AngularUI Calendar (FullCalendar) dayClick not work expectedly on iOS
...bowerで入れた angularUI Calendar 1.0.0, FullCalendar 2.1.1での話です。
Angular WEBアプリでカレンダーを使いたいというニーズを完璧なまでに満たす AngularUI Calendar http://angular-ui.github.io/ui-calendar/
ですが、月(month)表示から日セルクリックで日(agendaDay)表示に切り替えようとしてdayClickを使用した場合、なぜかiPhoneではうまく動作しません。
正確にいえば、タップではなく一秒ほど長押しするか、軽く日セルをドラッグしようとするとdayClickが呼ばれます。
なんでどぅあぁぁぁーーーー!
と3日ほど頭を悩ませた結果、なんとか対処できたのでおすそ分けします。 ちなみにAngularUI CalendarはFullCalendarのラッパーなので、FullCalendarで同じような問題に悩んでいる方にも効くはず….です。
原因
dragイベントの扱いの違いに起因しています。 dayClickはclickイベントで呼ばれていません。dragの終了を検知して呼ばれています。 iOS上のSafari(というかwebkit?)以外では、タップして指を離した瞬間に drag開始、drag終了のイベントが発生するのですが、iOSではdragするか、しばしタップし続けないとdrag終了イベントが発生しないためのようです。
どうにもならんのでタップイベントでdayClickを呼ぶようFullCalendar.jsを修正しました。
4038行目付近
coordMap: null, // a GridCoordMap that converts pixel values to datetimes cellDuration: null, // a cell's duration. subclasses must assign this ASAP isTouch : false, // separate touch and scroll. // Renders the grid into the `el` element.4093行目付近
mysql5.6レプリケーションでold_passwordが拒否される
...こんにちは。小宮です。
同僚の湯尾さんから教えてもらった情報を貼っておきます。
【mysql5.6レプリケーション仕様が変わった話】
某環境で mysql5.5でフルdumpしたSQLを5.6に流し込む作業を行い、その後差分データを5.5→5.6にレプリケーションしようとしたところ レプリケーションが出来なかったという症状がありました。
その後、mysql5.6の設定見直しのため
stop slaveしてmysqlをrestartしレプリケーション貼り直しと試みましたが 今度は5.6環境同士でもレプリケーションが貼れなくなりました。原因はmysql5.6から
secure_authの仕様が変更されたためクライアント([mysql]以下の記述)設定でskip-secure-authが設定されていても レプリケーションIOの時点でold_password(16桁パスワード)が拒否されるためレプリケーション自体開始できないとのことです。 ステータス(show slave status\G)では下記の様になります。------------------------------- ・・・ Slave_IO_Running: Connecting Slave_SQL_Running: Yes ・・・ Last_IO_Errno: 2049 Last_IO_Error: error connecting to master 'repl@172.17.xx.xx:3306' - retry-time: 60 retries: 1 Last_SQL_Errno: 0 Last_SQL_Error: ・・・ -------------------------------解決策として、お客様の許可を得て、mysql5.5、5.6環境の両方に新たにセキュアなレプリケーション用アカウントを作成して、それでレプリケーション貼りました。 セキュア(
old_passwordではない)なパスの作り方は下記の通り。------------------------------- set session old_passwords = 0; GRANT REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'newrepuser'@'172.17.xxx.%' IDENTIFIED BY 'xxxxxxxxxxxxxx'; -------------------------------mysql5.6にデータ移設したいなど相談を受けた場合は、パスワードの桁数にご注意下さい。という話です。
zabbixのグラフで日本語が文字化けを直す
...おはようございます。インフラ宮下です。
zabbixのグラフ設定は標準では日本語が表示されません。 ※アイテム名に日本語を使っている場合です。
動作環境はこんな感じです。
OS:CentOS release 6.5 (Final) バージョン:zabbix-server-2.2.3
「監視データ」→「グラフ」で作成したグラフを見てみると下記のように日本語の部分が□になってしまいます。 これはアイテムに日本語を使っていて画像変換時にフォントがないのが原因です。

まずはフォントがおかれている場所を確認します。
# ls /usr/share/zabbix/fonts/ graphfont.ttf次にOSに搭載されているフォントを確認します。
$ ls /usr/share/fonts/ dejavu ipa-gothic ipa-mincho ipa-pgothic ipa-pmincho vlgothicIPAを使います。ただシンボリックリンクを張るだけでOKです。 特にzabbix-serverの再起動も必要ないです。
