WordPressのサイトが重くなった時のプラグインパフォーマンス検証
...とある多国語サイトをWordPressで構築している時に、結合試験もほぼ終わったあたりで、構築サイト全体のパフォーマンス・チューニングをしていた時の備忘録です。
対象のサイトは規模がそんなに大きくなかったので、AWSのm3.mediumのインスタンスに構築していたのだが、開発途中からサイト全体のパフォーマンスが落ちて、だいぶ重いサイトになって来てました。サイトのパフォーマンス検証「GTmetrix」でのレポートを見ると、サイト内で利用している画像のレスポンスがレイテンシー食っているという結果しか出ず、とりあえずは出来る限りの画像最適化を行って、フロントエンドのパフォーマンスはだいぶ良くなったのだが、WordPressの管理画面は重いまま変わらなかった。WEBサーバ側で静的コンテンツのGZIP圧縮や、.htaccessを利用せずにhttpd.conf内に設定を移行など、諸々対応してみたが効果はなかった。他にMySQLTunerでDBの設定を検証・チューニングしてみたが、特に変化なし。
う~む、CloudWatchを見るとCPU使用量がやけに大きいので、AWSインスタンスの非力さが原因なのかも…そうなると、最終的にはm3.mediumインスタンスからc3系へのインスタンス変更が必要かも知れないなぁ…とか考えていたのだが、そもそも開発中のサイトで社内の数人しかアクセスしない管理画面が重いというのは根本的に別の要因があるはず。サイト全体に関わるものというと、テーマかプラグインかしかない。そこで、導入しているプラグインのパフォーマンス検証を行ってみたところ、ビンゴ!…パフォーマンス低下の原因はプラグインだった。今回プラグインのパフォーマンス検証に利用したのが「P3(Plugin Performance Profiler)」だ。プラグインのパフォーマンスを検証するのに別のプラグインを入れるというのも変な話だが、このP3プラグインはWordPressサイト内でのプラグインやテーマのパフォーマンスを細かいところまでスキャン・レポーティングしてくれるかなり優秀なものだ。導入も簡単で、プラグインをダウンロードして有効化すればいつでも管理メニューの「ツール」からパフォーマンススキャンができる。
このP3プラグインでスキャンした結果はこうなった。
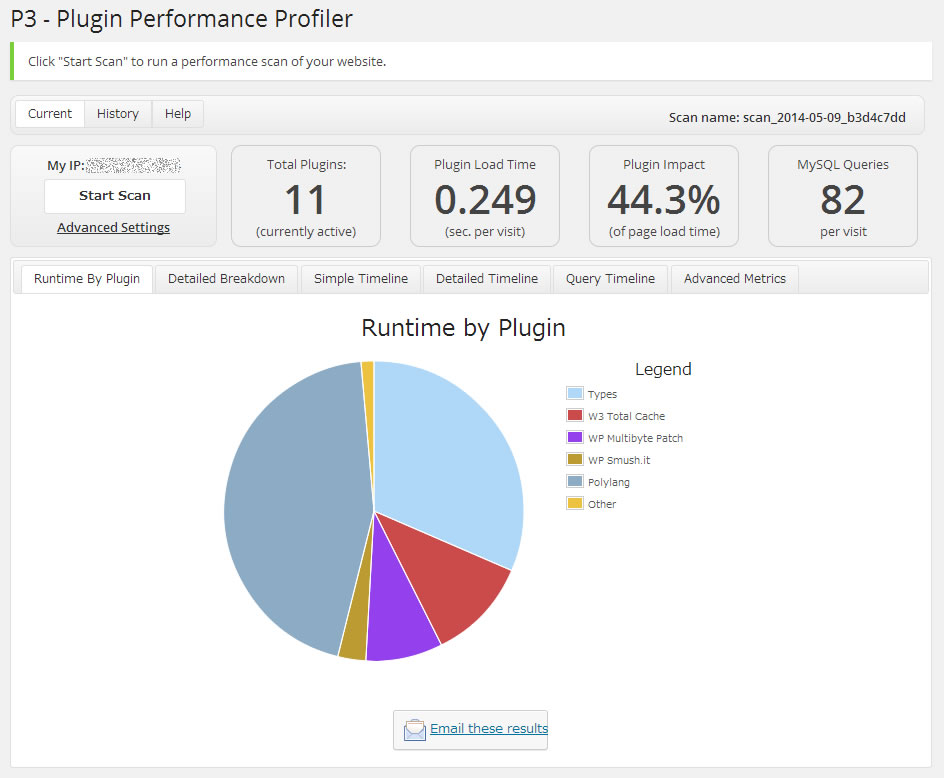
多言語化プラグインの「Polylang」とカスタム投稿タイプ系プラグインの「Types」がランタイムを圧迫しているのがわかる。さすがに多言語サイトなので「Polylang」は外せないが、カスタム投稿タイプ系のプラグインは同系プラグインが多いので差し替え可能だ。「Types」は「Polylang」に公式対応しているプラグインなので採用していたのだが、たかだかカスタム投稿の拡張をするだけで、ここまでランタイムを占有されてはちょっと使い勝手が良いとは言えない。
そこで、「Types」プラグインを外して、同系で使い慣れている「Custom PostType UI」プラグインを導入してみた。
「Types」で占有されていたランタイムがなくなり、プラグインロードタイムやプラグインインパクトが改善された。管理画面の体感速度も数十倍に向上し、本来のサクサク編集できるUXが復活した。プラグイン一つでここまでパフォーマンスが変わるものなんだなぁ…と実感できました。
今回の件から、今後WordPressサイトを作る際には、プラグインの機能よりもパフォーマンスを重視して選定した方が良いと私的には思えました。なぜなら、プラグインの機能で足りないものは後からいくらでも追加することができるが、プラグインのコアに依存するパフォーマンスを改修するのは非常に困難だからです。
