
MHAの動作確認と切替検証
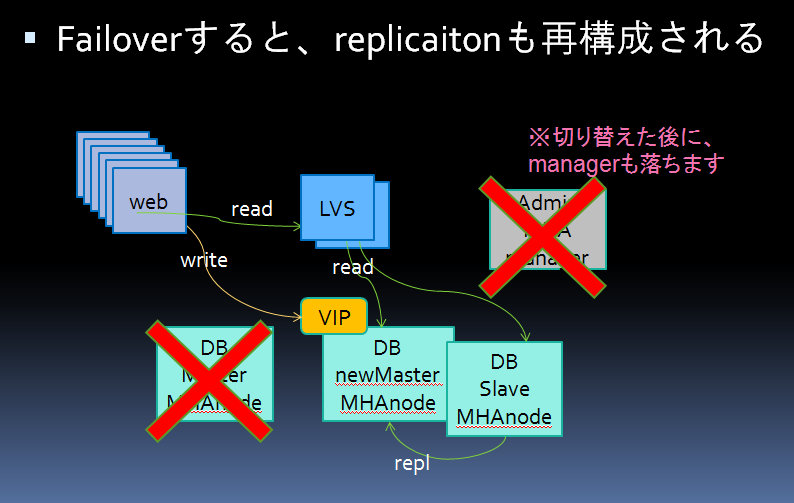
前回のつづきです。以下の図のように切り替わるようテストします。
{kind=link}
 ※本検証はマスタ1台、スレーブ2台、マネージャ1台構成。(多段構成は中間ノード障害時の復旧が猥雑になるので回避)
※本検証はマスタ1台、スレーブ2台、マネージャ1台構成。(多段構成は中間ノード障害時の復旧が猥雑になるので回避)
スレーブにmanagerを同居させるとpurge_relay_logsとかぶると上手く切り替わらない可能性があるようです。
※2台しかない場合で上手く切り替わらないことがあるようです。以下参考。
http://heartbeats.jp/hbblog/2013/05/mysql-mha-haproxy.html
⑥ 起動前チェック
・sshの動作チェック
[shell] # masterha_check_ssh –conf=/etc/app1.cnf [/shell] OKな場合最終的に以下のように出力される
[shell] Tue Oct 23 15:02:22 2012 - [info] All SSH connection tests passed successfully. [/shell]
・replicationの動作チェック
[shell] # masterha_check_repl –conf=/etc/app1.cnf [/shell] OKな場合最終的に以下のように出力される(※mysql5.6からはMHAのバージョンによってはbinlog-checksum=NONEにしないとここで失敗するかもしれません)
[shell] MySQL Replication Health is OK. [/shell] ※失敗するパターン
レプリケーションのフィルタリングルールが合っていない
LVSとMHAマネージャが相乗りの場合、チェックタイミングが重複しホスト毎DBサーバに拒否されてしまう(要flush hosts;)
⑦更新VIP用IFファイルを確認
db01/db02
[shell] cat /etc/sysconfig/network-scripts/ifcfg-eth1:0 ===================================================== # Intel Corporation 82576 Gigabit Network Connection DEVICE=eth0:0 BOOTPROTO=static BROADCAST=192.168.100.255 #HWADDR= IPADDR=192.168.100.5 NETMASK=255.255.255.0 NETWORK=192.168.100.0 ONPARENT=no ===================================================== [/shell] ※仮想IFの場合ONBOOTでは反応しないのでONPARENT=noを指定する。
db01
[shell] # ifup eth1:0 [/shell]
⑧ MHAマネージャの起動と確認・停止
・マネージャの起動
[shell] # masterha_manager –conf=/etc/app1.cnf & [/shell] ※失敗するパターン
レプリケーション構成が崩れている
すでに切り替わっていて完了を示すステータスファイルが出力されている
マネージャを起動したターミナルでログをtailで見てたりするとうまく切り替わらないので注意。
・マネージャのステータスチェック
[shell] # masterha_check_status –conf=/etc/app1.cnf [/shell] 以下のようにでればok
[shell] app1 (pid:9883) is running(0:PING_OK), master:192.168.100.1 [/shell] とまっている場合以下のように出力される
[shell] app1 is stopped(2:NOT_RUNNING). [/shell] 起動直後の初期化ステータスの場合はそのように出力される。
※この状態が長く続く場合kill -9で強制停止の必要が生じることがある
・マネージャの停止
[shell] # masterha_stop –conf=/etc/app1.cnf
# masterha_check_status –conf=/etc/app1.cnf [/shell] ・マネージャが初期化状態のまま止めてもとまらなかったら
[shell] # ps -ef|grep master [/shell] プロセスIDをコピー
[shell] # kill -9
[shell] # masterha_check_status –conf=/etc/app1.cnf # ls -l /var/log/masterha/app1/ [/shell] もしステータスファイルが残っていたら削除する
■MHA切替テストと確認・復旧■
※データ更新して切替テストは省略。主にマスタを落として切り替わるかの確認です。slave落として切り替わらない等も追加で確認してもよいと思います。
① 切替テスト
・事前確認
[shell] # tail -f /var/log/masterha/app1/manager.log # masterha_check_status –conf=/etc/app1.cnf # ls -lh /var/log/masterha/app1/ # masterha_check_repl –conf=/etc/app1.cnf [/shell] ・mysqldを落とすテスト
旧マスタにて
[shell] # service mysqld stop # service mysqld status [/shell] mysqldがstopしてることを確認
