packerでhvmでもresize2fsをできるようにしてrebootを回避する
...こんにちは。小宮です。 packerでhvmでもresize2fsをできるようにしてrebootを回避するというのをやってみました。
おなじことがcloud-initを用いてもできるような気がしています。 CentOS 6 (HVM)にcloud-initを設定してAmazon Linuxぽくする | Developers.IO ただしpackerつかってるのでそっちでやったほうがラクというか。 何も設定せずにcloud-initいれただけのamiつくったらログインできなかったですorz 設定ファイルに書いた内容と具体的に裏で何してくれちゃうのかちゃんと理解できないとやりたくないけど調べるのが手間だったので。 軟弱ものですみません。
・事の発端 CentOS6.5のオレ俺AMIをもとにhvmのインスタンス作ったところ、 chefレシピで流して自動でresize2fsがrootボリュームに対して実施されたはずが サイズ変わらず。 10から50GBになるはずだったけど10GBのままになっていた
・とりあえずぐぐる 以下URL先で同様の現象と対策を知る EC2のCentOS-HVMでディスクのサイズを変更する | Hack fdiskで拡張するほかにこんなやり方もあったんだーと目からうろこ。 でもってreboot必須って詰んだー!と思いました。(手間と自動化的に) 具体的にいうとresize2fsはchefレシピ流してやってるのでログインしてやるのは二度手間です。
・問題提起というか相談してみた (ぎじゅつ的に)とんがり系のおかたに、 パーティションテーブルの問題なら以下URLのようなのをpackerに仕込んだらどうか と提案いただいたというか教えていただきました CentOS on Amazon EC2 でディスクサイズ変更しても変わらないときの対処方法 | Developers.IO
・実際やってみたら成功した
packerに仕込んでるシェルスクリプトに以下を追加
+# growroot等をepelからインストール +yum -y --enablerepo=epel install dracut-modules-growroot cloud-utils + +# rootパーティションテーブルをリサイズ +dracut --force --add growroot /boot/initramfs-$(uname -r).imgで、packerでAMIをビルド、 そのAMIから作成したインスタンスにchefレシピを流してみると、 dfしてみたところディスクが拡張されてました。 rebootしなくて済んだ!!わーい! めでたしめでたし。
AWS S3を早くするフォルダ構成
...こんにちは、豊部です。
AWS S3をコンテンツデータのストレージに使う場合、転送速度が気になります。
S3は無限ともいえるストレージ領域がありますので、裏では様々な処理が行われ、
全世界で負荷をシステム全体でならすように設計されています。
このシステム全体をならす仕組みをフォルダ構成から利用できます。
ポイントは
・フォルダ名の先頭3文字でS3内で分散させている
です。
たとえば、コンテンツを3つのフォルダに分ける場合、
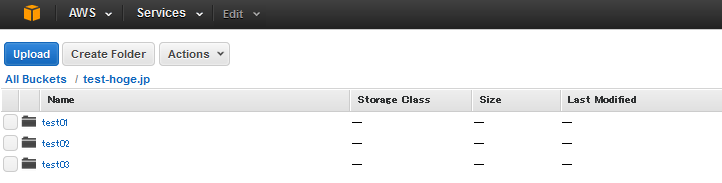
のようにしてしまうと、先頭3文字が「tes」となり、同じ場所に格納されてしまいます。
そこでフォルダ名の先頭にハッシュ値を頭につけて
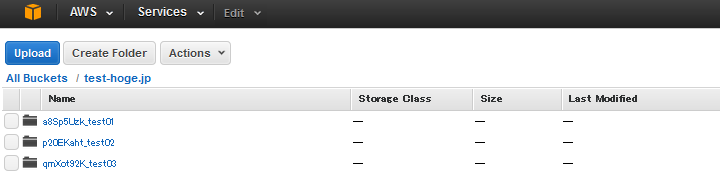
としましょう。
こうすれば、S3内で分散されて格納されるため、転送速度が向上します。
S3を配信コンテンツのストレージにする場合は、試してみてください。
data_bagsの用途について
...こんにちは。小宮です。 data_bagsについて内部的に解説する必要が生じたのでこちらにも書いておきます。
最近のdata_bagsの活用方法は以下のとおり
1.LDAPで管理していないシステム用途のOSユーザ情報をロードしてレシピで追加 2.SSL証明書の格納とレシピからロードしてtemplateで設定 3.ntpサーバの情報のロードとtemplateで設定 4.awsのクレデンシャル情報を管理して各種スクリプトへ埋め込み 5.mysqlやldapなどのパスワードなどアカウント情報の管理 6.roleとenvironmentに収まりきらないnginxやapacheのvhostやupstream等の情報の管理 7.gangliaのhead_nodeやcluster_nameの情報の管理
0.下準備的な解説
※前提条件としてchef-soloの場合"knife-solo_data_bag"というgemが必要なので入れる。 (gem listでなければgem installかbundlerで入れてください)
格納方法と確認方法
暗号化しない場合、viなど任意のエディタで編集OK chef-repository/data_bags/任意のディレクトリ名/任意のファイル名.json をつくる。 中身はjsonの規則にのっとっている必要があるので、シンタックスをjson_verifyでCHK。
cat data_bags/dirname/filename.json |json_verify で、JSON is valid と出るのを確認する
暗号化する場合、 まずEDITORの環境変数を~/.bashrcなりに設定しておく必要があるのと暗号化用の鍵を作って設定しておく必要がある。 (※鍵は案件ごとに異なるイメージで、.gitignoreに書いとく必要があります。 流出厳禁かつ無くすとデータが見えなくなります。)
export EDITOR=vi vi .chef/knife.rb ------コメントを外す--------------------- encrypted_data_bag_secret "data_bag_key" -----------------------------------------※コメント外すと鍵指定しなくてもknifeコマンドでcreateした場合常に暗号化される ゆえに暗号化せず扱いたいデータファイルはviで作るかコメントインしてから作る必要有
鍵が必要なら作る (※.chef/knife.rbの相対パスはchefリポジトリ直下を意味します)
openssl rand -base64 512 > data_bag_key knife solo data bag create dirname filename # 作成(※既存は上書きされる) knife solo data bag edit dirname filename # ファイルをエディタで編集 knife solo data bag show dirname filename # jsonの中身を表示 knife solo data bag list # ディレクトリ一覧表示・注意するべきこと →bashやexecuteリソースは極力使うべきではない。templateリソースつかってください。 bashでsedるとdata_bagsから変数に入れた特殊文字が展開されて意図しない値が入ったりします もうひとつ、sedると毎度毎度同じsedをする必要が生じるなど冪等にならないです。
フロントエンド開発ツールマップみたいな何か。JavaScriptフレームワーク、AltJS、CSSプリプロセッサ、HTMLテンプレートとかまとめ。
...2月1日より社員になりましたくぼたなるひとです。初ブログです。つーかいっそ今日から社員なので初業務です。
ちなみにデザイナーです。でもフロントエンドエンジニアになりつつあります。でもデザイナーです。
はい、意味不明な前置きはやめて本題です。 今日はフロントエンド開発ツールについて概観してみようと思います。 「やっぱりフロントエンドエンジニアじゃねえか!」とか言わないでください。
HTML/CSS/JavaScriptだよね。
フロントエンド開発の人が扱うものといえば、基本はHTML/CSS/JavaScriptという認識ですよね。 その他ツールとしてはブラウザとエディタさえあれば、極端ですが即開発できます。簡単ですね。 およそ間違ってないですね。 こんな感じ。

フロントエンド開発に携わっていない方の認識はざっくりとこんな感じだと思います。 およそ間違ってないですね。(2回目)
ベストプラクティスを追い求めてみた。
さて、では開発のベストプラクティスを求めていくとどうなるでしょうか。 ぱーっと思いつく限りで一覧っぽくしてみようと思いました。
こんな感じ

は?