特に管理画面が重いと、サイトを運用するWEB担当者のモチベーションがかなり下がってしまうので、ちょっと機能不足でもストレスなく運用できる管理画面の方が喜ばれるのではないだろうか。AWS認定ソリューションアーキテクト–アソシエイトレベル受験体験記
...おはようございます。インフラの宮下です。
ゴールデンウィーク突入の直前に「AWS 認定ソリューションアーキテクト – アソシエイトレベル」を受験しましたので、
試験の手続き方法や勉強内容について守秘義務に反しない程度にご紹介します。○ 試験の事、そして申込みまで
試験範囲は、Blueprintが公開されていますので正確な情報はそちらを確認してください。
blueprint現時点での出題配分は下記の通りで、Blueprintでは一つ一つ細かく説明がなされています。
時間の限られている社会人は、勉強の基本はBlueprintを見て戦略を練るのが最短距離とい言うのが私の方針です。1.0 Designing highly available, cost efficient, fault tolerant, scalable systems 60%
2.0 Implementation/Deployment 10%
3.0 Data Security 20%
4.0 Troubleshooting 10%Blueprintを一読した印象では、単純にサービスを知っているだけでは厳しそう、という印象でした。
実際に試験を申し込まないと受験できませんので、申込方法を説明します。
AWSのページで案内している通りKryterion社が試験を提供しています。
ここでの注意点は、英語ページのままサインアップすると試験が英語版しか出てきません。
サイトが日本語ページである事を確認してサインアップしましょう。(英語版を希望する時は逆に英語でサインアップする)サインアップ後に「試験のお申し込み」で「AWS 認定ソリューションアーキテクト-アソシエイトレベル」を選択すると 試験会場の選択そして日時の選択になります。
私は、池袋の会場で申し込みました。池袋の地理に明るい自分はすぐに分かりましたが、不慣れな人は
場所はしっかりと確認しておいた方が良いかもしれません。
大塚方面を線路沿いに進み、公園の向かい向かいにあるそんなに大きくないビルの中になります。
試験日程ですが、まだ会場がそれほど多くないせいか直近1週間は結構混んでいます。
1~2週間先をゆとりをもって予約をするのが良いと思います。試験を申し込んだら完了メールが来ますので、印刷して当日は必ず持参しましょう。
結構大事な事がかいてあります。
「受験者認証コード」を提示しないと受験できなかったり、身分証明書を2種類用意するとか○ 試験対策について
nginxでヘルスチェックのアクセスログを出力させない設定
...おはようございます。インフラの宮下です。
今回はnginxのログ関連の設定になります。目次
はじめに
apacheで良く実施する、setenvの定義を利用して特定NWから来るログを出力しないような設定をnginxでも実施したかったのですが同じ機能が無かったので調べてみました。 使い道としては、ロードバランサーのヘルスチェックや監視サーバからの接続など、ログに出力しない方が都合が良い時に利用できます。 解析するには不要ですし、余計なDISK I/Oも抑えられます。
ngx_http_geo_moduleとは
ドキュメントの通りIPアドレスを変数としてセットできます。
一般的に使われるのは、特定の国のNWは接続拒否するような時にこのモジュールを使う事が多いようです。 そのような場合は、includeして大量に登録された別ファイルで管理する事も可能です。nginxへの設定
nginx.confに設定します。