・インターフェースを落とすテスト
旧マスタにて
[shell] # ifdown eth1 # ifdown eth1:1 [/shell] ・mysqldのポートを閉じるテスト
旧マスタにて
[shell] # iptables -P INPUT ACCEPT # iptables -A INPUT -p tcp –dport 3306 -j DROP # netstat -lnpt [/shell] 基本的に全てのインバウンドパケットを受け付け
TCPのポート3306宛のパケットをドロップ
3306ポートが閉じたことを確認
② 確認
・MHAマネジャの状態を確認
[shell] # tail -f /var/log/masterha/app1/manager.log # masterha_check_status –conf=/etc/app1.cnf # ls -lh /var/log/masterha/app1/ [/shell] app1.failover.completeという切替完了ファイルの存在を確認
・VIPが切り替わったか確認
新旧マスタにて
[shell] # ifconfig -a [/shell] 旧マスタから更新VIPが外れて新マスタに更新VIPが移ったことを確認
・新マスタのスレーブが停止していてスレーブが新マスタを見ていることを確認
[sql] > show slave status\G [/sql] 新マスタのSlave_*_RunningがNoになっていることを確認
スレーブのMaster_Host:が新マスタを向いていることを確認
[sql] > show global variables like ‘read_only’; [/sql] 新マスタはOFFになっており更新が可能なことを確認
・LVSサーバのweightが想定通りになっていることを確認する (LVS01)
[shell] # ipvsadm -L –sort # ls -la /etc/ha.d/ldirectord.cf* [/shell] YYYYMMDD.HHMM のファイルがバックアップされていることを確認
[shell] # diff /etc/ha.d/ldirectord.cf{,.failover} [/shell] 差分がないことを確認(failoverファイルが正常に上書きされていることを確認)
③構成復旧
・旧マスタのmysqldを起動
[shell] # netstat -lnpt # service mysqld start # service mysqld status [/shell] ・旧マスタ(DB01)のインターフェースを起動
[shell] # ifup eth1 # ifconfig [/shell] ・旧マスタのポートブロックを初期化
[shell] # service iptables restart # iptables -Ln [/shell] ・replication構成の復旧(※データの差分がある場合はdumpして差分投入が必要)
旧マスタにて
[sql] # mysql -u root -p`cat /path_to_file` > reset master; > show master status; > show slave status\G [/sql] 新マスタとスレーブにて
[sql] # mysql -u root -p`cat /path_to_file` > show global variables like ‘read_only’; > set global read_only=1; > stop slave; > reset slave; > CHANGE MASTER TO MASTER_HOST=‘192.168.100.1’, MASTER_USER=‘repl’, MASTER_PASSWORD=’*******’, MASTER_LOG_FILE=‘mysql-bin.000001’, MASTER_LOG_POS=106; > start slave; > show slave status\G [/sql] ・LVSサーバのweightをもとに戻す
[shell] # ls -la /etc/ha.d/ldirectord.cf* [/shell] YYYYMMDD.HHMM のファイルを確認
[shell] # mv /etc/ha.d/ldirectord.cf.YYYYMMDD.HHMM /etc/ha.d/ldirectord.cf [/shell] ・不要ファイル削除
[shell] # ls -lh /var/log/masterha/app1/ # rm -f /var/log/masterha/app1/app1.failover.complete # rm -f /var/log/masterha/app1/app1.failover.error # rm -f /var/log/masterha/app1/saved_master_binlog_from_192* [/shell] 切替完了ファイルを削除
切替異常終了ファイルを削除
旧マスタのバイナリログバックアップを削除
※試験環境なので消している
・更新VIPの手動付け替え
新マスタ
[shell] # ifdown eth1:0 # ifconfig eth1:0 [/shell] IPがついていないことを確認
旧マスタ
[shell] # ifup eth1:0 # ifconfig eth1:0 [/shell] IPがついていることを確認
もしAWSのVPC上であれば、aws的にプライベートアドレスの付替えもしないと外部からアクセスできなくなります。
ec2-unassign-private-ip-addresses –network-interface eni-7060xxxx –secondary-private-ip-address (PrivateIP)