嘘だ・・・・・・夢だろ・・・・・・これ・・・・・・夢に決まってる・・・・・・・・・!
ところがどっこい・・・・・・夢じゃありません・・・・・・!現実です・・・・・・!これが現実です・・・!
フロントエンドエンジニアに求められているものは右肩上がりに増え続けています。もちろんお給料はきっと据え置きです。世の中無情である。
言うまでもなく、技術を追い続けるか、知らんぷりするかは個人の裁量に委ねられる訳ですが。
どうしてこんなことになってるわけよ?
/)( ◕ ‿‿ ◕ )(\ わけがわからないよ
要因1 - Webのリッチ化&モバイル化
Ajax
非同期通信の使用したUI構築技術。ページ遷移せずにデータを持ってこれる。 これのおかげでGoogleMapsが使えると思えば感謝せずにはいられない。 今ではページ遷移しないでいろいろできるなんてふつうの感覚になっているが、それくらい当然のように恩恵を受けている技術です。
他にもすごーくたくさん増えたものがあります。
- クロスサイトスクリプティング
- クロスサイトリクエストフォージェリ
- SQLインジェクション
厨二病っぽい感じありますね。心がくすぐられます! 全部セキュリティ問題です。 統計的に見ると3つトータルで1,000件/年間くらい起きてるらしいです。それまでほとんどなかったのに。統計データのグラフとかどっかから引用したかったのですが、じょうほうじゃくしゃなので見つけられませんでした( ◠‿◠ )うーむ 詳しく知りたい人は以下のリンクへどうぞ。とてもよくまとまっています。
俺とfavicon(ファビコン)の面倒くさい関係
...こんにちは。UIデザイン担当の塚田です。
今日は、WEBサイトに付きもの**favicon(ファビコン)**についてお話します。
デザインやっててロゴデザイン開発とかサイトデザインは楽しく進められるんですが、
コーディングなどフロントエンドの構築はいつも別のスタッフに任せていました。
そして意外におろそかになりがちなのが、favicon(ファビコン)。。

一昔前は、PCのWEBサイトのブックマークとか、URL入力枠の横辺りにさりげなく
サービスロゴが掲載されてるピクトアイコンという程度の認識でした。
最近とある案件で作成することになり、favicon(.ico)ファイルの作成方法を探していたら、
とあるブロガーがfaviconの種類について掲載されていました。
なんと!21個もあるとのことっ!!
faviconのリスト favicon.ico: IE用 favicon-16x16.png: タブ表示用 favicon-32x32.png: Mac版Safari用 favicon-96x96.png: Google TV用 favicon-160x160.png: Opera 12 までのスピード・ダイアル用 favicon-196x196.png: Android版Chrome用 mstile-70x70.png: Windows 8 用 mstile-144x144.png mstile-150x150.png mstile-310x310.png mstile-310x150.png apple-touch-icon-57x57.png: iOS用 apple-touch-icon-60x60.png apple-touch-icon-72x72.png apple-touch-icon-76x76.png apple-touch-icon-114x114.png apple-touch-icon-120x120.png apple-touch-icon-144x144.png apple-touch-icon-152x152.png apple-touch-icon.png apple-touch-icon-precomposed.png
(以下、「IT探検記」さんのまとめより引用)
DBのプライマリキーは複合主キーではなく、サロゲートキーを使うべし
...別件でUnicodeの「サロゲートペア」について調べていたところ、データベースの「サロゲートキー」と「複合主キー」についての記事が サロゲート つながりで引っかかって来て思いっきり脱線しました(笑)
そんなこんなで、あまりデータベースに慣れ親しんでいないと、「サロゲートキー」「複合主キー」「ナチュラルキー」って何?──となる人は多いはずなので、自分自身のおさらいも兼ねて一度まとめておこうかと思った次第。
プライマリキー(主キー)
データベースのたいていのテーブルに存在する、データを一意に管理するためのキー制約。このキーが指定された列中には重複する値を入れることができず(ユニークキー制約)、空白(NULL)にすることもできない。
ユニークキー(一意キー、ユニークインデックス)
このキーが指定されている列中には重複する値を格納できず、一意にならなければならないというキー制約。ただし、プライマリキーと異なり空白(NULL)は格納可能で、空白(NULL)のみは重複ができる。このキーが指定されると同時にインデックスも貼られるため、ユニークインデックスと同義である。
サロゲートキー(代理キー)
オートインクリメント属性等により、連番の数値が格納されているユニークな値を持つカラムに対してプライマリキー制約を付与した場合のプライマリキーのこと。テーブル内で一意となる唯一の行レコードを特定するための列の集合(ナチュラルキー)を代替するため代理キーとも言われる。単一の列で全行レコードの一意性を識別できるのでシステム的に有益なのだが、実サービス等に利用するデータとしては意味をなさず、データ利用者側の観点からだとデータベースの物理ストレージ領域を無駄に圧迫する列でしかない。
