InternetExplorer11で変更されたUserAgent書式に対応する
...今まで問題なく稼動していたとあるシステムにて、InternetExplorer11(以下IE11)のブラウザにて不具合が発生する旨の報告を受けて調べたところ、IE11ではユーザーエージェントの書式が変更になっていて、ブラウザ判定処理が「不明なブラウザ」として処理されていたことがわかった。
今までユーザーエージェントのブラウザバージョントークン(UAの"MSIE 9.0"とか書いてある部分)でIEブラウザの判定とIEバージョンを取得していたのだが、IE11からはこのブラウザバージョントークンがなくなってしまい、新たに"rv"というリビジョントークンが設けられてました(※IE11標準ブラウザモード)。
今後IE11を含めてユニークにIEを判定するには、ブラウザエンジンであるトライデントトークン(UAの"Trident/7.0"とか書いてある部分)の存在確認もOR条件で判定しないといけなくなった。IE11のUserAgent
- [ブラウザモード:標準] Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; Touch; rv:11.0) like Gecko
- [ブラウザモード:互換表示] Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.3; Trident/7.0)
問題なのが、IEの互換表示モードだ。IEの互換表示モードはIE9から導入された機能だが、このモードにすると現状の全てのIEにおいてUAのブラウザバージョントークンがIE7となってしまう。互換表示の際についても正確にIE11と判定させるには、まずトライデントトークンを先に判定して、トライデントのバージョンが7.0以上だったらIE11として判定しリビジョントークンからブラウザバージョンを取得し、それ以外はブラウザバージョントークンからバージョンを取得するという処理にする必要がある。さらにIE11より下位の互換表示モードをもつIE9とIE10用の処理も必要だ。
また、IE7以下はトライデントトークンを持っていないので、IE7用の判定処理も別途必要となる…(いやはや、まるで嫌がらせのような仕様だな…)。試しにこのDEVLABで利用している独自のクライアントデバイス判定処理(PHP)で、IE11にも対応した判定処理に修正してみた。
まずは、今までのIE判定処理内容。
[php] $ua = $_SERVER[‘HTTP_USER_AGENT’]; $results[‘browser’] = ‘’; $results[‘version’] = ‘’; if (preg_match(’/(MSIE \d{1,}?(.\d{1,}?){1,}?;)/’, $ua, $mtcs)) { $results[‘browser’] = ‘msie’; list(, $vstr) = explode(’ ‘, str_replace(’;’, ‘’, $mtcs[0])); $results[‘version’] = $vstr; } [/php]Android アプリに設定されたパーミッションを取得する