ec2-assign-private-ip-addresses –network-interface eni-4b64xxxx –secondary-private-ip-address (PrivateIP)
・MHAマネジャの再起動
確認
[shell] # masterha_check_repl –conf=/etc/app1.cnf # masterha_check_status –conf=/etc/app1.cnf [/shell] 起動
[shell] # masterha_manager –conf=/etc/app1.cnf & # masterha_check_status –conf=/etc/app1.cnf # tail -f /var/log/masterha/app1/manager.log # ls -lh /var/log/masterha/app1/ [/shell] ・MHAマネージャが長い間初期化状態のままだった場合
[shell] # masterha_stop –conf=/etc/app1.cnf [/shell] このコマンドが失敗するようなら強制kill。
[shell] # masterha_check_status –conf=/etc/app1.cnf # ps -ef|grep master [/shell] プロセスIDをコピーしてkillコマンドに指定
[shell] # kill -9
・MHAマネージャが落ちていてマスタ(と更新用VIP)を手動切替したい場合
[shell] # masterha_master_switch –master_state=alive –conf=/etc/app1.cnf [/shell] ※ほんとにやっていいか聞かれるので承諾する。MHAマネージャが起動してると落とせと怒られる。
(※VIPは処理を追加しないと切り替わらない)
詳しくはこちらを参照ください
もしVIPも切替えたい場合は以下の差分のように修正する(IF情報は環境に合わせてください)
[shell] ========================== 33,40d32 < my $vip = ‘192.168.0.245/24’; # Write Virtual IP < my $key = “0”; < my $ssh_start_vip = “/sbin/ifconfig eth0:$key $vip”; < my $ssh_stop_vip = “/sbin/ifconfig eth0:$key down”; < my $ssh_user = “root”; < my $orig_master_host = “192.168.0.248”; < my $new_master_host = “192.168.0.249”; < 47c39 < ‘master_state=s’ => \$master_state, — > ‘master_state=s’ => \$master_state 50,58d41 < # A simple system call that enable the VIP on the new master < sub start_vip() { < `ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`; < } < # A simple system call that disable the VIP on the old_master < sub stop_vip() { < `ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`; < } < 72,76d54 < if ( $exit_code eq 0 ) { < &stop_vip(); < sleep 1; < &start_vip(); < } 80,84d57 < if ( $exit_code eq 0 ) { < &stop_vip(); < sleep 1; < &start_vip(); < } ========================== [/shell] ・secondaryが生きているか確認
[shell] # masterha_secondary_check -s 192.168.0.249 –user=root –master_host=test-db02 –master_ip=192.168.0.245 –master_port=3306 [/shell] ※-sの後ろを追加すれば複数確認できる
■参考資料■
・MHAの動作フェーズ
[shell] # grep Phase manager.log |head -20|grep -v completed * Phase 1: Configuration Check Phase.. * Phase 2: Dead Master Shutdown Phase.. * Phase 3: Master Recovery Phase.. * Phase 3.1: Getting Latest Slaves Phase.. * Phase 3.2: Saving Dead Master’s Binlog Phase.. * Phase 3.3: Determining New Master Phase.. * Phase 3.3: New Master Diff Log Generation Phase.. * Phase 3.4: Master Log Apply Phase.. * Phase 4: Slaves Recovery Phase.. * Phase 4.1: Starting Parallel Slave Diff Log Generation Phase.. * Phase 4.2: Starting Parallel Slave Log Apply Phase.. * Phase 5: New master cleanup phease.. [/shell]