# ln -s /usr/share/fonts/ipa-pgothic/ipagp.ttf /usr/share/zabbix/fonts/ipagp.ttf # vi /usr/share/zabbix/include/defines.inc.php (変更箇所) 7 39c39 < define('ZBX_GRAPH_FONT_NAME', 'ipagp'); // font file name --- > define('ZBX_GRAPH_FONT_NAME', 'graphfont'); // font file name 86c86 < define('ZBX_FONT_NAME', 'ipagp'); --- > define('ZBX_FONT_NAME', 'graphfont');
Chef-Soloから卒業、chefのlocalmodeをつかってみた
...こんにちは。小宮です。
事の経緯
お急ぎの場合は飛ばして大丈夫です。 Chef-Soloがdeprecated(非推奨)とかで開発元からchef-zero(localmode)をつかうよう周知されたのが半年くらい前でしょうか。 当時はどうしたらええんやと色々比較してみたりしたあげく時が経ってとうとう検証することに。 数年で入れ替わるのではなく長く続くことが前提だとコストをかけても技術的負債を残したくない事情があるケースもあるようで。 個人的には正直コストをかけて移行するかどうかは微妙なところで、soloがすぐ無くなるみたいな話ではない気がしてます。 世の中的にはcookpadさんからitamaeとか出てたりAnsibleが流行ったりなど。 Ansibleはnot_ifに相当する機能を持たせようとするとドライランできなくなるみたいなのが致命的らしいと聞いたけど、 そもそもYAMLに書きなおすコストがあり得ないので試してないです。 itamaeも気になってたんですがroleとenvironmentをattributeになおす手間がありそうでした。 roleもenvironment数もそれなりの規模で配列attributeを優先順位で意図的にdeepmergeしたり初期化するようなことをしてるし その修正はだいぶヘビーな気が。あとdata_bags機能がないのも超困る。他に移行するにはchefの沼にだいぶつかりこんでいたようです。。 あとChef-Serverはコミュニティ版はHA機能がNGだときいたりしました。
現実的にはlocalmodeだろうということでそんな感じでいつもどおり右往左往で検証してみましたので備忘録です。
chefって情報は結構あるんだけどモヒカンの人(技術レベルの高すぎる人)ばっかりなため初心者がどこで惑うか想像つかないのか肝心なところが分かりづらくて 結局念入りにヘルプを眺めたりググりまくって試しまくるなどというのが多いような。。 使い方も多くてそれぞれの環境が違って色々まざると発狂ちょっとこんがらがりやすいかもしれません。
後日、分かりやすい素敵なチャートをみかけたので追記しておきます。 あなたに合ったChefはどれ? 〜 おすすめ構成確認チャート #getchef - クリエーションライン株式会社
普及と発展には分かりやすさというのはとても重要かなと思います。こんな感じのやってみた記事が多少それに寄与するといいなーと思います。
参考情報
まあ色々みてみたんで参考情報からご紹介いたしましょう。パターン分けておきます。 Chef-Zeroの仕組みとか機能とかの話は別途ググっていただくと分かりやすいと思うんですが、、 インメモリChef-Serverとローカルモードの違いがありまして、私がやりたいのはローカルモードのほうです。 インメモリChef-Serverとして使う場合は Chef-Zeroを起動してcookbookとroleとenvironmentとdata_bagsのデータなんかをknifeコマンドで登録しておく必要があるようです。 インメモリなので、Chef-Zeroを停止すると登録したデータは消えます。 なので手間を考えるとChef-Serverへの移行を見据えて1次的にとかchef-shellでとれる情報をみたい時に使うという用途になるのかなーと思いました。 ブラウザからアクセスすると登録したjson情報などが見えるのはまあ便利と言えば便利かもしれないけどgitでみればいいやんというレベルだったかなあ。 ローカルモードとして使う場合は、コマンド実行時だけChef-Zeroが内部的に起動してレシピ適用終わったら落ちるようで、 knife.rbに書いといたChef-Repoのパスを勝手に見てくれて余計な手間はなさそうでした。
・Chef-ZeroをインメモリChef-Serverとして動かしたいタイプ Amazon Linuxで簡易Chef Server(chef-zero)を動かしてみた | Developers.IO CentOSにchef-zeroのインストール - clavierの日記 chef-zero を構築して knife-xenserver と連携してみた一部始終 - ようへいの日々精進 XP Ruby - knife zero bootstrap で リモートに chef がインストールできない - Qiita 軽量簡易Chef Server「chef-zero」を使ってみよう #opschef_ja « CREATIONLINE, INC. 【#Docker】Chef Zero を軽量インメモリ Chef Server として使い、ホスト OS から Docker コンテナを Chef で管理する #Chef #GetChef_ja - Qiita
gitlabの導入方法のメモ
...こんにちは。小宮です。先輩から要望されていそうな気がしたのでgitlab導入時のメモです。。
やたらめったら長いし手順が複雑でこのとおりやって再現できるかはお使いの環境に依存する可能性があり保障できかねます。 この手順で再現した環境はOSはCentOS6.5でした。 postgresを許容できるのであれば自動的に入れられるオムニバス版があるのでそちらをお使いいただくのがよろしいかと。 個人的にpostgresの運用の知見が心もとなかったのと、RDSに逃げられなくなるのがアレだったのでmysqlで頑張りました。
自分で自動化する時は、passengerとgitlab:setup時の対話処理をなんとか自動化するオプションを付けるとこがキモかと思いました。 この手順自体は部分的にchefがでてきますがほぼ手動です。自動化オプションは最後のほうにちょろっと書いときます。