[shell]# vi nginx.conf http { include mime.types; (中略) # not access_log IP’s geo $no_log { default 0; 172.0.1.0/24 1; } server { (中略) location / { root /var/www/html; index index.cgi index.php index.html index.htm; if ($no_log) { access_log off; } } }[/shell]Solaris10にUSB外付けハードディスクを付けてバックアップを取得する
...おはようございます。インフラの宮下です。普段はクラウド中心なのですが、
solarisにUSBのHDDを付ける事があったのでその手順を紹介します。環境:solaris10
機器:SPARC T2000
HDD:IOデータの500GB USBポータブルハードディスク○1回目
あまり何も考えずにとりあえず接続してみました。messagesにログが出てきて認識されている事は
確認できます。[shell]Apr 9 15:45:11 test-web21 usba: [ID 912658 kern.info] USB 2.10 device (usb4bb,152) operating at hi speed (USB 2.x) on USB 2.0 external hub: storage@1, scsa2usb2 at bus address 7 Apr 9 15:45:11 test-web usba: [ID 349649 kern.info] I-O DATA DEVICE, INC. HDPF-UT 000315C3C1900CEE Apr 9 15:45:11 test-web genunix: [ID 936769 kern.info] scsa2usb2 is /pci@400/pci@2/pci@0/pci@f/pci@0/usb@0,2/hub@4/storage@1 Apr 9 15:45:11 test-web genunix: [ID 408114 kern.info] /pci@400/pci@2/pci@0/pci@f/pci@0/usb@0,2/hub@4/storage@1 (scsa2usb2) online Apr 9 15:45:13 test-web scsi: [ID 583861 kern.info] sd5 at scsa2usb2: target 0 lun 0 Apr 9 15:45:13 test-web genunix: [ID 936769 kern.info] sd5 is /pci@400/pci@2/pci@0/pci@f/pci@0/usb@0,2/hub@4/storage@1/disk@0,0 Apr 9 15:45:13 test-web genunix: [ID 408114 kern.info] /pci@400/pci@2/pci@0/pci@f/pci@0/usb@0,2/hub@4/storage@1/disk@0,0 (sd5) online[/shell]
パーテション情報を確認すると残念ながらNTFSで、なんとsolarisは未対応の為フォーマットエラーになってしまいました。mysqlのreplication関連リンクまとめ
...mysqlのreplication関連情報まとめ
こんにちは。小宮です。
なんだかmysqlのことを聞かれることが多い今日この頃なので、
聞かれたときコピペできるように聞かれがちなことが説明されてるリンクをまとめる試みです。
この記事だけ読んでも大したことはわかりませんのであしからずご了承ください。
(自分がすっかり忘れたときにも役立ちそうです。)・基本
現場指向のレプリケーション詳説
漢(オトコ)のコンピュータ道: MySQLレプリケーションを安全に利用するための10のテクニック
Art of MySQL Replication.