ナチュラルキー(自然キー)
テーブル内の行レコードを特定するためのユニークキー制約のついた列の集合のこと。行レコードの一意性が識別できれば単一の列でもかまわないが、例えば、WordPressだと「投稿ID」「タグID」の組み合わせで、とあるタグに属する投稿データを一意に識別できるような場合、それら2列の集合体がナチュラルキーと呼ばれ、そのナチュラルキーを持つテーブルが
wp_term_relationshipsだ。原則的にナチュラルキーに含まれる列はユニークキー制約をもっていなければならないため、プライマリキーに設定されていることが多い。データ利用者側の視点では、意味あるデータのみによって一意性が識別されるナチュラルキー型テーブルは用途が明確で無駄がない(と見えるようだ)。複合主キー
複数プライマリキー、サロゲートキー+ナチュラルキー、プライマリキーなしの複数列集合のナチュラルキーのみといったテーブルが複合主キー型のテーブルといえる。要は単一列のみで行レコードの一意性が識別できないタイプのテーブルである。他のテーブル同士をリレーションさせるために外部キーの結合のみを管理するようなリレーションテーブルによく見られるタイプ(ナチュラルキーの項で紹介した、WordPressの
wp_term_relationshipsテーブルなど)。リレーションテーブルを覗いたことがある人やDB設計したことがある人には良く理解できるはずだが、このような複合主キー型テーブルはそれぞれの外部テーブルのサロゲートキーを集中管理するような構造になっていて、実データのリレーション関係が一目ではわからないのが常だ。かといって、ナチュラルキーをプライマリキーとしたテーブルのプライマリキーを外部キーとしてリレーションさせるとそのリレーションテーブルを見るだけでデータの結合性が一目でわかるものの、参照コストの高い文字列データ等がデータベース内に重複して存在することになって、データベース全体としてパフォーマンス低下を招く上、物理ストレージ領域の圧迫もサロゲートキー以上に進んでしまう。 また、特にナチュラルキーが一意性識別に関与するようなテーブルだと、ユニークなデータを取り扱う際のシステムコストが高くなる。言葉の整理をしてて改めて感じたのだが、複合主キーのテーブルを操作するのは結構面倒そうだということ。まぁ、実際に面倒なんですがね。例えば、複合主キーのナチュラルキーのうち一つの列の値を変更したい場合、その行レコードを特定するために同じナチュラルキーを検索条件に入れなければならなかったりして、ちょっと処理を考えるのがイヤになる。 プライマリキーが二つ以上あるテーブルをUPDATEしようとするとMySQLに怒られたりするしね…。
私個人の結論としては、データベースは人ではなく、システムが応答し易いように作った方が良く、パフォーマンスを犠牲にしてまで人間側のデータ視認性にこだわるのは本末転倒だと思いますね。人間側に認識し易いデータは別途中継処理等を作って整形してあげるのがデータベースを利用するシステムの正しいカタチではないかと。なぜなら、人間側が要求するデータは、時と場合と人によってフィルタリングさせないと有益なデータにならないケースがほとんどだから…。つまり、プライマリキーは、複合主キーとかは使わず、サロゲートキーを使うのがベストプラクティスだと思うわけです。
Amazon Linux に Moodle2.8.2 をインストールする方法
...eラーニングパッケージMoodleをインストールする機会がありまして速攻でggったところ
がヒット。
あまりに詳細な内容に勝ったな、、と思いつつセットアップしたところMoodleバージョンアップによる地雷が埋まっていたため地雷除去メモを作成しました。
Amazon Linux AMI 64biをセットアップ <-変わらず
phpとMySQLのインストール <- ココ!
上記リンク先の手順通りやると、以下のメッセージにぶちあたります。
Moodle 2.7 or later requires at least PHP 5.4.4 (currently using version 5.3.29).<br />Please upgrade your server software or install older Moodle version.てか、Amazon LinuxのPHPって5.3なのかよ!
ということで、以下のコマンドでphp5.5,MySQLをセットアップ
apache2.4とphp55-mysqlndあたりがポイントです。
sudo yum -y update; yum install httpd24 mysql-server git php55 php55-gd php-pear php55-mbstring php55-mcrypt php-zts php55-xmlrpc php55-soap php55-intl php-zip php55-xml memcached php55-mysqlnd php55-pecl-apc php55-common sudo chkconfig mysqld on sudo chkconfig httpd on sudo service mysqld restart sudo service httpd restart sudo mkdir /var/www/moodledata sudo chown apache:apache /var/www/moodledata3.DB作成 <-変わらず
AWS : EC2 C4インスタンスリリース!