1.このへんからmysqlをなんとかして入れとく
$ wget http://ftp.jaist.ac.jp/pub/mysql/Downloads/MySQL-5.6/MySQL-5.6.17-1.linux_glibc2.5.x86_64.rpm-bundle.tar -P site-cookbooks/mysqld/files/default/usr/local/src/2.rbenv等でrubyをなんとかして入れておく
(chefでなにもせずにやるとchefgemに寄るので注意がひつよう) rubyのバージョンが低いとGemfileのシンタックスチェックでエラー出てmysql2とかが入らないことも。
3.Gitのインストール
# yum -y install libcurl-devel libxslt-devel libxml2-devel expat-devel gettext openssl-devel zlib-devel Installed: libcurl-devel.x86_64 0:7.19.7-37.el6_4 libxml2-devel.x86_64 0:2.7.6-14.el6 libxslt-devel.x86_64 0:1.1.26-2.el6_3.1 Dependency Installed: libgcrypt-devel.x86_64 0:1.4.5-11.el6_4 libgpg-error-devel.x86_64 0:1.7-4.el6 # su - chef;cd infra-chef-repo/ $ knife cookbook create git -o site-cookbooks $ knife cookbook create redis -o site-cookbooks $ vi site-cookbooks/git/recipes/default.rb # # Cookbook Name:: git # Recipe:: default # # Copyright 2014, YOUR_COMPANY_NAME # # All rights reserved - Do Not Redistribute # %W{libcurl-devel libxslt-devel libxml2-devel expat-devel gettext openssl-devel zlib-devel libgcrypt-devel libgpg-error-devel}.each do |pkg| package pkg do not_if "rpm -qa|grep #{pkg}" action :install end end bash "bash-install-git" do not_if "ls -d /usr/local/src/git-1.9.0" code <<-EOC wget https://git-core.googlecode.com/files/git-1.9.0.tar.gz -P /usr/local/src cd /usr/local/src/ tar zxf git-1.9.0.tar.gz cd /usr/local/src/git-1.9.0 ./configure --prefix=/usr/local/git make all make install ln -sf /usr/local/git/bin/git* /usr/local/bin/ EOC end $ knife solo cook localhost -o git # wget https://git-core.googlecode.com/files/git-1.9.0.tar.gz -P /usr/local/src # cd /usr/local/src/ # tar zxf git-1.9.0.tar.gz # cd /usr/local/src/git-1.9.0 # ./configure --prefix=/usr/local/git # make all # make install # ln -s /usr/local/git/bin/git* /usr/local/bin/ # which git /usr/local/bin/git # git --version git version 1.9.04.redisのインストール
# yum install -y --enablerepo=remi redis Installed: redis.x86_64 0:2.8.9-1.el6.remi Dependency Installed: gperftools-libs.x86_64 0:2.0-11.el6.3 libunwind.x86_64 0:1.1-2.el6 # /etc/init.d/redis start # chkconfig redis on # redis-cli ping PONG $ vi site-cookbooks/redis/recipes/default.rb bash "yum-install-redis-from-remi" do not_if "which redis-cli" code <<-EOC yum install -y --enablerepo=remi redis EOC end service "redis" do supports :status => true, :restart => true action [ :enable, :start ] end $ knife cookbook test redis $ knife solo cook localhost -o redis5.