...もしmanifestに設定されていないパーミッションが必要な機能を使うと無慈悲なSecurityExceptionが発生します。 それはもう、catch節をスルーするくらい無慈悲です。 このExceptionが発生するという事は、manifestとコードが不一致だということなので、コード直せボケ! なのかもしれませんが、やはりコード内でパーミッションをチェックして条件分岐したい事もあるものです。 例えばライブラリとして公開する場合とか。 そんなわけで、パーミッションのリストを取得するメソッドと、お目当てのパーミッションがmanifestに存在するのか確認するメソッドをお届けします。 [code lang="java" light="true"] /** * 指定されたパーミッションがmanifestに記載されているかどうか確認します。 * * @param checkPermission 調査するパーミッション * @param context コンテキスト * @return true:記載されている /false:記載されていない */ public boolean hasPermission(String checkPermission, Context context) { if (checkPermission == null || context == null) { // 引数が渡されていないケース return false; } String[] requestedPermissions = getPermissionList(context); if (requestedPermissions == null) { // manifestに一件もpermissionが設定されていないケース return false; } for (String str : requestedPermissions) { if (str.equals(checkPermission)) { // 調査するパーミッションが存在したケース return true; } } // 調査するパーミッションが存在しなかったケース return false; } /** * manifestに記載されているパーミッションのリストを返します。 * * @return パーミッションのリスト */ public String[] getPermissionList(Context context) { PackageManager packageManager = context.getPackageManager(); PackageInfo packageInfo = null; try { packageInfo = packageManager.getPackageInfo(context.getPackageName(), PackageManager.GET_PERMISSIONS); } catch (NameNotFoundException e) { return null; } return packageInfo.requestedPermissions; } [/code] 使い方 [code lang="java" light="true"] String checkPermisson = "android.permission.READ_PHONE_STATE"; if (hasPermission(checkPermisson, context)) { Log.d("TAG", checkPermisson + " exist!"); } else { Log.d("TAG", checkPermisson + " not exist!"); } [/code] お役に立てば。GitHubでpush時にAWS OpsWorksで自動デプロイする方法
...開発の平形です。
今日は、GitHubでpush時にAWS OpsWorksで自動デプロイする方法をお教えします。
OpsWorksはAWSで提供されているデプロイのサービスです。
*OpsWorksについては、こちらのサイトが詳しいです。
この話は、OpsWorksにスタックとレイヤとインスタンスが存在する前提です。
OpsWorks自体、最近触ったばかりですが、
デプロイがすごく簡単にできるという事はよくわかりました。でも、欲張りな僕は、もっと自動化できないのかな?と思ったのです。
普段、ソースはGitHubでバージョン管理しているので、
GitHubにpushしたら同時にデプロイできないのかな?と。そしたら、ビックリするほど簡単に実現できました。
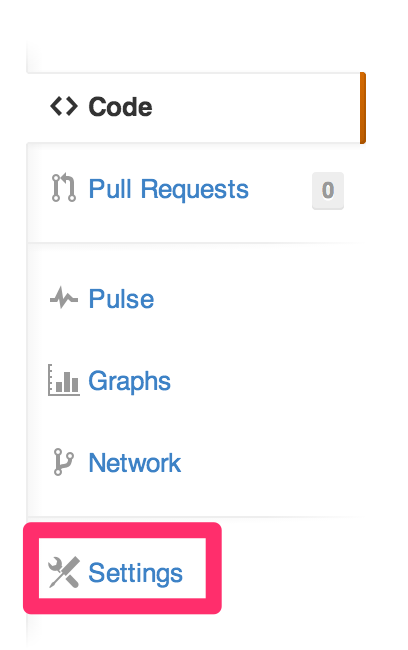
GitHub側で設定が可能です。
アプリケーションのリポジトリのページの「Settings」
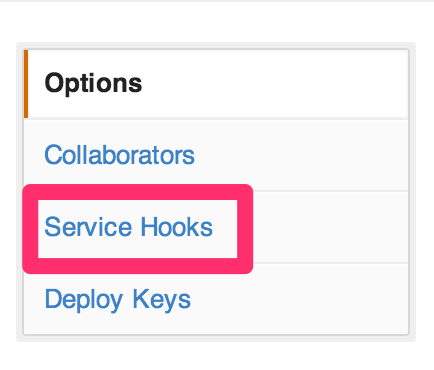
「Service Hooks」
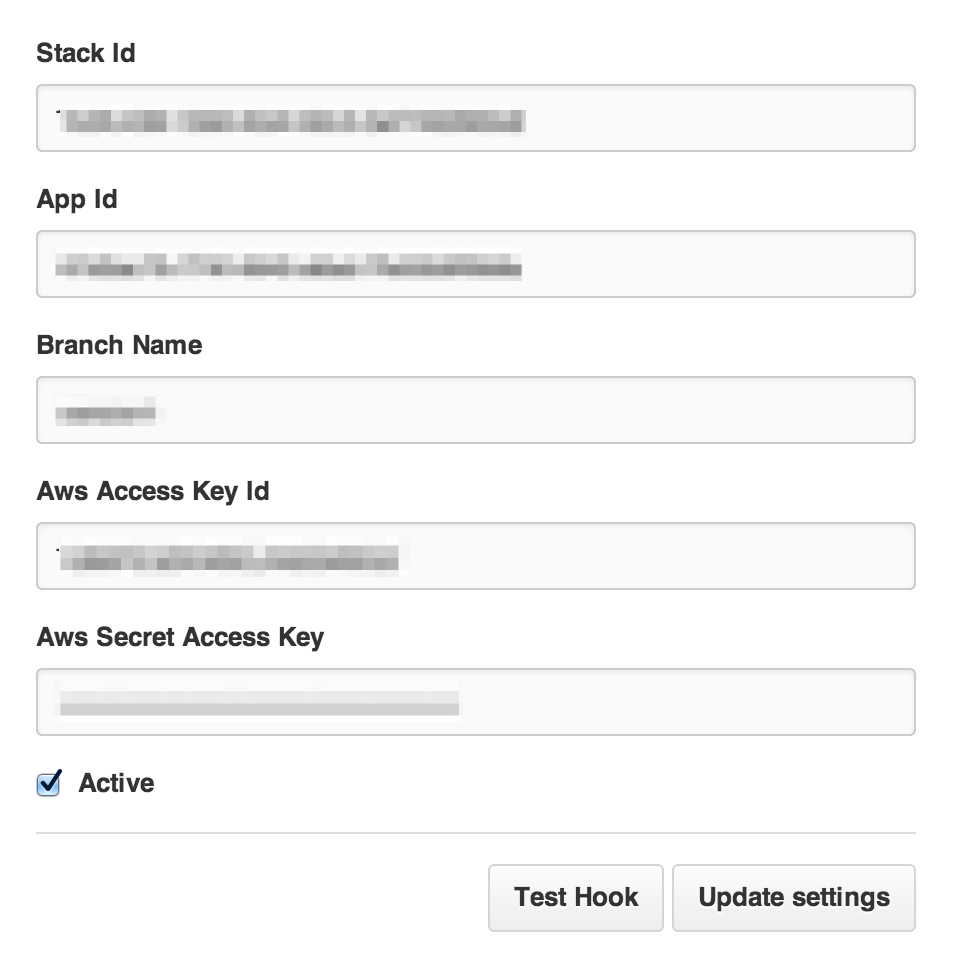
AWS OpsWorks

以下の項目は全て必須なので、全部入力します。
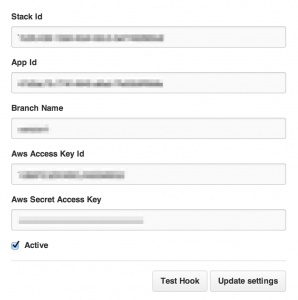
ここで、OpsWorks側の情報が必要になります。
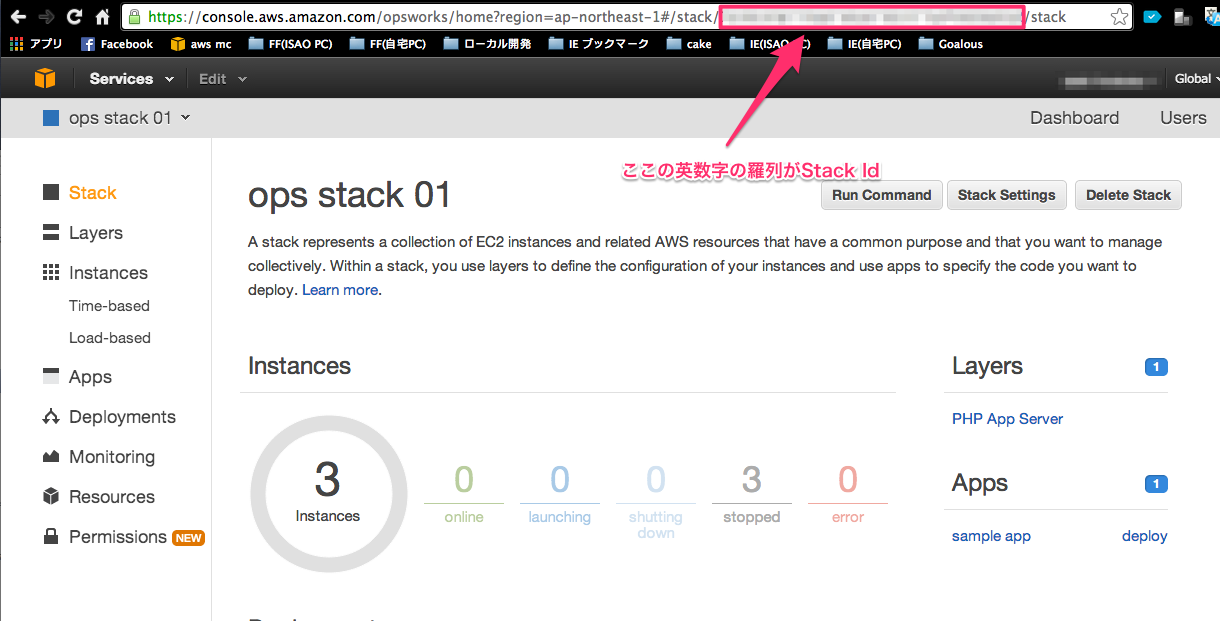