...今月の初め、AWS より EC2 サービスにて新しいタイプのインスタンス、 C4 インスタンスの提供開始とのアナウンスがありました。
トピックを共有したいと思います。
- Intel が AWS 専用にカスタマイズして提供している Haswell ベースの CPU を採用。
- EBS 最適化オプションを標準装備。その代りSSD ベースのインスタンスストレージは無し。
- 利用できる仮想化タイプは hvm のみ。PV (paravirtual) は利用できません。
- 拡張ネットワーキングも標準装備され、低遅延化などが施されている。
パフォーマンスの劇的な向上や新しい何かを期待されていたユーザー様は残念がっている方もいるようですが、
HVM のみのサポート、CPU、ストレージ、ネットワーク周りの底上げを行っており、インフラとして順当な進化を遂げているなぁ、というのが僕の感想です。
AWSのCloudwatchにアラート(Alarm)を設定し、監視する
...こんにちは。新人の橋本です。
これまではオンプレミスのハイブリッドクラウド(プライベート+パブリック)や物理サーバにて運用構築業務についてましたが、
AWS自体は初めて取り扱う環境ですので、その目線から、ブログを書いていきたいと思います。
今回はAWS導入後、基本的なリソース監視ができるCloudwatchの設定、およびAlarmを設定し、閾値を超えたらEメールを送付するという
ごくごく基本的な設定について記載します。
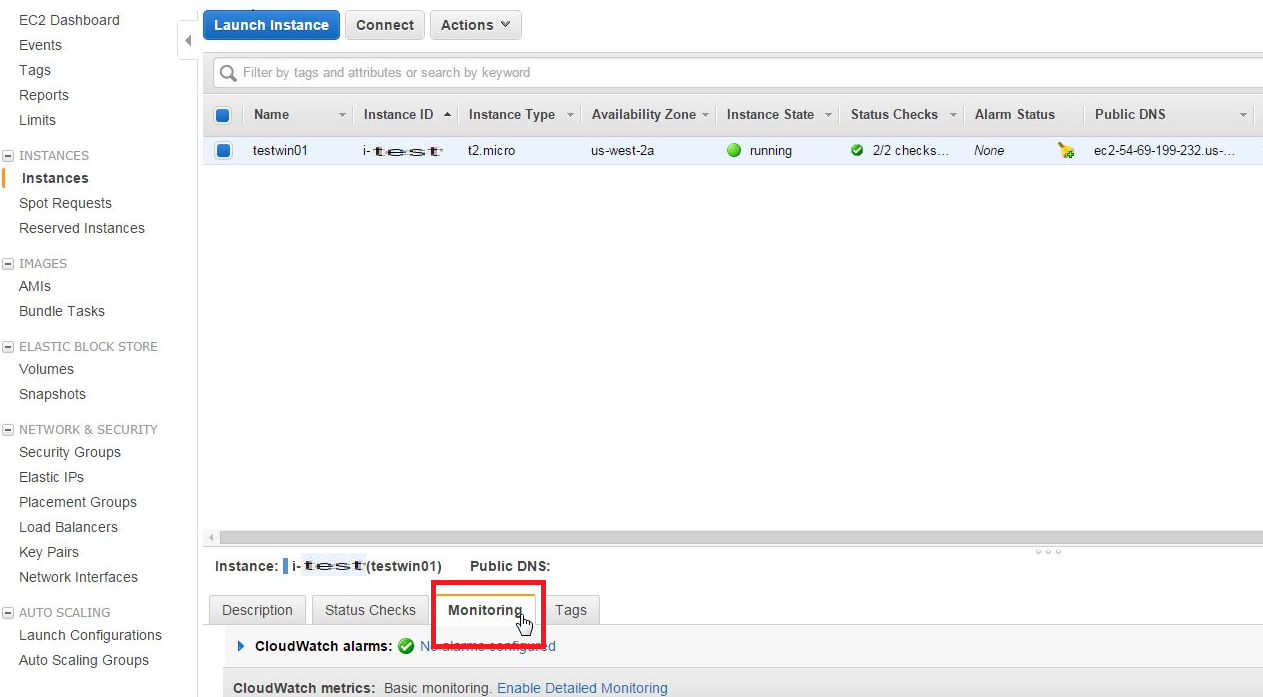
1)設定画面
EC2にてインスタンス作成後、EC2の[Instance]項目にてにてAlarm設定したいインスタンスを選択し、[monitoring]タブを選択します。
2)Alarm設定
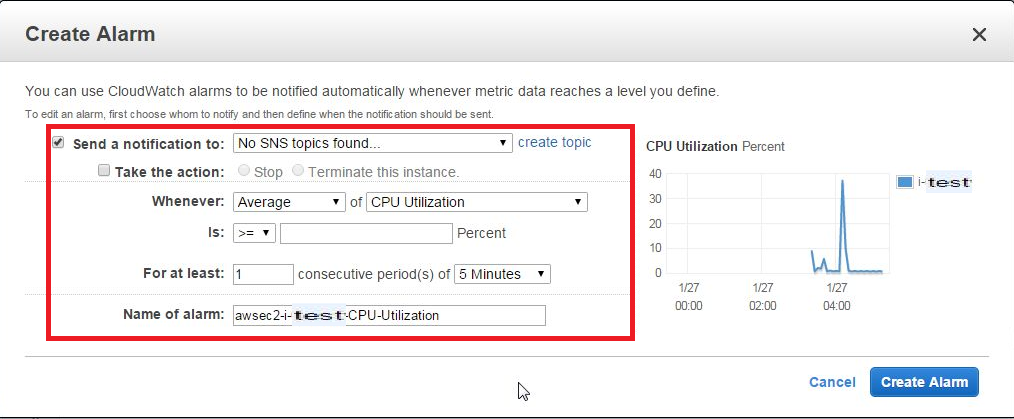
右部分にある[Create Alarm]を選択すると、CreateAlarm画面が表示されるため、各項目を入力します。
- Send a Notification to → 別項目にて、SNS topicを作成している場合、リストに追加されます(今回は追加しません)
- Take the action → Alarm発生時のアクション。発生した場合どうするかを選択できます(今回は設定しません)
- Whenever → リストより程度(Average,Max,Minimumなど)、および項目(CPU Utilization、Disk Usageなど)を選択します
- Is → 閾値(○○パーセント以上or以下など)を設定します
- For at least → 判定条件(○分間毎に△回[Whenever]項目が[Is]だった場合にAlarmカウントする)を設定します
- Name of Alarm → Alarm名を設定します
3)設定追加
各項目設定後、右下の[Create Alarm]を選択すると、Alarm項目が作成され、次の画面が表示されるので、リンクをクリックします。
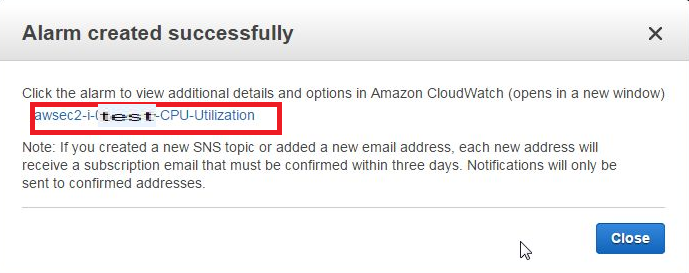
4)項目追加確認
CloudWatch Management Console画面に遷移するため、項目が追加されたことを確認し、[Modify]タブをクリックします。