ユーザ作成
# useradd -c 'GitLab' git # chmod 755 /home/git # su - git -s /bin/bash $ mkdir .ssh $ touch .ssh/authorized_keys $ chmod 600 .ssh/authorized_keys $ chmod 700 .ssh $ git config --global user.name "GitLab" $ git config --global user.email "gitlab@localhost" ##### 6.gitlab-shellのインストール $ git clone https://github.com/gitlabhq/gitlab-shell.git -b v1.9.4 $ cp -a /home/git/gitlab-shell/config.yml{.example,} $ /home/git/gitlab-shell/bin/install install失敗する場合は、gitユーザの.bashrcか/etc/profile.d/の下あたりに環境変数を追加し読み込みしてから再実行 export PATH=/path-to-ruby:$PATH8.gitlabインストール
$ git clone https://gitlab.com/gitlab-org/gitlab-ce.git -b 6-8-stable gitlab $ cp -a /home/git/gitlab/config/gitlab.yml{.example,} 不要っぽい -------------------------- $ chmod -R u+rwX /home/git/gitlab/log/ $ chmod -R u+rwX /home/git/gitlab/tmp/ $ mkdir /home/git/gitlab/tmp/pids/ $ mkdir /home/git/gitlab/tmp/sockets/ $ chmod -R u+rwX /home/git/gitlab/tmp/pids/ $ chmod -R u+rwX /home/git/gitlab/tmp/sockets/ $ mkdir /home/git/gitlab/public/uploads $ chmod -R u+rwX /home/git/gitlab/public/uploads -------------------------- $ mkdir /home/git/gitlab-satellites $ ll -d /home/git/gitlab-satellites drwxrwxr-x 2 git git 4096 5月 19 12:20 2014 /home/git/gitlab-satellites $ $ ll -d /home/git/gitlab-satellites drwxr-x--- 2 git git 4096 5月 19 12:20 2014 /home/git/gitlab-satellites $ cp -a /home/git/gitlab/config/unicorn.rb{.example,} $ cp -a /home/git/gitlab/config/initializers/rack_attack.rb{.example,} $ cd /home/git/gitlab $ git config --global user.name "GitLab" $ git config --global user.email "gitlab@localhost" $ git config --global core.autocrlf input9.DB設定
$ cp -a /home/git/gitlab/config/database.yml{.mysql,} $ vi /home/git/gitlab/config/database.yml $ diff /home/git/gitlab/config/database.yml{.mysql,} 10,12c10,12 < username: git < password: "secure password" < # host: localhost --- > username: gitxxxxx > password: "xxxxxxxx" > host: localhost $ ls -al /home/git/gitlab/config/database.yml -rw-rw-r-- 1 git git 777 5月 19 12:32 2014 /home/git/gitlab/config/database.yml $ chmod o-rwx /home/git/gitlab/config/database.yml $ ls -al /home/git/gitlab/config/database.yml -rw-rw---- 1 git git 777 5月 19 12:32 2014 /home/git/gitlab/config/database.yml $ vi /home/git/gitlab/config/gitlab.yml $ diff /home/git/gitlab/config/gitlab.yml{,.example} 227c227 < bin_path: /usr/local/bin/git --- > bin_path: /usr/bin/gitローカル等てきとうなところ(database.ymlに指定したところ)にDBをなんとかしていれる
GulpでCSS/JavaScriptコンパイル環境を構築する ─ CentOS編
...従来、WEBフロントエンドの主要アセットであるCSSとJavaScriptはソースレベルでなかなか管理しづらく、すぐにカオスな領域に突入して保守しづらくなっていました。そのカオスな領域にあるCSSやJavaScriptをソースレベルでもっと保守管理しやすいように生み出されたのがGruntやGulpというコンパイルビルドの仕組みです。今の世の流れ的に、フロントエンド開発ではSCSS(SASS、LESS等)、CoffeeScriptなどでCSSやJavaScriptのコーディングを効率化しつつ、同時にソースの保守管理をし易くするという開発手法がデフォルトになってきました。 実際にLESSで変数を使ったCSSスタイリングや、コード量が劇的に少ないCoffeeScriptでJavaScriptを書いてみると、圧倒的なコード生産性の高さに、もはや今までのベタなフロントエンドコーディング手法は改めざるを得ないという境地になります。 ──と云うことで、早速CSS/JavaScriptのコンパイルビルドを行う環境をサービス提供用のCentOSサーバに作ってみようかと思います(ローカル開発環境としてのWindowsマシンへの導入はこちらの記事を参照)。