まずは、Stack Idですが、一見これがわかるところが、AWS Managed Consoleの画面上にはありません。
手っ取り早くこれを確認する方法はStackの画面のURLをみる事です。
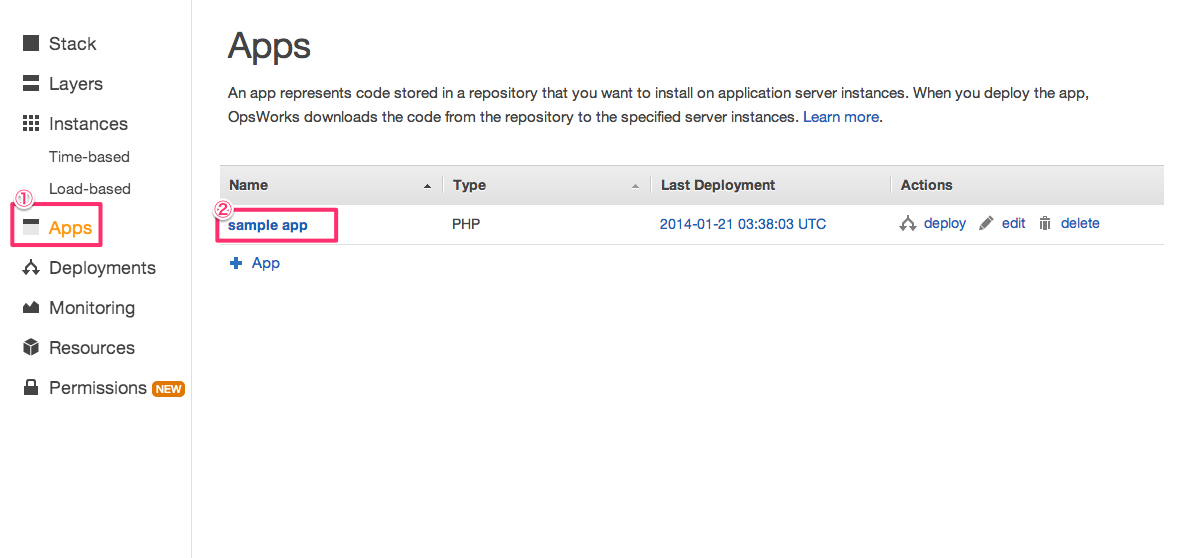
次にApp Idですが、同じくOpsWorksの画面で、「Apps」=>「アプリケーション名」をクリック
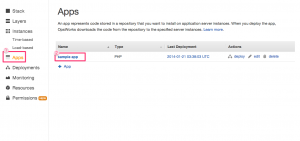
OpsWorks IDがApp Idです。
redisのソースインストール(chef-solo)
...こんにちは。opsのほうの小宮です。
redisのソースインストールをご依頼いただきCHEF-SOLOったのでその記録をのこしておきます。★要件
バージョンについては2.8.4でお願いします。(2014/1時点で最新のソース)★以下作業
・rpmで入るバージョンの確認(※同環境のサーバでyumで確認)
redis.x86_64 0:2.4.10-1.el6※要件に合わないためソースインストールする必要がある
・chef-soloの下準備
[shell]$ ssh-copy-id -i ~/.ssh/id_dsa.pub server2 $ ssh-copy-id -i ~/.ssh/id_dsa.pub server1
$ knife solo prepare server1 $ knife solo prepare server2[/shell]
・role作成
[shell]$ vi roles/rankingAPI.json { “name”:“rankingAPI”, “chef_type”: “role”, “json_class”:“Chef::Role”, “default_attributes”:{ “base_setting”: { “swappiness”: “0”, “tcp_tw_reuse”: “0”, “tcp_tw_recycle”: “0”, “tcp_fin_timeout”: “10”, “tcp_max_syn_backlog”: “8192”, “somaxconn”: “8192”, “ntpserver1”: “ntp.nict.jp” } }, “override_attributes”:{}, “description”:“rankingAPI’s role”, “run_list”: [ “recipe[roles::rankingAPI]” ] }gitでクローンと同時にサブモジュールを初期化、アップデートする
...こんにちは。
開発の平形です。初投稿になります。
Gitでcloneした後に、何かが足りなくてうまく動かない事がよくあります。
そして気づくのです。
あ、submoduleをクローンしてねーじゃん!
※submoduleについてはこちらの記事が参考になります。このパターン何回目だよ!