【AWS】CloudWatchを使ってEC2インスタンスのリソース状況を確認する
...はじめまして、ディレクターの白川です。
AWSではGUIから様々なサービスが利用出来るので、ディレクター職の自分にも非常に優しくていいですね。
さて、Webサービスを運用していくためには、インフラの稼働状況を監視することが必要不可欠です。 機器自体の死活監視に加え、メモリやCPU、ディスクなどのリソース使用状況を常にモニタリングし、負荷状況に応じて適切な対応を行わなければなりません。
そこで今回は、AWSが提供するクラウド監視ツール、CloudWatchを利用してEC2インスタンスのリソース使用状況を確認する方法についてご紹介します。
1.CloudWatchの確認方法
AWSマネージメントコンソールにアクセスし、メニューの中からCloudWatchを選択します。
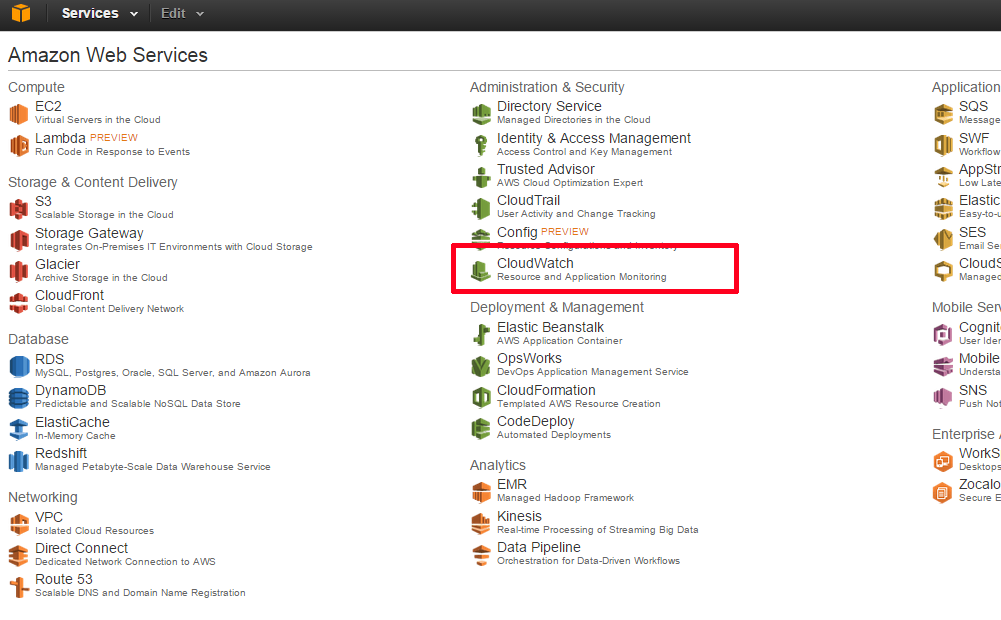
画面左の「Dashboard」の中から、[EC2]を選択します。
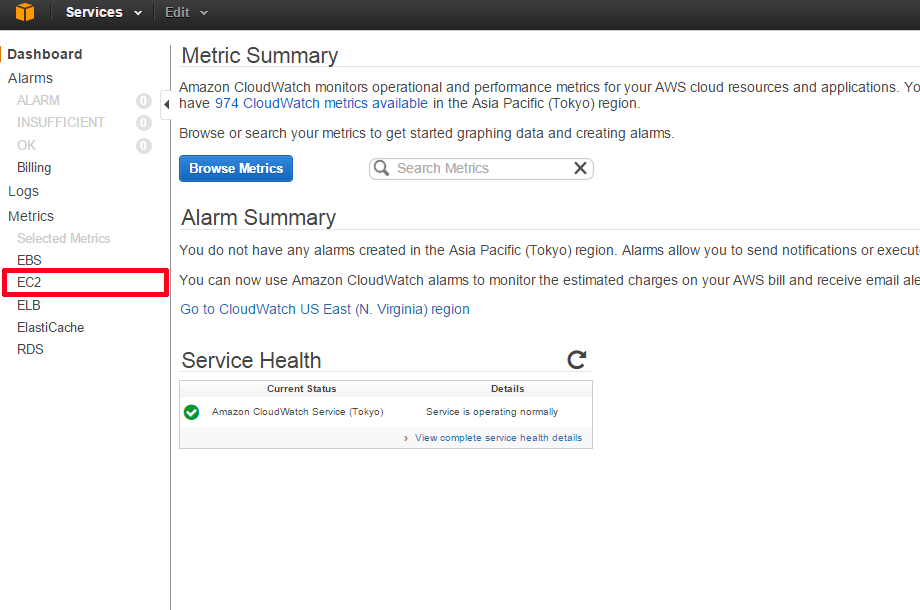
インスタンス毎のIDとメトリクス名が表示されます。グラフを表示したいインスタンスとメトリクスの組み合わせを確認し、チェックボックスにチェックを入れます。
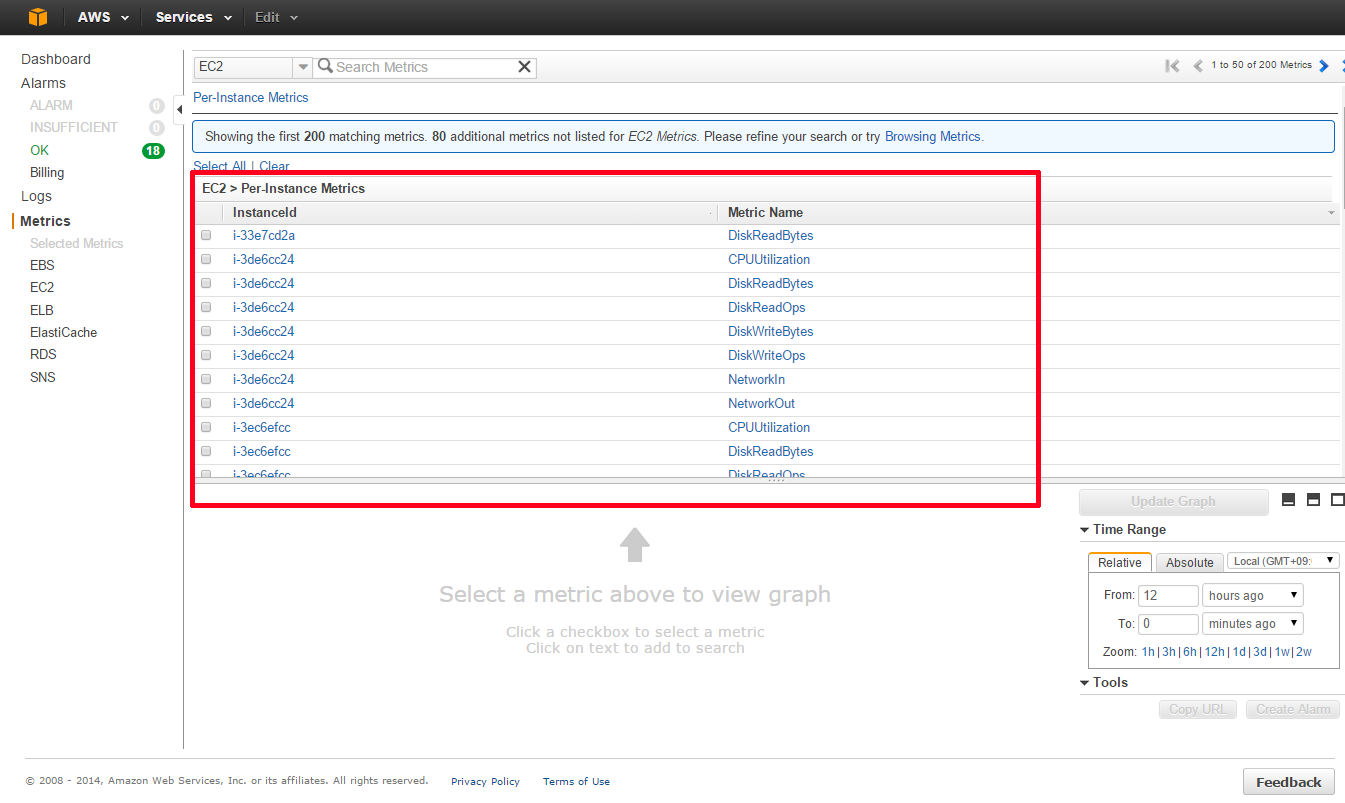
画面下にグラフが表示されます。 ※図はCPU使用率を表示したイメージです。
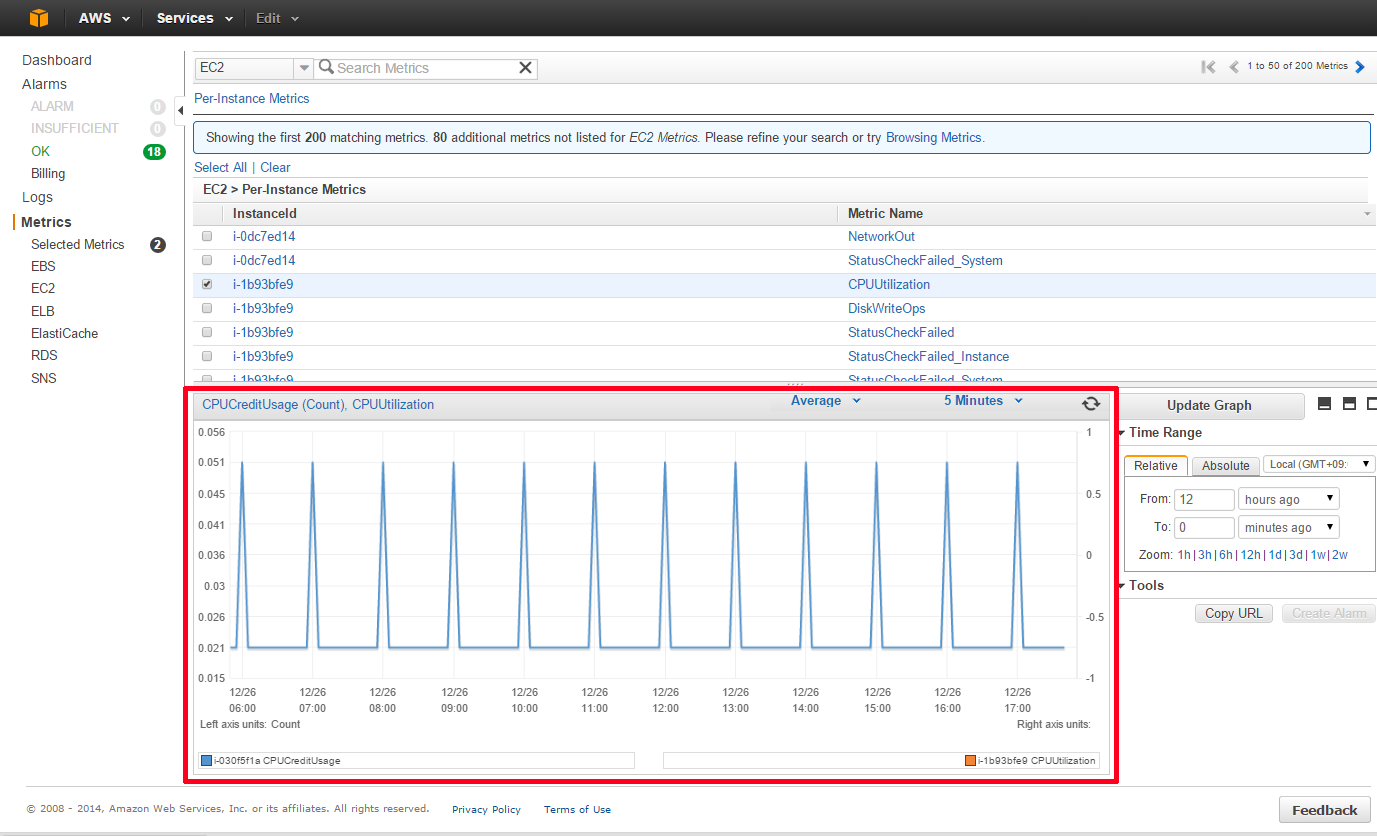
2.グラフの見方
[Average]というドロップダウンボックスが、各データの集計方式(Statistics)を指します。 それぞれ、平均(Average)、最小値(Minimum)、最大値(Maximum)、合計(Sum)が選択出来ます。 ※データサンプル数(Data Samples)は、サンプルとして取得したデータの数になります。こちらは、CPUやメモリなどの使用状況を確認する上ではあまり使用しないかと思います。
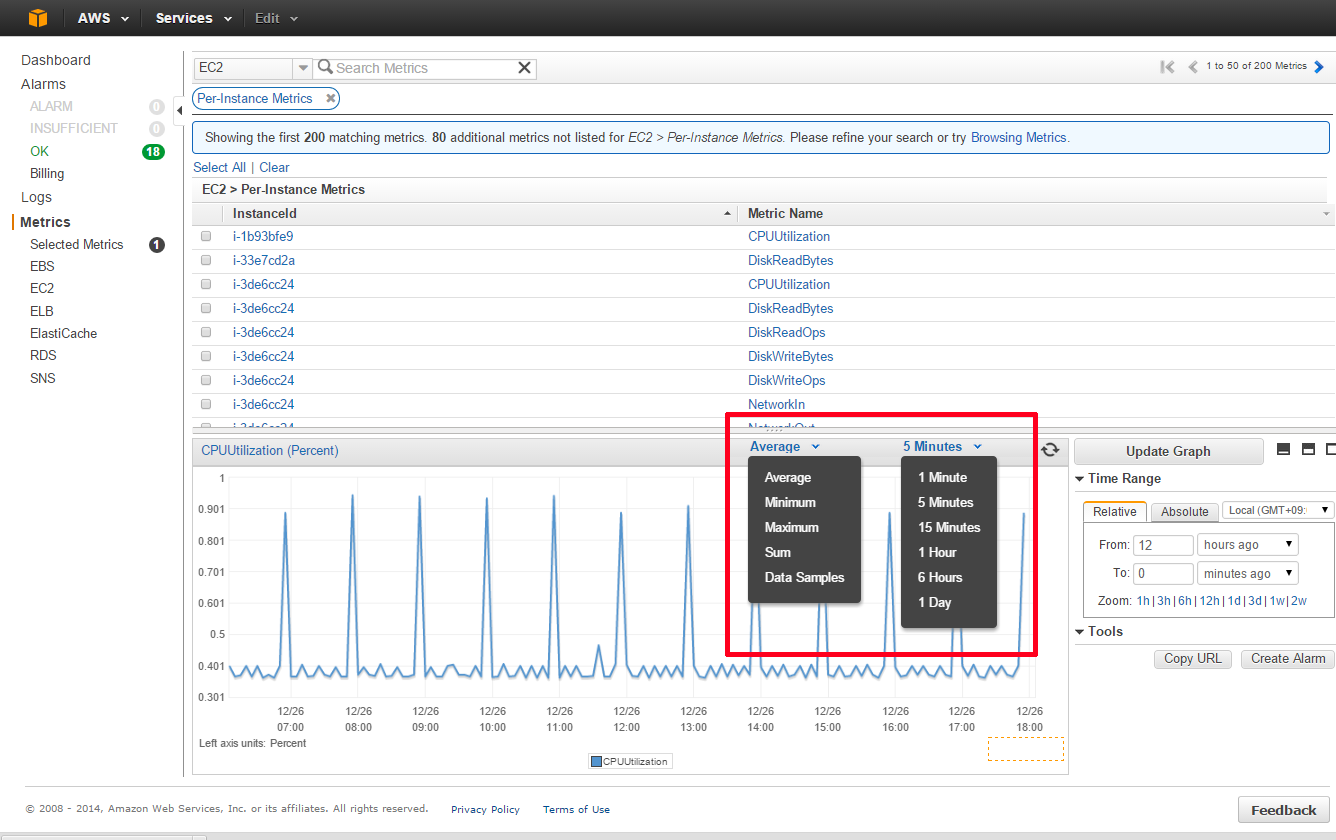
3.CloudWatchで確認出来る、EC2の標準メトリクス
CloudWatch上で確認出来るEC2のメトリクスなどは、下記のAWSドキュメントを確認ください。
4.まとめ
CloudWatchでは、今回ご紹介したEC2のリソース以外にも、RDSやELB、Auto Scalingなど様々なAWSリソースの監視が可能です。 ただし、CloudWatchの統計は2週間しか保存されないため、長期的なスパンでのリソース分析には向きません。 そういった場合は、Zabbixなどの高機能な監視ソフトウェアの利用を検討する必要があります。
ISAOでも、Zabbix等を利用した高レベルなクラウド監視実績が多数ありますので、ご検討の際は是非ともお声掛けください。
Rubyのややこしい配列とハッシュとシンボルについて整理してみた
...皆様、あけましておめでとうございます。
さて、2015年の初投稿は、私的に今最も熱いRubyネタで始めようかと思います。
まず基礎のおさらいとして、Rubyにおける配列には一次元配列の