ちなみに、Gulpは「ガルプ」と読みます。私は最初「グループ」とか読んでました…(笑)
Node.js のインストール
まずはGulpはnode.jsのモジュールなので、node.jsをインストールしないことには始まりません。そんな訳で、node.jsをインストールするのですが、まずはnode.jsやライブラリのバージョン管理モジュールであるnvmからインストールしていきます。 下記のように、nvmをGitHubからクローンして同梱のシェルでインストールします。
$ git clone git://github.com/creationix/nvm.git ~/.nvm $ . ~/.nvm/nvm.sh次に、node.jsをインストールするのですが、その前に現在のnode.jsの安定バージョンを Node.jsの公式サイト を確認しましょう。TOPページの真ん中あたりに「Current Version: v0.12.2」というように記載されているので、そのバージョンをインストールするのが無難です(2015年4月7日時点のNode.jsの安定バージョンは0.12.2でした)。 インストールバージョンが決定したら、nvmでインストールします。
$ nvm install v0.12.2 $ node -v v0.12.2バージョン確認してインストールバージョンが表示されればOKです。 最後に、自分のコンソール環境でnode.jsが利用できるように .bashrc に以下の記述を追記しておきます。
$ vim .bashrc $ cat .bashrc # .bashrc # Source global definitions if [ -f /etc/bashrc ]; then . /etc/bashrc fi # User specific aliases and functions . ~/.nvm/nvm.sh nvm use v0.12.2 export NODE_PATH=${NVM_PATH}_modulesついでにバンドルでインストールされたnpmのバージョンも確認してみます。
GulpでCSS/JavaScriptコンパイル環境を構築する ─ Windows編
...いまさら感が強いんですが、世の流れ的に、フロントエンド開発ではSCSS(SASS、LESS等)、CoffeeScriptなどでCSSやJavaScriptのコーディングを効率化しつつ、同時にソースの保守管理をし易くするという開発手法がデフォルトになってきました。私はその辺の技術の取り込みがおっくうで、ついついCSSやJavaScriptを素でコーディングしてしまったりしていたのですが、最近やっている Ruby on Rails の開発でCoffeeScriptでJavaScript書いてみて、圧倒的なコード生産性の高さに、もはや今までのベタなフロントエンドコーディング手法は改めざるを得ないという境地に達しました(いやはや、ようやくですねぇ…)。 ──と云うことで、早速CSS/JavaScriptのコンパイルビルドを行う環境を業務マシンであるWindowsマシンに作ってみようかと思います(WEBサービス側のCentOS(Linux)環境への導入はこちらの記事を参照)。
なお、なぜビルドツールをGruntではなくGulpにしたかというと、今どきのトレンドはGulpの方かなぁ…という漠然な理由だったりするんですが、まぁ、Gruntより設定ファイルが記述しやすく、複数リソースの設定があっても設定が煩雑化しないというメリットもあるからです。
Node.js のインストール
まずはGulpはnode.jsのモジュールなので、node.jsをインストールしないことには始まりません。そんな訳で、node.jsをインストールします。 インストールは簡単で、Node.jsの公式サイトからインストーラーをダウンロードするだけです。私の業務用マシンは「Windows7(64bit版)」だったので、
node-v0.12.0-x64.msiというファイルが対象になります(2015年3月4日時点のNode.jsのバージョンは0.12.0です)。 インストーラがダウンロードできたら、早速起動させます。いくつか対話が発生しますが、特に注意しないといけないようなインストール設定はありません。 イントールが完了したら、コマンドプロンプト(もしくは、パワーシェル)から、Node.jsのバージョンを確認してみます。> node -v v0.12.0ついでにバンドルでインストールされているnpmのバージョンも確認してみます。
> npm -v 2.5.1これでNode.jsのインストールは完了です。
Gulp のインストール
次にGulpをグローバルにインストールします。
> npm install -g gulp > glup -v [**:**:**] CLI version 3.8.11これでインストール完了です。もしインストールに失敗するようなら、
> npm install -g gulp --mscs_version=2012──とオプションを付けてみると上手くいくかもしれません。 次に、ローカルにインストールします。 ローカルにインストールするにあたっては、npmの初期化を行う必要があります。まず任意にgulpを実行したいディレクトリを作成します。この記事では、