バイナリログに書かれるのは更新系のクエリです。
補足すると、I/Oエラーは、物理的にディスクが壊れた、ネットワーク的につながらない、レプリケーション用ユーザのIDとパスワードが間違っている、server_idが重複している
などの理由で起こることがあります。SQLエラーの主な原因は上記の最初のリンクに書いてありますが主に重複エラーが多い印象です。参考までに現在のreplicationまわりの設定値はだいたいこんなかんじです。
[shell]## replication (master/slave) log-bin=mysql-bin log-bin-index=mysql-bin.index binlog_format=mixed server-id = 133 relay-log=mysqld-relay-bin relay-log-index=mysql-relay-bin.index log_slave_updates=1 replicate-ignore-db=mysql,information_schema,performance_schema binlog-ignore-db=mysql,information_schema,performance_schema skip_slave_start read_only slave_net_timeout=120
## replication (for 5.6) gtid-mode = OFF enforce_gtid_consistency=false master-info-repository=TABLE relay-log-info-repository=TABLE relay_log_recovery=ON #sync-master-info=1 slave-parallel-workers=0 binlog-checksum=CRC32 #master-verify-checksum=1 #slave-sql-verify-checksum=1 binlog-rows-query-log_events=1 #log_bin_use_v1_row_events=ON #sync_binlog=1 report-port=3306 report-host = 192.168.1.133[/shell]
OpenSSLの重大バグ(CVE-2014-0160)への対応
...こんにちは。小宮です。
OpenSSLの重大バグが発見されたという記事をうけまして、
さすがに影響が大きいようなので関連情報を記録しておきます。
OpenSSLの重大バグが発覚。インターネットの大部分に影響の可能性 | TechCrunch Japan
JVNVU#94401838: OpenSSL の heartbeat 拡張に情報漏えいの脆弱性影響範囲はopenssl-1.0.1~1.0.1fということで、まじめに最新にしてるサイトが影響を受けるという皮肉なことに。
でもまあ影響範囲が限定的なのは良かったと思います。
弊社ではCentOS6.5とAmazonLinuxの環境が影響を受けました。まず以下をご覧ください。
対策方法を記しているサイト:
AWS - EC2インスタンスのOpenSSLのHartbleed Bug対応 - Qiita
opensslのTLS heartbeat read overrun (CVE-2014-0160)を対処した | Ore no homepageバージョンの確認方法は
rpm -qa|grep opensslとか
openssl versionという感じで、
CVE-2014-0160をfixしてるパッチがあたってるかどうかは、以下のように確認しました。rpm -q --changelog openssl |head * 月 4月 07 2014 Toma? Mraz <tmraz@redhat.com> 1.0.1e-16.7 - fix CVE-2014-0160 - information disclosure in TLS heartbeat extensionあたってなければ、yum update opensslして
sshd、crond、httpd等のopensslを利用しているサービスを再起動しました。mysqlfailoverをデーモンになってから試してみた
...※ 古い記事ですのでご注意ください。
こんにちは。小宮です。
まだ使いたい人がいるかわかりませんが検証してみましたので載せておきます。
長い記事になりますのでお時間のあるときにどうぞ。mysqlfailoverを–forceつけず–daemon=startで起動させる
以前検証したときは
–forceつけないと動かなかったのと
デーモンで起動させるオプションは存在しなかった
というわけでそこを再度たしかめてみます。・構成:
192.168.1.133 komiya-test-mysql01 my1 192.168.1.155 komiya-test-mysql02 my2 192.168.1.150 komiya-test-mysql03 my3 192.168.1.241 komiya-test-mysql04 my4 manager 192.168.1.222 vip・インストール:
パッケージは公式とかこのへんからダウンロードできます。
とりあえずchefでmysql5.6とutility等を入れておきました。
ssh-copy-idとknife solo prepareして
nodeファイルのrunlistにdbロール指定して
knife solo cookしただけで以下と必要な設定ファイルが置かれて
server_idとかreport_hostとか自動的に入るようにしました。
参考にしたレシピはこちら。以下が関連パッケージです。
mysql-utilitiesはpythonで書かれたツールなのでmysql-connector-pythonが必要です。$ rpm -qa|grep -i mysql MySQL-shared-compat-5.6.15-1.linux_glibc2.5.x86_64 MySQL-test-5.6.15-1.linux_glibc2.5.x86_64 perl-DBD-MySQL-4.013-3.el6.x86_64 mysql-utilities-1.4.1-1.el6.noarch mysqltuner-1.1.1-1.el6.noarch MySQL-client-5.6.15-1.linux_glibc2.5.x86_64 MySQL-server-5.6.15-1.linux_glibc2.5.x86_64 MySQL-devel-5.6.15-1.linux_glibc2.5.x86_64 mysql-connector-python-1.1.4-1.el6.noarch mysqlreport-3.5-4.el6.noarch・replicaitonを組む
server_idはipアドレスの第4オクテットにしたので重複しないはず。
report_hostも自分のIPに自動的になってるはず。chef-soloのレシピのカスタマイズの記録