と自分が嫌になってしまいます。そしていつも、
git clone git://github.com/foo/bar.git git cd bar git submodule update --init --recursiveといったお決まり作業をする訳です。
でもついつい忘れてしまうんですよね。で、調べてみるとちゃんとあるんですね。
git clone --recursive git://github.com/foo/bar.gitこれで、クローンと同時にサブモジュールもクローンされます。
通常のクローンと使い分ける必要も特にないので、これからはこれを使っていこうと思います。読んでいただいてありがとうございました。
まだまだ、寒い日が続いておりますが、お体にご自愛くださいませ。
参考にしたページ
http://stackoverflow.com/questions/3796927/how-to-git-clone-including-submodules
cpuコア数に応じたrps_cpusに入れる値の計算方法
...こんにちは。OPSのほうの小宮です。
cpuコア数に応じたrps_cpusに入れる値の計算方法です。ネットワークの割り込み処理を複数コアに分散したいという要望がありまして。(特にキャッシュサーバ)
できる人に頼って、ここ↓まで頑張ってもらいました。
[shell]# core=1 # echo “obase=16; ibase=10; $(( 2 ** ${core})) -1” | bc | tr ‘[A-Z]’ ‘[a-z]’ 1 # core=2 # echo “obase=16; ibase=10; $(( 2 ** ${core})) -1” | bc | tr ‘[A-Z]’ ‘[a-z]’ 3 # core=4 # echo “obase=16; ibase=10; $(( 2 ** ${core})) -1” | bc | tr ‘[A-Z]’ ‘[a-z]’ f # core=5 # echo “obase=16; ibase=10; $(( 2 ** ${core})) -1” | bc | tr ‘[A-Z]’ ‘[a-z]’ 1f[/shell]
Mondo Rescue使ってみました(その2)
...おはようございます。インフラの宮下です。
前回「Mondo Rescue」で取得したバックアップデータを使用して、レストアするまでを紹介します。
目次
はじめに
バックアップをとるまでは実行しますが、物理環境だとレストアまではなかなか検証する環境が無いので最初にしっかりとレストアしておくのが賢明だと思います。クラウドはその辺いいですね~♪
バックアップをNFS先に出力した方がMondo Rescueぽいですが、今回はネットワーク環境の都合と作業時間が限られていた為に
ローカル出力してDVDメディアからレストアする方法を選択しました。前回作成したしたisoイメージをDVDに書き込んでおきます。
DVDへの書き込みですが、私は昔からDeepBurnerを愛用しています。レストア実施
DVDメディアを挿入して、サーバを起動します。
mondoのOSが立ち上がってきたら「boot:」プロンプトが出てきますので下の中から方式を選択します。nuke 全自動でリストア。ただ見てるだけで終わります。元データは完全に消去されるので注意は必要。 interactive 対話形式でリストア。カスタマイズやNFS上のISOを指定する時に選択します。 expert シェルプロンプトを起動する。fdiskとかも実施する場合はこちらで。 [shell] boot: nuke [/shell]
今回は全て自動でレストアします。実際「nuke」を入力する以外に何もする事はありませんでした。
DVDメディア1枚(約4GB)なら30分もあればレストアまで完了しました。DVDドライブの書き込み速度が24倍速だと、全ての工程が1時間くらいで終わります。
今後の使い方ですが、ISOデータをAWSで保管するとか
クラウド上での利用方法(AMI作れるからプライベート上)とか
その他の商用ソフトとの比較も実施してみたいです。また、「Mondo Rescue」はUNIXに対応していないのでSolarisでufsdumpの他にもっと快適にできる
方法も探したいと思います。参考サイト
Mondo rescueを用いたシステムリカバリの方法
Mondo Rescueのバックアップデータをリストアするには
Mondo RescueDEVLABをリニューアルしました
...2014年 明けましておめでとうございます。
年末年始の休暇を利用してDEVLABのサイトリニューアルを行いました。
何気に3回目のリニューアルなのですが、今回はWordPressのテーマ自体を新しく作り直したので結構大規模リニューアルになりました。正月の後半は半ば家族サービス放棄で連日徹夜気味に作業してました・・・(笑)
また、今回のリニューアルタイミングにてWordPressも3.7.1へアップグレードしました。実は年末にバージョン3.8も出ていたのですが、まだ日本語ローカライズ版は提供されていないので、最新安定版の3.7.1までとしてあります。
昨年は多忙にかまけて投稿機会を逸してなかなか投稿数が伸びなかった私maenoですが、今年は心機一転して色々と投稿して行きたいと思いますので、本年もDEVLABともども弊社デベロッパーメンバーをよろしくお願いいたします。
MySQLでALTER TABLEでINDEXを作成するときの注意事項
...こんにちは。Ops側の小宮です。
ある日朝来たら突然開発の方から相談いただいたので、後のために記録しておこうと思います。相談内容:
jenkinsで本番デプロイを行ったが、処理を途中停止した。
(CakeのDBマイグレーションスクリプトでデプロイした)
KEYカラムにINDEXをはろうとしたがDBの応答がなくなり接続できなくなった。
結果としてテーブルが破損したためRDSの時刻指定してロールバックする機能を用いた。
(ALTERが終わってたかどうかとかはロールバックしたので不明)
同じレコード数の試験環境で同じ操作をしたら特に異常なくすんなり終わった。
もう一回同じことを本番でやりたいけどどうしましょう。
MySQLのバージョンは5.5.27。私の個人的認識:
普通、ALTERする時はロックがかかるから、
事前に同じ構成と件数の試験環境でかかる時間を見積もってから