arrayクラスオブジェクトと多次元配列(連想配列)であるhashクラスオブジェクトの二種類があります。それぞれの配列オブジェクトは定義する際に要素を囲い込むリテラル記号によって以下のように区別されています。array = ["A", "B", "C"] # 配列変数arrayを定義 hash1 = {:first => "A", :second => "B", :third => "C"} # ハッシュhash1を定義一次元配列である
arrayクラスオブジェクトは各要素値に数値添字が自動で割り振られるため、数値添字のインデックスにて各要素にアクセスができます。array = ["A", "B", "C"] puts array[0] # "A"が表示される一方
hashクラスオブジェクトはキー・バリュー型のオブジェクトなので、文字列型の添字(キー)で要素値にアクセスができます。hash2 = {"first" => "A", "second" => "B", "third" => "C"} puts hash2["first"] # "A"が表示されるさて、ここで一番最初の例で定義したhash1とhash2では、キーの指定の仕方が異なっていることに気づきましたでしょうか? hash1とhash2は要素値こそ一緒ですが、キーが異なるため同じハッシュではありません。
puts hash1 == hash2 # falseになりますhash1は ハッシュキーがシンボルになっているハッシュで、hash2は文字列をキーとするハッシュであるため、それぞれ異なるハッシュとなります。なお、ハッシュのキーはシンボルであろうが文字列であろうがハッシュ内でユニークである必要があります。また、文字列キーとシンボルを同名で混在させた場合、それぞれの要素が別のものとして扱われます。
AWS SDK for Rubyを使ってEC2インスタンスのステータスを確認する
...アプリケーション側で、任意のAWSのEC2インスタンスについて、現在の稼働状況をリアルタイムに確認したい時がある。例えば外部アプリケーションからEC2インスタンスを起動させたり、停止させたりする場合などに、インスタンスの稼動状況を確認してステータスが変わったら次のプロセスを実行したいとかいうケースが、それに当てはまる。
SDK for Rubyでは、
AWS::EC2クラスのclient.describe_instance_statusメソッドで特定のECインスタンスのステータスを取得することができる。インスタンスのステータスにはsystem_statusとinstance_statusの2種類があって、正確な稼動状態を確認したい場合はこの2つのステータスを取得する必要がある。 そして、注意しないといけないのが、インスタンスが停止している時はステータスが存在していないということだ。つまり、停止しているインスタンスに対してclient.describe_instance_statusメソッドを実行した場合、ステータス情報が格納されているinstance_status_setオブジェクトの中身が取得できないので、それを踏まえてコーディングしないと、ステータス取得エラーとなってしまう。 例えば、停止状態のインスタンスを起動した場合のステータスを監視する時など、最初はインスタンスが停止しているので、instance_status_setオブジェクト内にステータスがないということをあらかじめ想定して処理を作る必要がある。 また、ターミネートされたインスタンスはclient.describe_instance_statusメソッドを実行する対象自体がないことので、こちらも注意する必要がある。さて、上記もろもろを踏まえてEC2インスタンスのステータス確認するRubyプログラムを作ってみた。