...こんにちは。小宮です。
おかげ様でカスタマイズする機会があったため、その一部を引用してご紹介いたします。基本的なことなどは、
以下のリンクや「入門chef-solo」とその落ち穂拾いもご覧になるとよいと思います。
Chef Soloと Knife Soloでの ニコニコサーバー構築 (2) 〜導入編〜:dwango エンジニア ブロマガ
chef-solo - Chefを読んで実行するための全知識 - Qiita
DevOpsを実現するChef活用テクニック // Speaker Deck
あとGW前後にchef実践入門的な書籍をエンジンヤード(chefが出る前から8年くらい使ってる会社)の御方が出されるそうで大変期待してるところです。chefのnode、role、enviroment、attribute、data_bagsの解説になります。
この記事は基本の説明とカスタマイズの為の簡単な情報提供になるかと思います。
以下に記載しているレシピを実際ためした環境はCentOS6.4のみで、申し訳ありませんが異なる環境での動作保障はできないです。
異なるOS間の動作保障するような汎用的(複雑)なレシピはopscodeコミュニティの☆がいっぱいついてるクックブックを使えばいいらしいです。
(余計なものを極力入れないとか既存の環境または手順をレシピ化するという需要には不向きかとは思います。)chefリポジトリ直下のディレクトリの解説を以下に記します。
cookbooks :サードパーティのクックブック置き場
data_bags :data_bagsのデータ置き場
environments :環境設定ファイル置き場
nodes :ノード(ホスト・各サーバ)設定ファイル置き場
roles :役割設定ファイル置き場
site-cookbooks :自作クックブック置き場(クックブックはレシピ、配布ファイル等を含む)各用語を以下に軽く解説します。
・ohai
chefに同梱されているレシピを適用するホストの情報を取得するコマンドです。
ohaiで取得した値に基づいてattributeを定義することが可能です。
たとえばOS搭載メモリやCPUコア数に応じて設定値を変えたい場合やホスト名や
IPアドレスなど固有の情報を設定ファイルに載せたい場合などに利用すると便利です。・node
nodesディレクトリ直下にhostname.jsonまたはipaddress.jsonというファイルを置き、
そこにそのサーバ固有の設定値(attribure)や割り当てる役割(role)を定義します。・role
dbやwebなど、同じ役割のサーバをroleでまとめ、同じ役割のサーバ群に適用するレシピ
やパラメータをまとめて定義します。AMIのバックアップをawscliで自動でとる
...こんにちは。OPSのほうの小宮です。
どうも社内で需要があるようだったのと、
javaよりpythonのツールが早いということで検索したけどawscliのは見つからなかったのでつくりました。
タグでとるとらない自動判定などはしておりません。bkup_numに世代数を指定すると複数世代とれるように直しました。
引数1にインスタンスID、引数2にホスト名を指定して実行する仕様です。
--no-rebootを付けてあるので稼働中のインスタンスが再起動されることはありません。
データ領域のEBSがあってもamiコマンドが勝手に複数とってくれるようだったので、
osデバイスかdataデバイスか判定してわかりやすいタグつけるようにしてみました。※※要注意※※
--no-rebootつけてAMIを取得する対象がMyISAMストレージエンジンのmysqlのDBサーバだった場合に、データが壊れて止まるという現象が発生しました。
InnoDBじゃない場合にどうしてもAMI取得したい時はメンテ推奨で止めてやるのがよいかと思われます。
※AWSでは無停止でのAMI取得に関するデータの整合性は保証しておりません。
参考URL:http://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/creating-an-ami-ebs.html
ということはストレージ系のサーバは気をつけたほうがよい(メンテ推奨)ようです。・awscliが入ってなければインストールする
入れ方参考:(入ってない場合はpip install awscliとする。pipはeasy_installで入れる)
AWS Command Line Tool Python版 | Developers.IO
pythonでeasy_install - ハネ@日記
AWS Command Line Interface(awscli)を使ってみた - 元RX-7乗りの適当な日々スクリプトから呼ぶAWSのアクセスキーとリージョンの設定ファイルを作っておきます。
[shell]# cat /root/.ec2/aws.config ———— [default] aws_access_key_id=<アクセスキーID> aws_secret_access_key=<シークレットアクセスキーID> region=ap-northeast-1 ————[/shell]
・コマンドの調査(いちおう載せておきます)
[shell]# aws ec2 copy-image help ———— copy-image DESCRIPTION Initiates the copy of an AMI from the specified source region to the region in which the request was made. リージョン間コピーなのでいま要らない。 ———— create-image Creates an Amazon EBS-backed AMI from an Amazon EBS-backed instance that is either running or stopped. create-image [–dry-run | –no-dry-run] –instance-id–name [–description ] [–no-reboot | –reboot] [–block-device-mappings ] Command: Android Expansion files(拡張ファイル) アップロード
...拡張ファイルのアップロード方法がわかりません。
Devleloper Consoleのヘルプを見ると注: 現在のところ、新しい Google Play デベロッパー コンソールの制限により、新しいアプリをアップロードする最初の APK ファイルに拡張ファイルを追加することはできません。この問題を回避するには、まず APK ファイルのみをアップロードし、必要に応じて拡張ファイルを追加した APK ファイルで置き換えてください。これらの操作はドラフト状態の APK でも行えますので、既存ユーザーや潜在ユーザーに影響が及ぶことはありません。
どうやら拡張ファイルを追加できない事はわかります。しかし回避するための方法がわかりません。
「拡張ファイルを追加したAPKファイルで置き換えてください」?