その時間サービス止めてメンテ入れるべきです。
(※5.5まで。5.6から一部のALTERはオンラインで大丈夫になったようです。)
sorry表示に切り替えて更新のない環境でやってみましょう。
(既存のELBの下のwebを全部はずして、別のサブドメインのwebにvhost切ってsorryコンテンツおいてELBに入れるとか)
途中で強制終了とかするとMyISAMだとテーブル壊れやすそう。
show full processlist;で現在のクエリとかかってる時間は見ることができる
けどkillするのは最終手段かと。alter table mysqlとか、それプラス5.6とかでググると色々わかります。
sh2さんのブログを見ると、以下のように書かれています。
MySQLでALTER TABLE文の進捗状況を確認する - SH2の日記
-————— MySQLでは
変更後の定義にもとづく作業用テーブルを作成し、
変更前のテーブルから作業用テーブルへデータをコピーして、
最後に二つのテーブルを入れ替えるという仕組みになっています。
テーブルへのインデックス追加についても、現在のところ大半の
ケースで内部的にALTER TABLE文が実行されています。どこまですすんでるのか確認する方法:
SHOW GLOBAL STATUS LIKE ‘Handler_write’;
作業開始前にHandler_writeの値と対象テーブルのレコード件数を控えておけば、
どこまで処理が進んだのかを確認することができるのです。InnoDBならinnotopをつかうと、row operationsのビューにズバリIns/Secがあるので、
同様にしてALTER TABLEの完了予想が立てられますね。
差を自分で計算しなくてもいいし、標準的なツールなので便利
-—————Mondo Rescue使ってみました(その1)
...おはようございます。インフラの宮下です。
最近クラウド環境でイメージ作成ばかりしていたので、たまにはオンプレミス環境で
フルバックアップも取得してみます。目次
1.はじめに
定常的にOSバックアップをとるという案件で無く更新作業の前にバックアップを取得する必要があり色々とバックアップツールを検討していました。商用の検証もいくつか実施したのですが、今回はオープンソースの「Mondo Rescue」というバックアップツールを使ってみたいと思います。
オープンソースを使う最大の理由は、コストと納期になりますね。計画的な案件であれば商用のバックアップツールの検討が最初になるかと思います。
「Mondo Rescue」を選択した点としましては、NFSマウント先にファイルが保管できさらにそこからレストアも可能という情報が最大の「それ魅力」です。また、メディアからレストアするのも簡単そう(実際に簡単)なのも良さげでした。2.環境
ロケーション:物理サーバ(富士通製) OS:Red Hat Enterprise Linux Server release 6.4
3.mondorescueのインストール
最初にmondorescueのリポジトリを追加します。
[shell] vi /etc/yum.repos.d/mondorescue.repo [mondorescue] name=rhel 6 x86_64 - mondorescue Vanilla Packages baseurl=ftp://ftp.mondorescue.org//rhel/6/x86_64 #baseurl=ftp://213.30.161.23//rhel/6/x86_64 enabled=0 gpgcheck=1 gpgkey=ftp://ftp.mondorescue.org//rhel/6/x86_64/mondorescue.pubkey #gpgkey=ftp://213.30.161.23//rhel/6/x86_64/mondorescue.pubkey [/shell]
準備完了と言う事でmondorescueリポジトリを使ってmondo resucue本体をインストールします。
[shell] # yum install mondo –enablerepo=mondorescue =================================================================================================================================== Package Arch Version Repository Size =================================================================================================================================== Installing: mondo x86_64 3.0.4-1.rhel6 mondorescue 1.3 M Installing for dependencies: afio x86_64 2.5-1.rhel6 mondorescue 81 k buffer x86_64 1.19-4.rhel6 mondorescue 24 k mindi x86_64 2.1.7-1.rhel6 mondorescue 331 k mindi-busybox x86_64 1.18.5-3.rhel6 mondorescue 306 k syslinux x86_64 4.02-4.el6 mondorescue 855 knatインスタンスの冗長化
...こんにちは。プラットフォームの小宮です。
他を冗長化してもnatインスタンスを冗長化してないと、
プライベートセグメントでHAしてるサーバ達がAWSのAPIサーバと通信できなくなって詰むなあと思いまして、
先人の皆さまの記事を参考にして以下のとおりにしました。**・なんとなくどうするか検討
**AmazonLinuxで作っちゃったので、たぶんHeartbeatとか入れづらいし、そもそもheartbaet使う必要ない気がする。
待機系から監視してaws的にルーティングテーブル挿げ替えるだけでよさそう。待機系natインスタンスについて、
作成しておかないと作成と起動とルーティングテーブル作るところもやらないといけないので切替時間が長くなる。