chkins.rb
# encoding: utf-8 require "aws-sdk" def check_instance_status ec2 = AWS::EC2.new( :access_key_id => Params[:access_key_id], :secret_access_key => Params[:secret_access_key], :region => Params[:region] ) AWS.memoize do status = [] if ec2.instances[Params[:instance_id]].exists? ec2info = ec2.client.describe_instance_status({ 'instance_ids' => [Params[:instance_id]] }) if ec2info.instance_status_set.empty? # instance has stopped status << 'stopped' message = '%s has stopped' else ec2info.instance_status_set.map { |i| sys_status = i.respond_to?(:system_status) ? i.system_status.details[0].status : nil ins_status = i.respond_to?(:instance_status) ? i.instance_status.details[0].status : nil status << sys_status << ins_status } if status.include?('passed') # instance is running message = '%s is running' elsif status.include?('initializing') # instance is initializing message = '%s is starting' else # otherwise message = '%s is unknown status' end end else # instance has terminated status << 'terminated' message = '%s has already terminated' end puts sprintf("#{message}. status: %s", "Instance: #{Params[:instance_id]}", status) end end begin # init Params = { :access_key_id => ARGV[0], :secret_access_key => ARGV[1], :region => ARGV[2], :instance_id => ARGV[3], :timeout => ARGV[4].nil? ? 