フェイルオーバ時の動作は以下のとおり。(ログから追った動き)
※SQL処理のスレッド実行が終わった後
①config(/etc/app1.cnf)から各ノード情報を読み込む
②newMasterのVIPを停止する
③newMasteのmysqldを停止
④各Slaveリレーログを解析して次マスターの選出と差分位置を特定
⑤oldMasterにアクセス可能であればバイナリーログをローカルに(/var/log/masterha/app1)コピーする
⑥⑤で引き上げた最新のバイナリーログをnewMaster(/var/log/masterha/app1)にコピー
⑦oldMasterとの差分をnewMasterで更新
⑧newMasterにVIPを付与する
⑨newMasterのread-onlyを解除
⑩⑤で引き上げた最新のバイナリーログをnewSlave(/var/log/masterha/app1)にコピー
⑪oldMasterサーバとの差分をnewSlaveで更新
⑫newSlaveで最新のバイナリーログとrelayログとの差分を確認して適用
⑬newSlaveのMasterをoldMasterサーバからnewMasterサーバに変更しreplication再開
⑭managerにてapp1.failover.completeを/var/log/masterha/app1に出力してmasterha_managerを停止する
・エラーメッセージと意味
これはmanagerが2重に起動したときに出るログ。
Wed May 29 16:02:19 2013 - [error][/usr/lib/perl5/vendor_perl/MHA/ServerManager.pm, ln917]
Getting advisory lock failed on 10.0.0.86(10.0.0.86:3306). Maybe failover script or purge_relay_logs script is running on the same slave?
Wed May 29 16:02:19 2013 - [error][/usr/lib/perl5/vendor_perl/MHA/ManagerUtil.pm, ln178] Got ERROR:
at /usr/lib/perl5/vendor_perl/MHA/MasterFailover.pm line 305
これは完了ファイルがあるときのエラー
Fri May 24 11:46:01 2013 - [error][/usr/lib/perl5/vendor_perl/MHA/ManagerUtil.pm, ln178] Got ERROR:
at /usr/bin/masterha_manager line 65
以上。ご覧いただきありがとうございました!
MHAの動作確認と切替検証
前回のつづきです。以下の図のように切り替わるようテストします。
※本検証はマスタ1台、スレーブ2台、マネージャ1台構成。(多段構成は中間ノード障害時の復旧が猥雑になるので回避)
スレーブにmanagerを同居させるとpurge_relay_logsとかぶると上手く切り替わらない可能性があるようです。
※2台しかない場合で上手く切り替わらないことがあるようです。以下参考。
http://heartbeats.jp/hbblog/2013/05/mysql-mha-haproxy.html
⑥ 起動前チェック
・sshの動作チェック
[shell] # masterha_check_ssh –conf=/etc/app1.cnf [/shell] OKな場合最終的に以下のように出力される
[shell] Tue Oct 23 15:02:22 2012 - [info] All SSH connection tests passed successfully. [/shell]
・replicationの動作チェック
[shell] # masterha_check_repl –conf=/etc/app1.cnf [/shell] OKな場合最終的に以下のように出力される(※mysql5.6からはバイナリログフォーマット他変更点が多いためかここで失敗します)
[shell] MySQL Replication Health is OK. [/shell] ※失敗するパターン
レプリケーションのフィルタリングルールが合っていない
LVSとMHAマネージャが相乗りの場合、チェックタイミングが重複しホスト毎DBサーバに拒否されてしまう(要flush hosts;)
⑦更新VIP用IFファイルを確認
db01/db02
[shell] cat /etc/sysconfig/network-scripts/ifcfg-eth1:0 ===================================================== # Intel Corporation 82576 Gigabit Network Connection DEVICE=eth0:0 BOOTPROTO=static BROADCAST=192.168.100.255 #HWADDR= IPADDR=192.168.100.5 NETMASK=255.255.255.0 NETWORK=192.168.100.0 ONPARENT=no ===================================================== [/shell] ※仮想IFの場合ONBOOTでは反応しないのでONPARENT=noを指定する。
db01