インスタンス代がかかるけど起動もしたままがいいと思われ。**・とりあえず既存のAmazonLinuxのNATインスタンスの設定をいじるところから
**
sudoできるようにしてみる# usermod -G wheel user-op # id user-op uid=500(user-op) gid=501(user-op) groups=501(user-op),10(wheel) # visudo %wheel ALL=(ALL) ALLコメントはずす。
他のインスタンスから渡ってsudoできるか確認するあとnatインスタンスにpythonのツール入れておく
メール送信も設定
AmazonLinuxではsendmailが動いてる模様だった。vi /etc/mail/submit.cf D{MTAHost}[172.18.10.22] Djnat01.hoge.com ※nat02はそう変える service sendmail stop chkconfig sendmail off yum install mailx echo hoge |mail -s testkomi komiyay@xxxxxロケールを合わせる
Android : WebView と HttpClient 間で セッションを同期する
...WebViewでログインした後、HttpClientを呼び出すと・・・あれログインしていないジャン! 逆もまたしかり。
Androidの中ではWebViewとHttpClientは、例えれば別のブラウザとして扱われるようです。
この件についてはあちらこちらで説明されています。
[Android]WebView、HTTPClientでSessionを共有する
が、更になんも考えないで済むように同期だけを行うクラスを作成してみました。よかったらどうぞ。
[code lang=“java” light=“true”] package your.package;
import java.util.List;
import org.apache.http.client.CookieStore; import org.apache.http.cookie.Cookie; import org.apache.http.impl.client.DefaultHttpClient; import org.apache.http.impl.cookie.BasicClientCookie;
import android.webkit.CookieManager; import android.webkit.CookieSyncManager;
/** * HttpClient, WebView間でセッションを同期するためのクラス */ public class SessionSync {
// COOKIEの送出するドメインを指定します private static final String YOUR_DOMAIN = "your.domain"; // COOKIE取得用のドメイン(.をつけてサブドメインもカバーします) private static final String COOKIE_DOMAIN = "." + YOUR_DOMAIN; // COOKIEを送出するURL private static final String COOKIE_URL = "http://" + YOUR_DOMAIN; // セッションIDを格納するパラメータ名を指定します // これはPHPの例 private static final String SESSID = "PHPSESSID"; /** * HttpClient側のセッションIDをWebViewに同期します * * @param httpClient セッションを同期するHttpClient */ public static void httpClient2WebView(DefaultHttpClient httpClient) { CookieStore store = httpClient.getCookieStore(); List<Cookie> cookies = store.getCookies(); CookieManager cookieManager = CookieManager.getInstance(); for (Cookie cookie : cookies) { if (cookie.getDomain().indexOf(COOKIE_DOMAIN) < 0) { continue; } if (!SESSID.equals(cookie.getName())) { continue; } // ここで削除するとsyncしたタイミングでsetしたcookieも // 消える場合があるので削除は見合わせ // cookieManager.removeSessionCookie(); String cookieStr = cookie.getName() + "=" + cookie.getValue(); cookieManager.setCookie(COOKIE_DOMAIN, cookieStr); CookieSyncManager.getInstance().sync(); } } /** * WebView側のセッションIDをHttpClientに同期します * * @param httpClient セッションを同期するHttpClient */ public static void webView2HttpClient(DefaultHttpClient httpClient) { String cookie = CookieManager.getInstance().getCookie(COOKIE_URL); String[] cookies = cookie.split(";"); for (String keyValue : cookies) { keyValue = keyValue.trim(); String[] cookieSet = keyValue.split("="); String key = cookieSet[0]; String value = cookieSet[1]; if (!SESSID.equals(key)) { continue; } BasicClientCookie bCookie = new BasicClientCookie(key, value); bCookie.setDomain(COOKIE_DOMAIN); bCookie.setPath("/"); CookieStore store = httpClient.getCookieStore(); store.addCookie(bCookie); } }} [/code]