1 : ARGV[4].to_i } raise 'Parameter is missing.' if Params.values.include?(nil) for i in 1..Params[:timeout] do sleep 1 if i > 1 check_instance_status end rescue => e puts e endプログラム実行時の引数として、
Mac どこでもターミナル
...最近ubuntuからmacに乗り換えました。 これでiPhoneアプリ開発し放題だぜ!(ウソ
しかし同じunix由来のOSとはいえ、異なる点もちらほら。 一番気になるのが、基本いちアプリ、いちウィンドウである点。
たくさん仮想デスクトップを生成してあっちこっちでターミナルを立ち上げたい派の私としては、この仕様がイマイチなじまないのです。 まあ仮想デスクトップ使いまくり、ターミナル立ち上げまくりなのはubuntuerの悪いクセだとは思いますが。
複数のターミナル立ち上げようと思ったら 1.spotlightでterminal.appを呼び出す。 2.⌘ + N で新しいターミナルを表示 3.表示されたターミナルを目的の仮想デスクトップまでドラック
だるぃ….
ggってみると、スクリプトをアプリケーション化する方法があるみたいなので作ってみました。
https://blog.colorkrew.com/uploads/T.zip
zipを展開してApplicationsに放り込めば使用可能です。
▪️使用方法 1. spotlightでT.appと入力(t.で補完されるはず) 2. 今いる仮想デスクトップでターミナル起動!
やってることは
open -n /Applications/Utilities/Terminal.appだけです。 では良いターミナルライフを!
▪️参考 技術/MacOSX/シェルスクリプトを".app"(“Bundle”)化する http://www.glamenv-septzen.net/view/1201
MySQL5.5以降 sjis環境でDATETIMEにindexが効かず遅い
...MySQLを5.6にバージョンアップした際に、一部のクエリがやたら遅くなってしまい困りました。 散々ggった結果、ヒットした情報が以下。
character_set_connection = sjis でDATETIME型のカラムにインデックスがきかないはなし
http://bugs.mysql.com/bug.php?id=74449
なんと、character_set_connection = sjis の場合に限ってDATETIME型,DATE型カラムに誤った型変換が行われるらしい。 sjisなんてやめなはれ、は正論ですが、残念ながらsjisを捨てられるシステムではないので、以下のようにCASTで対処。
date型の場合
AND dl.date >= '2014-08-10' ↓ AND dl.date >= cast('2014-08-10' as date)datetime型の場合
AND dl.date >= '2014-08-10' ↓ AND dl.date >= cast('2014-08-10' as datetime)ご参考まで。