[shell] # ifup eth1:0 [/shell]
⑧ MHAマネージャの起動と確認・停止
・マネージャの起動
[shell] # masterha_manager –conf=/etc/app1.cnf & [/shell] ※失敗するパターン
レプリケーション構成が崩れている
すでに切り替わっていて完了を示すステータスファイルが出力されている
マネージャを起動したターミナルでログをtailで見てたりするとうまく切り替わらないので注意。
・マネージャのステータスチェック
[shell] # masterha_check_status –conf=/etc/app1.cnf [/shell] 以下のようにでればok
[shell] app1 (pid:9883) is running(0:PING_OK), master:192.168.100.1 [/shell] とまっている場合以下のように出力される
[shell] app1 is stopped(2:NOT_RUNNING). [/shell] 起動直後の初期化ステータスの場合はそのように出力される。
※この状態が長く続く場合kill -9で強制停止の必要が生じることがある
・マネージャの停止
[shell] # masterha_stop –conf=/etc/app1.cnf
# masterha_check_status –conf=/etc/app1.cnf [/shell] ・マネージャが初期化状態のまま止めてもとまらなかったら
[shell] # ps -ef|grep master [/shell] プロセスIDをコピー
[shell] # kill -9
[shell] # masterha_check_status –conf=/etc/app1.cnf # ls -l /var/log/masterha/app1/ [/shell] もしステータスファイルが残っていたら削除する
■MHA切替テストと確認・復旧■
※データ更新して切替テストは省略。主にマスタを落として切り替わるかの確認です。slave落として切り替わらない等も追加で確認してもよいと思います。
① 切替テスト
・事前確認
[shell] # tail -f /var/log/masterha/app1/manager.log # masterha_check_status –conf=/etc/app1.cnf # ls -lh /var/log/masterha/app1/ # masterha_check_repl –conf=/etc/app1.cnf [/shell] ・mysqldを落とすテスト
旧マスタにて
[shell] # service mysqld stop # service mysqld status [/shell] mysqldがstopしてることを確認
・インターフェースを落とすテスト
旧マスタにて
[shell] # ifdown eth1 # ifdown eth1:1 [/shell] ・mysqldのポートを閉じるテスト
旧マスタにて
[shell] # iptables -P INPUT ACCEPT # iptables -A INPUT -p tcp –dport 3306 -j DROP # netstat -lnpt [/shell] 基本的に全てのインバウンドパケットを受け付け
TCPのポート3306宛のパケットをドロップ
3306ポートが閉じたことを確認
② 確認
・MHAマネジャの状態を確認
[shell] # tail -f /var/log/masterha/app1/manager.log # masterha_check_status –conf=/etc/app1.cnf # ls -lh /var/log/masterha/app1/ [/shell] app1.failover.completeという切替完了ファイルの存在を確認
・VIPが切り替わったか確認
新旧マスタにて
[shell] # ifconfig -a [/shell] 旧マスタから更新VIPが外れて新マスタに更新VIPが移ったことを確認
・新マスタのスレーブが停止していてスレーブが新マスタを見ていることを確認
[sql] > show slave status\G [/sql] 新マスタのSlave_*_RunningがNoになっていることを確認
スレーブのMaster_Host:が新マスタを向いていることを確認
[sql] > show global variables like ‘read_only’; [/sql] 新マスタはOFFになっており更新が可能なことを確認
・LVSサーバのweightが想定通りになっていることを確認する (LVS01)
[shell] # ipvsadm -L –sort # ls -la /etc/ha.d/ldirectord.cf* [/shell] YYYYMMDD.HHMM のファイルがバックアップされていることを確認
[shell] # diff /etc/ha.d/ldirectord.cf{,.failover} [/shell] 差分がないことを確認(failoverファイルが正常に上書きされていることを確認)
③構成復旧
・旧マスタのmysqldを起動
[shell] # netstat -lnpt # service mysqld start # service mysqld status [/shell] ・旧マスタ(DB01)のインターフェースを起動
[shell] # ifup eth1 # ifconfig [/shell] ・旧マスタのポートブロックを初期化
[shell] # service iptables restart # iptables -Ln [/shell] ・replication構成の復旧(※データの差分がある場合はdumpして差分投入が必要)