C:\npm\node_modules\gulpというディレクトリを新たに作成しています。> mkdir -p C:\npm\node_modules\gulp > cd C:\npm\node_modules\gulp > npm init This utility will walk you through creating a package.json file. It only covers the most common items, and tries to guess sane defaults See `npm help json` for definitive documentation on these fields and exactly what they do. Use `npm install --save` afterwards to install a package and save it as a dependency in the package.json file. Press ^C at any time to quit. name: (gulp) gulp_build version: (1.0.0) description: Gulp-build-test entry point: (index.js) test command: git repository: keywords: gulp author: maeno license: (ISC) MIT About to write to C:\npm\node_modules\gulp\package.json: { "name": "gulp_build", "version": "1.0.0", "description": "Gulp-build-test", "main": "index.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "keywords": [ "gulp" ], "author": "maeno", "license": "MIT" } Is this ok? (yes) yes対話式にいくつか属性値を聞かれるので、任意に入力します(すべてEnterでも可です)。 初期化ができたら、早速ローカルにgulpをインストールします。
運用的グラフを診る(DNS編)
...おはようございます。インフラ宮下です。
ビックデータ時代様々なデータやグラフがあふれかえってます。 そんなグラフに関するお話です。
はじめに
インフラ運用で使う実際のグラフを使って、どのような事が起きていてどんな対処が必要になるのかを見ていきたいと思います。
使うグラフ
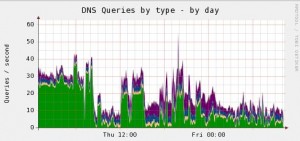
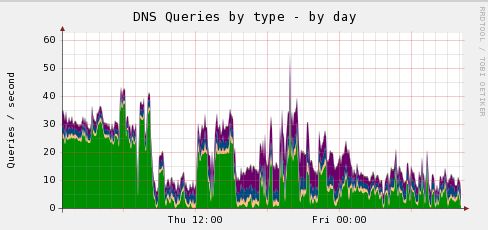
muninでbindのクエリ統計をとったグラフです。 OSはCentOS release 5.9になります。
問題点
グラフの色はクエリタイプ毎に分類されているのですが、AM8時前までで一番多いのはANYレコードです。 これは「DNS AMP攻撃」が行われた形跡です。
ISPにおけるDoS/DDoS攻撃の検知・対策技術 DNS Amp攻撃の解説と、踏み台にされないためのBIND DNSの設定
対応策
今回は意図的に対策していないBindを利用している為、攻撃にさらされてしまいました。 DNS AMP攻撃がひどいのが、勝手にトラフィックを使って他人を攻撃してしまっているので本人に悪気が無くても加害者になってしまいます。 対策は既に出回っていますが、bindバージョンアップして再帰的問い合わせを実施しないか、クエリを受け付けるNWを制限するというのが一般的です。 あとはCentOS6系であればiptablesで特定ドメインのクエリを止める事が出来ます。 (出来るのはCentOS6以上)
NSサーバへのANY? . な連続リクエスト対応 DNSアタックとiptablesフィルタ
実際のANYリクエストで多いのは「isc.org」だと思います。どちらかと言うと長期間にわたってじんわりと来る感じ。 その他では「uspsoig.gov」や「defcon.org」「doleta.gov」が最近良く目にします。
先程のiptablesでブロックする方法は、 DNS Amplification Attacks Observer など情報は出回っていますのでサービスに影響が出ない範囲で実施してみてください。
注意しなければいけない点としては、qmailがメール送受信時の名前解決にANYレコードを引いてくるので何でもかんでもANYははじいてしまうとメール障害となってしまいます。 qmailとDNSSEC <a http://mediakisslab.net/doku.php?id=linux:qmail:memo" target="_blank">DNSSEC対応
さいごに
昔は自前でDNSサーバをたてて、そのまま放置して今も稼働しているなんて言うケースはどこでもあると思います。 (むしろ外部サービスとかで使われているDNSはきちんと担当の方がいて健全に運用している気がします) グレイな環境で手が出ないオープンリゾルバなDNSは怖いですな。 (昔はメールの不正中継の方が花形だったのに…)
chefのruby_blockを用いて環境変数を再読み込み
...こんにちは。小宮です。
chefでいろいろ自動化していくうちに、途中で変更された値というか変数を使いたい場合が出てくるのかなと思います。 1回目は上手くいかないけど2回目は上手くいくというような冪等にならない怪現象を解決したいと思う時がそのうちきます。 そんなとき、、 ohaiで値がとれる場合はそれを使いなければohaiのプラグインを自作するか、 ruby_blockを書いたり、notifiesで:immediatelyとかつけて呼び出すって感じの対応が必要になったりします。。
何言ってっかわかんねえ!と思うかたは以下のリンク先にchefの実行順序に関して書かれているので見てみるといい気がします。 Chefのレシピは上から下に実行されるという誤解 | Engine Yard Blog JP
これだけだと不親切かもしれないので以下ご参考まで。