AWS(VPC)上でheartbeat3でlvsを構成する話
...※1年以上前の旧い記事なのでご注意ください。※
こんにちは。プラットフォームの小宮です。
今回は、ELBは高いのでスモールスタートだからLVSを構築しましょうという趣旨ですすめた記録です。 最初に書くのもなんですが、LVSでWEBもDBも負荷分散しちゃおうぜということだったんですが、結果的にはWEB側はやっぱELBにという話になりました。 (公私混同フラットNWであることを顧客に説明するのが大変だという話とSSLとかスケールとか運用の利便性等で。)
普段よりは気をつける点: ・環境がAWS(インスタンスを気軽に作り直してChange Source/Dest CheckをDisableにし忘れる等に要注意) ・クライアントがグローバル越しだとDSRできない(エッジルータでENIとIPが合わないパケットが破棄される) ・フラットなNW構成でないとDSRできない(これは普段通りだけど気をつけるポイント) ・複数NWでNATインスタンスが必要になる等の特殊事情(だからNWは1つだけにしました) ・DBはDSR、WEBはNATで分散する ・VIPは使えるけどAWS的な管理上APIサーバと通信して切り替える必要がある ・AWS的な管理上splitbrainは実質起こらないがどっちについてるか確認必要 ・AWS的な制約でマルチキャストは使えないのでHA通信はunicastを用いる ・証明書は負荷分散ライセンスとかでWEBサーバ側で管理する
目次: ・基本構成 ・分散対象側の基本的な設定 ・ipvsadmで負荷分散の単体テスト ・heartbeatの導入設定 ・ldirectordの導入設定 ・EIP・PrivateIP移動シェル作成 ・リソース設定 ・インスタンスコピーの際の作業 ・切替テスト ・ハマったところ
・基本構成
LVS01(主系) LVS02(待機系) web2台、配信サーバ2台、db2台に対しそれぞれ80と443、3306readを分散
lvs01:172.18.1.23 lvs02:172.18.1.25 db-r-vip:172.18.1.200 web-vip:172.18.1.199 db-client:web(local) web-client:any(global) real-db:172.18.1.220,221 real-web:172.18.1.33,34 webの分散方式:NAT dbの分散方式:DSR
設計書ではフロントセグメントとバックセグメントに分かれていたのですが、AWS的な仕様上LVSと組み合わせる為にはフラットにせざるをえませんでした。 ⇒クライアントがグローバル越しのWEBサーバはエッジルータでENIとIPが一致しないパケットが破棄される為分散方式はDSRは無理でNATしか利用できない ※こちらのスライドの17枚目が論拠です。 ⇒分散方式がNATだとリアルサーバは負荷分散サーバをデフォルトGWとして指定する必要がある ⇒NATインスタンスはNICを一つしか持つことができない仕様だがデフォルトGWは同一セグメントでないと指定できない ⇒少なくともWEBはセグメント1つにしないとLVS+VPCでは負荷分散できないがDBとWEBの分散は同じLVSで一緒にやりたいしもうNWセグメントは1つでいいや ⇒バックセグメントが無くてもVPCだしSecurityGroupの設定さえまともなら大丈夫 というような事情によりまして設計書の仕様変更をしないとどうにもなりませんでした。 なんでHAproxyじゃないのかというと、運用上不慣れだからとLVSのがパフォーマンスがいいらしいから。DBだけでもDSRできるのは嬉しいです。
facebookのIPがmod_geoipで拒否される対応
...こんにちは。プラットフォームの小宮です。
apacheのmod_geoipモジュールで海外を拒否してみたところ、
Facebookの画像が表示されないということで対応しました。・whoisが必要だが入ってなかったので他の入ってるサーバでパッケージ名を調べて導入
[shell]$ which whois /usr/bin/whois # rpm -qf /usr/bin/whois jwhois-3.2.2-1
# yum install jwhois Installed: jwhois.x86_64 0:4.0-19.el6 # which whois /usr/bin/whois[/shell]
・fb公式で許可リスト取得方法を確認
以下のコマンドで定期的に更新リストを取得せよと公式に書いてある。
App Security - Facebook開発者[shell]# whois -h whois.radb.net – ‘-i origin AS32934’ | grep ^route:|awk ‘{print $2}’ 204.15.20.0/22 69.63.176.0/20 ~略~ 69.63.184.0/21 66.220.144.0/20 69.63.176.0/20[/shell] ※65ブロックくらいだった。手作業はあり得ないので何とか自動化を試みる。
・設定追加方法の検討
この辺に追記できるか考えてみる。
[shell]# cat /etc/cron.monthly/geoip #!/bin/bash wget -q http://geolite.maxmind.com/download/geoip/database/GeoLiteCountry/GeoIP.dat.gz gunzip GeoIP.dat.gz mv -f GeoIP.dat /usr/share/GeoIP/GeoIP.dat[/shell]
datはバイナリなので自分で追記は困難。軽くググってもそんなことしてる人いない。
[shell]# file /usr/share/GeoIP/GeoIP.dat /usr/share/GeoIP/GeoIP.dat: data[/shell]

{kind=link}