それじゃあ、APKと拡張ファイルが一体化しているじゃないですか!頑張って調べてみると
がヒット。
it’s a dummy apk. When you first upload your apk you will not have any option for the expansion files. From second apk onwards you will have that option. It looks weird
TortoiseGit + GitHub + port 443
...TortoiseGitとGitHubで快適にGit生活を送っていたのですが、ある日突然pullできなくなりました。
どうも GitHubとの22番ポート経由での通信ができなくなった模様。なぜ?
22番といえばsshのポート。AWS上のサーバーにもガシガシsshしているので、社内ネットワークの
どこかで閉じているとは考えられません。GitHub側から締め出しをくらったのかなぁ?
仮にも有料プランユーザーなのにそんなことあるの??結局原因不明ながらも 443番ポート経由で通信するように環境を変更することで対応しました。
TortoiseGitとGitクライアントはインストールされている前提です。インストール方法は以下にとっても良くまとまっています。
- ssh クライアントを切り替える
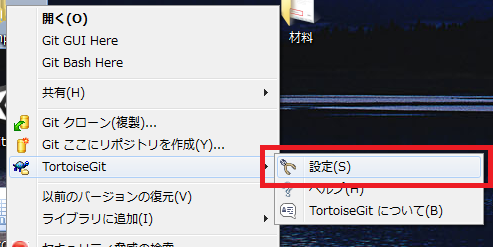
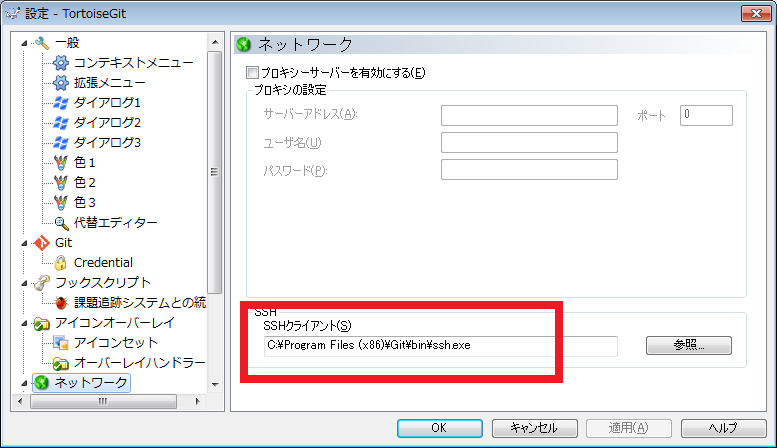
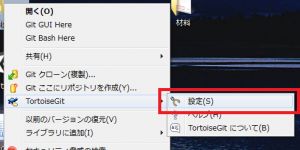 右クリックしコンテキストメニューを開き、そこからTortoiseGitの設定を開きます。
右クリックしコンテキストメニューを開き、そこからTortoiseGitの設定を開きます。
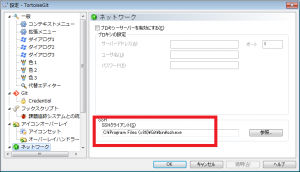
左ペインのネットワークを選択し、右ペインに表示されたsshクライアントが以下でなければ変更します。C:\Program Files (x86)\Git\bin\ssh.exe
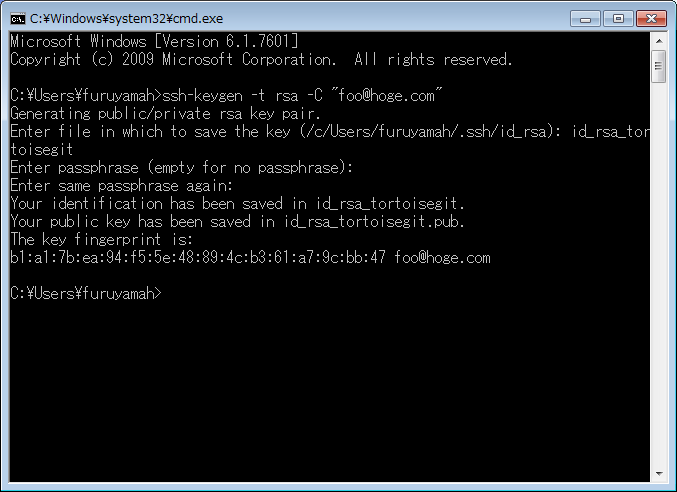
- 鍵を再作成する
TortoiseGitを使っている場合おそらく標準であろうTortoisePlink.exeをSSHクライアントに設定している場合
証明書に自動的にパスフレーズが設定されるらしく他のsshクライアントでは再利用できないので、再作成します。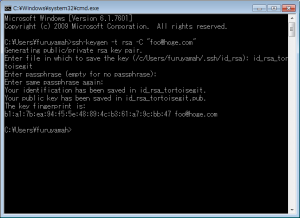
$ ssh-keygen -t rsa -C “メールアドレス”- GitHubに公開鍵を登録する
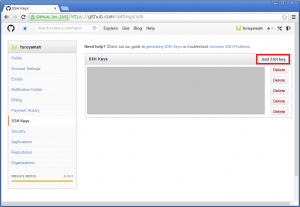
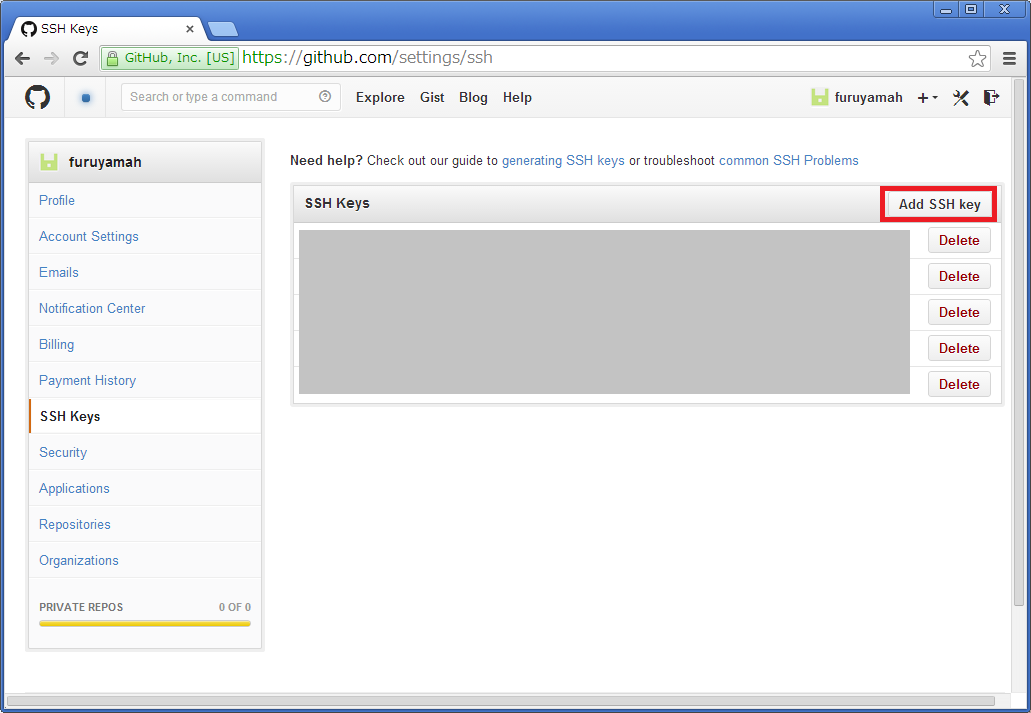
GitHubのサイトに行き先程作成した公開鍵(*.pub)の内容をコピペします。- ssh設定ファイルを作成する
以下のファイルを作成します。CloudFormationを使いredmineのインスタンスを起動する