template "/etc/profile.d/rbenv.sh" do not_if "grep rbenv /etc/profile.d/rbenv.sh" source "rbenv.sh.erb" action :create notifies :create, "ruby_block[initialize_rbenv]", :immediately end ruby_block "initialize_rbenv" do block do ENV['RBENV_ROOT'] = node[:rbenv][:root] ENV['PATH'] = "#{node[:rbenv][:root]}/bin:#{node[:rbenv][:root]}/shims:#{node[:ruby_build][:bin_path]}:#{ENV['PATH']}" end action :nothing end少し解説しますと、 chefではレシピ中での改変を前提とした処理はくふうがひつようで、 rubyで書かれた処理はconvergeの手前で行われてしまってその時点では途中の改変を認識できないようです。(だから2回目に成功する) ruby_blockリソースはconvergeのタイミングと同じ時に動くようです。 特定のリソースの処理が行われるときだけ実行したい場合にはそのリソースのnotifiesにはタイミングを指定できます。(:immediatelyとか:delayedとかあるらしい) この場合、ruby_blockリソースのactionにはnothingを指定しておき、templateリソースでprofileの設定を置いて:immediatelyをnotifiesに指定することで ただちに変数の再読み込みが実行される、という話になります。(レシピを分けてる場合にnotifiesつかうと-oで個別実行しにくくはなりそう。)
AWSのSecurityGroup関連の調査・更新CLIメモ
...こんにちは。小宮です。
今回ご紹介するのはpiculetでgroupファイルでルール更新というのではありません。 ちょっと整理とか削除とかしたいけど手でポチぽちするには量が多いしオペミスが心配だし手間だし早く帰りたいので どれに紐づいてるのか一括で調べたい一括更新したいといった時にforループとCLIでなんとかする方法です。 SecurityGroupの上限緩和申請の際にSGの書き方的に通信パフォーマンスがアレで引っ掛かった時等にこんなような作業が必要に。
あんまり使いこなせてるほうでもないのですが、一応載せておきます。ご利用は自己責任でお願いします。 みなさま似たようなことしててもっと洗練されたやり方をご存知の方も沢山いそうです。 弊社だと稲田さんほか協力部隊の方々がもっと詳しそうな気がします。マサカリ歓迎いたします。 稲田さんに聞いたらもっとoutputはtextにしてjoinを使いこなせと言っていたのでそのうち何か書いてくれると思います。
SecurityGroupのidから紐づくインスタンス情報を得る
これは既存の情報を得るだけで更新しないので気軽に実行できると思います。 まずリストを作る(消したいSGをいれる)
vi listfile sg-xxxxxxxx,SG_hoge_dev1 sg-yyyyyyyy,SG_fuga_dev2 ... list=listfile profile=xxxxリストを読み込んでdescribe-instancesを実行
for i in `cat $list|grep -v elb` do groupid=`echo $i |awk -F, '{print $1}'` groupname=`echo $i |awk -F, '{print $2}'` echo $i aws ec2 describe-instances --profile ${profile} --filters Name=instance.group-id,Values=$groupid --output text \ --query 'Reservations[].Instances[*].[InstanceId,PrivateIpAddress,Tags[?Key==`Name`].Value[]]' --output json \ |sed -e '/\]/d' -e '/\[/d' -e '/^$/d' -e 's/ //g'|perl -pe 's/,[ ]*\n/,/g'|sort -t , -k 3 echo "" done出てきた結果からlistfileをつくりSGはずしたり替えたりするときにつかいます。
solarisのKSSLをつかう
...おはようございます。インフラ宮下です。
最近はopensslの脆弱性が頻繁に取りざたされています。 そこで今回はKSSLを使ってSSLをterminateする設定を紹介します。
1.環境
サーバ:oracle spark enterprise T2000 OS:solaris10
とても古い環境です。
構成:コンテナ構成でWEBサーバはlocal ZONEに構築されています。 KSSLで終端するのはglobal ZONEです。 local ZONEのWEBサーバでは、8888ポートでListenするように設定しています。
2.証明書の準備
KSSLで渡せる証明書情報は1ファイルだけなので、「証明書+中間証明書+秘密鍵」の順番で情報を貼り付けたファイルをGlobal ZONEから見れる場所に設置する。
[shell]# vi /etc/httpd/keys/abc.net.key [/shell]
3.SMFにKSSLサービスを登録する
[shell]ksslcfg create -f pem -i /etc/httpd/keys/abc.net.key -x 8888 zone-web01 443 [/shell]
「zone-web01」はforward先のサーバを差します。(今回はlocal ZONEのWEBサーバ) この名前は、DNSで引けるかhostsに登録してある必要があります。 「-i」…設置した証明書を指定する。経験的にファイルの権限とかに制約はない 「-x」…配下のサーバと通信ポート番号。webサーバがListenしているポートです 「zone-web01」…terminate後の接続先サーバ名 「443」…KSSL自体が待ち受けるポート
[shell]# svcs -a|grep ssl online 10:15:01 svc:/network/ssl/proxy:kssl-zone-web01-443 [/shell] Global Zoneでこのように「online」となれば起動成功です。
opsだけどgitを使ってみた~その2
...こんにちは。小宮です。 前回のつづきです。今回はgitマージとタグとコンフリクトの話を書きます。 まあ初心者が慣れてきた頃の様子ということで生温かく見守ってください。 git-flowやブランチモデルがどうという話はでてきません。
git branch でブランチを切る
現在居る場所を確認する
$ git branch -a add_custom_repository * masteraddしただけのやつがないのを確認します。
