定です。お楽しみに!
女1人でも怖くない、『世界に触れる旅』3つの極意
...こんにちは、中嶋あいみです。
先日、人事の市橋がアップしていた夏休み9日間休んだら1万円制度で、 土日祝を含めた10連休を取って、ヨーロッパに行ってきました。
1人でww

主な目的は、ベルリンで開催されるTech Open Airに参加すること!
参加レポートは別記事で書きますね。
私の海外経験
今まで海外は12年で20回以上、17ヶ国くらい行ってますが、 1人旅は、これで5回目。
チェンマイ(タイ)、ニューヨーク、ヘルシンキ(フィンランド)&チェコ、台湾、
そして今回のベルリン&ヘルシンキ。
全部が旅行で、留学とかはしたことありません。
最大でも9日間くらいです。
1人旅が好きなんでしょ?バックパッカー的な?
『海外1人旅なんてすごいね。かっこいい!』
とか言われ、よく誤解されるのですが、 決して1人旅が好きなわけではありません。
予定が合って一緒に楽しめる人がいたら、誰かと行きたいです、切実にww
今までだって、彼氏と行ったビーチリゾートや、友達と豪遊した韓国なんかのほうが、思い出としては断然楽しかったです。
ではなぜ1人で行くのか、理由は1つ。
少しでも多くの世界に触れたい。1人でもいいから。
海外1人旅は、思い出にはならないけど、経験にはなる。 誰にも気兼ねなく時間もお金も使えるうちに、フットワークを軽く動こうと心がけています。
これらの経験のおかげで、だいぶ考え方や生き方に自分らしさを持てるようになったと思います。
世界に触れることの意義
私の場合、この3つに価値をおいています。
- 外国人になるアウェイ感を楽しむ
- 日本、東京の良し悪しがわかる
- 英語の腕試し
外国人になるアウェイ感

海外に行くと、常識がひっくり返る。
この感覚は、写真を見たり、本で読んだりの知識では体感できないものです。
32歳の大人が、初めての国や街に行くと 電車の切符を買うのも、目的地に時間通りに行くのも、一苦労。
スマホの充電やWifiが切れてしまったら、オフラインで人に聞くしかありません。
実は今回、成田空港に行く途中にiPhoneが壊れて、初めから前途多難な旅でした。
現地の人に助けられた経験が何度もあるから、東京にも多くいる外国人観光客に、何か困ってそうだったら助けるようにしています。
日本、東京の良し悪しがわかる
同じ民族・同じ常識概念の集団から離れてみると、見えなかったものが見えてきます。
日本は世界でかなり上位の清潔な国だし、無くしたお財布やスマホが出てくることもしばしば。
食事の種類が多くレベルも高いし、24時間コンビニで物が買え、昼も夜も娯楽にあふれて退屈することがない。
1人当たりのGDPで言うと、今やシンガポールのほうが上だし、日本がアジアのNo.1だとは思っていないですが、 日本ほど水回りが快適な国はないと思うし、生活面での暮らしやすさは最高水準だと思います。
一方で、コミュニケーション文化では日本以外のほうが居心地よく感じます。
- 目を見て話す
- 言わなきゃ伝わらない
- 知らない人同士でも目があったら微笑む
- 名刺交換はマストじゃないし、始めにしない
とかは、海外のほうがいいなぁ、働きたいなぁとか思ったりします。
『仕事がたのしい!』の原動力
...シゴトたのしい?
みなさん、シゴト楽しんでますか?

「シゴトをたのしくするビジョナリーカンパニー」
ISAOの2020年ビジョンです。
みんなをたのしくする前に、自分たちがたのしむ。 これがISAO流です。
どうしたらシゴトを楽しめるか
では、どうしたらシゴトが楽しくなるのでしょう。
学生の頃のアルバイトは「シゴトが楽 (ラク) で、時給がいっぱいもらえるといいな〜」と僕は思ってました。
社会人としてのシゴトも同じでしょうか?
学生のバイトと、社会人のシゴトの違いは、学生のシゴトと違って社会人のシゴトは「長期間」であるということです。
短期間でたのしい!のであれば、周りの人と仲が良かったり、職場の施設が充実していたり、 そんなにストレスなく、叱られることもなく、ワイワイやっていればいい。
ただ、それだけで「長期間」楽しくやり続けられるでしょうか?
環境が良くても、10年前にできたことを今日もやってるようなシゴトって、楽しいでしょうか。
シゴトがたのしい!の原動力
スポーツや趣味でも、ビギナーとしてやっていることをずっとやっていても楽しくなくなってきます。
練習して、成長して、段々レベルが高くなっていく。
そのうちに難しいこと、以前にできなかったことができるようになって、何かを達成したときに一番の『たのしい!』が訪れます。
シゴトも同じです。
「成長」と「達成」が、たのしい!の原動力だと僕は思います。
では、成長と達成があれば、会社はどこでもいいのか?
そうでもなさそうです。
ではどこで働くのか?
次のブログでそれを考えてみたいと思います。
How ISAO works ~Super Flat Organization
...Introduction
Hi! My name is Keiji Nakamura, CEO/Managing Director here at ISAO.
 Since this is my first post in ISAB, I’d like to explain how our company works in organization point of view. As of October 1st, ISAO is operating under the ‘Super Flat Organization l: 0 management, 0 hierarchy, maximize team power!
Since this is my first post in ISAB, I’d like to explain how our company works in organization point of view. As of October 1st, ISAO is operating under the ‘Super Flat Organization l: 0 management, 0 hierarchy, maximize team power!