...おはようございます。インフラの宮下です。
社内向けredmineが古いのでリプレイスを検討しています。
できるだけ手間をかけずに検証環境を用意したいと思い、AWSのcloudformationを使って
redmineを用意してみました。目次
はじめに
現在稼働しているredmine環境が物理サーバにバージョンがRedmine 1.1.2.stable (MySQL)ととても古いので最終的には入替まで実施したいと思います。
CloudFormationでインスタンスを作成する
ManagementConsoleからCloudformationの画面を開きます。
「Create Stack」で新規作成を開始します。・Name→管理しやすい名前を自由につける。
・Template→Use sample templateの中のSingleInstanceSamplesの中から「Redmine Project Management System」を選ぶ。
※検証環境なので今回は最小化された構成で構築します「Next Step」で次に進みます。
Specify Parametersにそれぞれ値を入れていくのですが、デフォルトではkeyを指定する事ができませんでした。
という事で一旦「Back」で戻ります。
amazonが公開している下記のテンプレートをローカルPCに保存します。
https://s3.amazonaws.com/cloudformation-templates-us-east-1/Redmine_Single_Instance.template
サンプルとの違いは、KeyNameの定義が入っているだけですのでSSHログインしないというのであれば
この作業は不要です。[shell](8行目) “KeyName”: { “Description” : “Name of an existing EC2 KeyPair to enable SSH access to the instances”, “Type”: “String”, “MinLength”: “1”, “MaxLength”: “255”, “AllowedPattern” : “[\\x20-\\x7E]*”, “ConstraintDescription” : “can contain only ASCII characters.” },
SSHでforced-commands-onlyを使ってVIPを付けてみる
...おはようございます。インフラの宮下です。
今回は端末機からサーバの仮想IPを付けたり削除する時のSSH設定に関する手順です。
MHAの内部でIPをfailoverする所をお手製で実施するイメージです。SSH接続でroot権限を実行する方法としては、
・rootで公開鍵認証が出来るようにする。
・ログインユーザがsudo出来るようにしてrootにスイッチする。
・rootで特定のコマンドだけ実施出来るようにする。の3通りありますが、今回はセキュリティレベルがそんなに変わらない3番目の方法を適用したいと思います。
既にsudo出来る環境なら良かったのですが、sudoできない環境なのでforced-commands-onlyを使用します。作業環境は以下の通りです。