旧マスタにて
[sql] # mysql -u root -p`cat /path_to_file` > reset master; > show master status; > show slave status\G [/sql] 新マスタとスレーブにて
[sql] # mysql -u root -p`cat /path_to_file` > show global variables like ‘read_only’; > set global read_only=1; > stop slave; > reset slave; > CHANGE MASTER TO MASTER_HOST=‘192.168.100.1’, MASTER_USER=‘repl’, MASTER_PASSWORD=’*******’, MASTER_LOG_FILE=‘mysql-bin.000001’, MASTER_LOG_POS=106; > start slave; > show slave status\G [/sql] ・LVSサーバのweightをもとに戻す
[shell] # ls -la /etc/ha.d/ldirectord.cf* [/shell] YYYYMMDD.HHMM のファイルを確認
[shell] # mv /etc/ha.d/ldirectord.cf.YYYYMMDD.HHMM /etc/ha.d/ldirectord.cf [/shell] ・不要ファイル削除
[shell] # ls -lh /var/log/masterha/app1/ # rm -f /var/log/masterha/app1/app1.failover.complete # rm -f /var/log/masterha/app1/app1.failover.error # rm -f /var/log/masterha/app1/saved_master_binlog_from_192* [/shell] 切替完了ファイルを削除
切替異常終了ファイルを削除
旧マスタのバイナリログバックアップを削除
※試験環境なので消している
・更新VIPの手動付け替え
新マスタ
[shell] # ifdown eth1:0 # ifconfig eth1:0 [/shell] IPがついていないことを確認
旧マスタ
[shell] # ifup eth1:0 # ifconfig eth1:0 [/shell] IPがついていることを確認
もしAWSのVPC上であれば、aws的にプライベートアドレスの付替えもしないと外部からアクセスできなくなります。
ec2-unassign-private-ip-addresses –network-interface eni-7060xxxx –secondary-private-ip-address (PrivateIP)
ec2-assign-private-ip-addresses –network-interface eni-4b64xxxx –secondary-private-ip-address (PrivateIP)
・MHAマネジャの再起動
確認
[shell] # masterha_check_repl –conf=/etc/app1.cnf # masterha_check_status –conf=/etc/app1.cnf [/shell] 起動
[shell] # masterha_manager –conf=/etc/app1.cnf & # masterha_check_status –conf=/etc/app1.cnf # tail -f /var/log/masterha/app1/manager.log # ls -lh /var/log/masterha/app1/ [/shell] ・MHAマネージャが長い間初期化状態のままだった場合
[shell] # masterha_stop –conf=/etc/app1.cnf [/shell] このコマンドが失敗するようなら強制kill。
[shell] # masterha_check_status –conf=/etc/app1.cnf # ps -ef|grep master [/shell] プロセスIDをコピーしてkillコマンドに指定
[shell] # kill -9
・MHAマネージャが落ちていてマスタ(と更新用VIP)を手動切替したい場合
[shell] # masterha_master_switch –master_state=alive –conf=/etc/app1.cnf [/shell] ※ほんとにやっていいか聞かれるので承諾する。MHAマネージャが起動してると落とせと怒られる。
(※VIPは処理を追加しないと切り替わらない)
詳しくはこちらを参照ください
もしVIPも切替えたい場合は以下の差分のように修正する(IF情報は環境に合わせてください)
[shell] ========================== 33,40d32 < my $vip = ‘192.168.0.245/24’; # Write Virtual IP < my $key = “0”; < my $ssh_start_vip = “/sbin/ifconfig eth0:$key $vip”; < my $ssh_stop_vip = “/sbin/ifconfig eth0:$key down”; < my $ssh_user = “root”; < my $orig_master_host = “192.168.0.248”; < my $new_master_host = “192.168.0.249”; < 47c39 < ‘master_state=s’ => \$master_state, — > ‘master_state=s’ => \$master_state 50,58d41 < # A simple system call that enable the VIP on the new master < sub start_vip() { < `ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`; < } < # A simple system call that disable the VIP on the old_master < sub stop_vip() { < `ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`; < } < 72,76d54 < if ( $exit_code eq 0 ) { < &stop_vip(); < sleep 1; < &start_vip(); < } 80,84d57 < if ( $exit_code eq 0 ) { < &stop_vip(); < sleep 1; < &start_vip(); < } ========================== [/shell] ・secondaryが生きているか確認
[shell] # masterha_secondary_check -s 192.168.0.249 –user=root –master_host=test-db02 –master_ip=192.168.0.245 –master_port=3306 [/shell] ※-sの後ろを追加すれば複数確認できる
■参考資料■
・MHAの動作フェーズ
[shell] # grep Phase manager.log |head -20|grep -v completed * Phase 1: Configuration Check Phase.. * Phase 2: Dead Master Shutdown Phase.. * Phase 3: Master Recovery Phase.. * Phase 3.1: Getting Latest Slaves Phase.. * Phase 3.2: Saving Dead Master’s Binlog Phase.. * Phase 3.3: Determining New Master Phase.. * Phase 3.3: New Master Diff Log Generation Phase.. * Phase 3.4: Master Log Apply Phase.. * Phase 4: Slaves Recovery Phase.. * Phase 4.1: Starting Parallel Slave Diff Log Generation Phase.. * Phase 4.2: Starting Parallel Slave Log Apply Phase.. * Phase 5: New master cleanup phease.. [/shell]
フェイルオーバ時の動作は以下のとおり。(ログから追った動き)
※SQL処理のスレッド実行が終わった後
①config(/etc/app1.cnf)から各ノード情報を読み込む
②newMasterのVIPを停止する
③newMasteのmysqldを停止
④各Slaveリレーログを解析して次マスターの選出と差分位置を特定
⑤oldMasterにアクセス可能であればバイナリーログをローカルに(/var/log/masterha/app1)コピーする
⑥⑤で引き上げた最新のバイナリーログをnewMaster(/var/log/masterha/app1)にコピー
⑦oldMasterとの差分をnewMasterで更新
⑧newMasterにVIPを付与する
⑨newMasterのread-onlyを解除
⑩⑤で引き上げた最新のバイナリーログをnewSlave(/var/log/masterha/app1)にコピー
⑪oldMasterサーバとの差分をnewSlaveで更新
⑫newSlaveで最新のバイナリーログとrelayログとの差分を確認して適用
⑬newSlaveのMasterをoldMasterサーバからnewMasterサーバに変更しreplication再開
⑭managerにてapp1.failover.completeを/var/log/masterha/app1に出力してmasterha_managerを停止する
・エラーメッセージと意味
これはmanagerが2重に起動したときに出るログ。
Wed May 29 16:02:19 2013 - [error][/usr/lib/perl5/vendor_perl/MHA/ServerManager.pm, ln917]
Getting advisory lock failed on 10.0.0.86(10.0.0.86:3306). Maybe failover script or purge_relay_logs script is running on the same slave?
Wed May 29 16:02:19 2013 - [error][/usr/lib/perl5/vendor_perl/MHA/ManagerUtil.pm, ln178] Got ERROR:
at /usr/lib/perl5/vendor_perl/MHA/MasterFailover.pm line 305
これは完了ファイルがあるときのエラー
Fri May 24 11:46:01 2013 - [error][/usr/lib/perl5/vendor_perl/MHA/ManagerUtil.pm, ln178] Got ERROR:
at /usr/bin/masterha_manager line 65
以上。ご覧いただきありがとうございました!