$ git status # On branch master # Changed but not updated: # (use "git add <file>..." to update what will be committed) # (use "git checkout -- <file>..." to discard changes in working directory) # # modified: .gitignore # no changes added to commit (use "git add" and/or "git commit -a")※万が一addしただけのやつがある場合、commitするかstashするかする必要があります。
source treeを使ってgitlabを触ってみる(2)
...おはようございます。インフラ宮下です。
前回source treeのインストールと鍵の登録までを説明しましたので、今回はgitlabとの接続について説明します。 社内にgitlabがあるのでgitlabとの接続が前提となります。 (もちろんgitlabのアカウントもある想定)
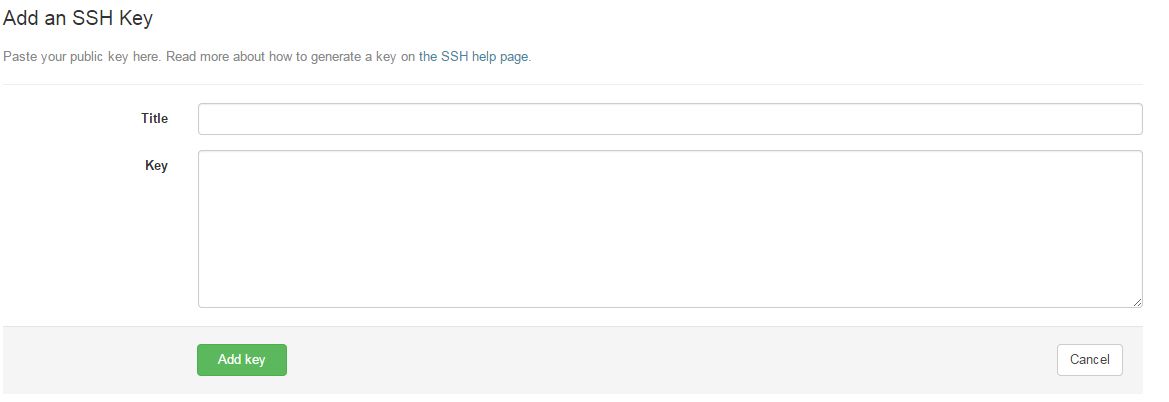
gitlabの自分profile画面のメニューで「SSH keys」を選択します。
既に登録されている鍵の一覧が確認できます。右上にある「Add SSH key」をっクリックします。

鍵登録の画面に移ったら、Titleに識別し易い名前を(入力しないと自動生成されます)入れて、Keyの所に前回作成した公開鍵を貼り付けたら「Add key」で登録します。
登録keyの一覧に表示されたら無事登録は完了です。
再びsource treeに戻ります。
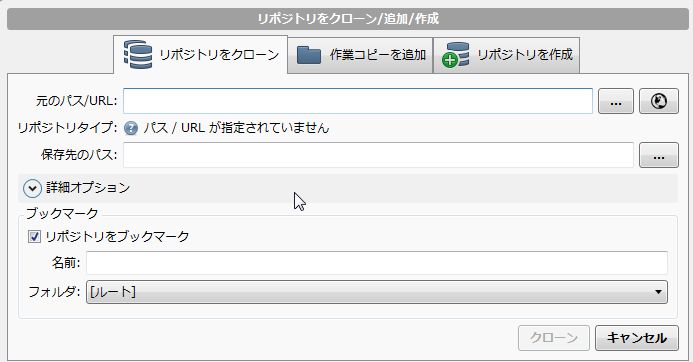
ではgitlabのリポジトリをcloneします。「新規/クローンを作成する」で開始します。
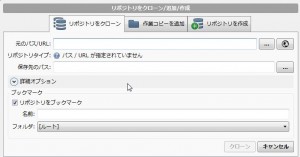
今回は、gitlabのリポジトリを使いますので、「リポジトリをクローン」タブを選択して、 ・元のパス/URLにgitlabの接続先情報を入れます。 (例:http://192.168.0.250/infra/projectX.git) 社内gitlabはhttpでの接続が出来ますが、gitであったりsshでも接続出来る方法なら何でも大丈夫です。 入力したら自動で接続確認が行われて接続成功・失敗が確認出来ます。 ・保存先のパスにクローンしたデータの保存先を指定します。 ・リポジトリをブックマークはそのまま選択状態にしておきます。 ・名前はsourcetree上で表示される名前なので、どのリポジトリかわかるような名前を付けておいてください。
必要事項を入力したら「クローン」でスタートです。
データ量によりますが、しばらく待つと保存先のパスにクローンが完了します。

無事登録されました。これでsourcetreeからgitライフが可能となります。
基本的な作業として、pushするまではこんな感じです。 PC側でファイルの修正をすると変更アイコンに変わりますので「追加」をクリックするかファイルの所をクリックします。

初心者向けGoogle Analyticsの基本的な使い方[第一回]
...こんにちは。フロントエンド担当の鴫原(シギハラ)です。
「Google Analytics導入したけど、どうやって解析したらいいかわからない!」という初心者の方向けに、全5回にわけてGoogle Analyticsの基本的な使い方についてお話をしたいと思います。今日は第1回目となります。
<目次>
Google Analyticsとは
Googleが提供している無料のアクセス解析ツールのことです。 「1日に何人くらいの人がうちのサイトに来ているか」「始めにどのページを見たのか」「どんな検索ワードでサイトに来ているか」など自身のwebサイトの現状を知ることで、強みや改善点を分析することができます。 何かしら目的のあるwebサイトには必ず導入したほうがいいツールです。
Google Analyticsの導入
1. Google Analyticsの導入手順
導入は以下の3STEPで簡単に登録することができます!
- Google Analyticsの公式サイト(http://www.google.com/intl/ja_ALL/analytics/index.html)にアクセスし、必要な情報を入力します。
- 登録後、コードが発行されるのでコピーをします。
- コピーしたコードをサイト内の全ページに貼り付けます。※設置場所はの直前(Google推奨)。

2. Google Analyticsの導入時に一緒に設定すべき3つのこと!
導入時に以下の3つも一緒に設定しておくと便利です。
- Googleウェブマスターツールと連携すること →通常Google Analyticsでは取得できないデータが取得できるようになります。
- 自分や関係者のアクセスを除外すること →関係者のアクセスを除外しないと真のデータが見れません!
- コードに「ga(‘require’, ‘displayfeatures’);」を追記すること →ユーザー属性(性別、年齢、興味)を取得できるようになります。
▼参考記事 ・必ず設定したい!Googleアナリティクスを導入したら最初に行うべき基本設定 http://creive.me/archives/5393/ ・最初に設定しないと絶対損する!Google Analytics 9個の必須設定&解説 http://www.find-job.net/startup/analytics-setting ・Google Analyticsでユーザーの分布レポートを有効化する手順 http://techmemo.biz/web-cheat-sheet/google-analytics-user-distribution/
まとめ
今回はGoogle Analyticsとは?からGoogle Analyticsの導入について説明をさせていただきました。 第2回からは基本的な使用方法や用語についてお話できればと思います。 最後までお付き合いいただきありがとうございました!