接続元のOS:SunOS test 5.10 Generic_147440-19 sun4v sparc sun4v
→端末機と呼びます
接続先のOS:Red Hat Enterprise Linux Server release 6.2 (Santiago)
→サーバ呼びます今時珍しいsolarisが端末と言う事でレトロ感満載の環境と言う事はお察し下さい。
(端末機の設定)
・ログインするユーザの公開鍵を作成します。コマンド毎に鍵を分けるので2個用意します。
[shell]# ssh-keygen -t rsa -N "" -f ~/.ssh/ipadd_command 公開/非公開 rsa 鍵のペアを生成しています。 識別情報が /export/home/test/.ssh/ipadd_command に保存されました。 公開鍵が /export/home/test/.ssh/ipadd_command.pub に保存されました。 鍵のフィンガープリント: 80:1e:4f:8b:2a:0d:22:fb:e2:c7:22:75:70:ef:db:a2 test@test
要素が1つしかない連想配列のネストを解消する
...WordPress関数(特に$wpdbクラスなどに多い。
get_results()メソッドでDBの値をとって来たときなど)を使っていて、戻り値の配列が一つしか要素持ってないのに連想配列になっていたりする場合、値を取り出すときにネストしたループ処理を書くケースが結構ある。 以前からコード的に冗長で非効率だよなぁ…と思っていて、今回改善方法を見出してスッキリしたので、ここにTIPSとして残しておこうかと。$array = array( array( 'key_1' => 'value_1', 'key_2' => 'value_2', ), ); foreach ($array as $nested_array) { foreach ($nested_array as $key => $value) { echo 'array["' . $key . '"] => "' . $value . '"<br />'; } }今まではこんな感じに(無駄ではないのだが、効率的ではない)foreachループを連想配列の入れ子分回して値取ってた…。 で、この連想配列とループのネストを解消してシンプルに処理を書けないものか…とPHPのarray関数を色々と試してみた。
array_reduce()とかarray_walk()とかあんまり使わない関数で、独自にネスト解消用の関数組んでもできるんだが、別途独自関数用意しなきゃならなくてまるでスマートでない…。なんかスパっと1ラインで解決できないかと試行錯誤してみたところ、ありました!array_shift()で先頭要素取得して元の配列変数を上書きしてしまえばいいのです。$array = array_shift($array);たったこれだけ(笑) でも、これだけだと配列の要素数が1つ以上でも上書きしてしまうので、要素数の判定を入れておく。
$array = (count($array) == 1) ? array_shift($array) : $array;最初のコードをこのコード使って書き直してみると、