

Hi! My name is Ziyu Chen. I am a full-stack engineer at Colorkrew. I love learning and writing about data engineering.
Today, I would like to discuss transformations and actions in Spark. Of course, you can dive into the world of Spark and perform ETL processes without knowing how they differ from each other. However, once you are in charge of optimizing pre-existing ETL processes or building new ones from scratch, not understanding their differences might sabotage the efficiency of the ETL processes that you create. In the end, mediocrely-designed inefficient ETL processes might even increase the operation cost of your organization. Therefore, a thorough comprehension of the essence of transformations and actions becomes necessary if you want to build high-performance ETL processes using Spark.
Let’s start with a brief introduction to transformations and actions. Transformations are Spark operations that return DataFrames, Datasets, or RDDs, which merely represent the actual data. Since transformations only generate data representations, they require little computation resources. On the other hand, actions are Spark operations that load the data or store it in external storage. Actions involve extracting and loading the actual data, which makes them more compute-intensive than transformations. Therefore, it’s better to avoid using actions whenever possible.
Next, let’s look at some examples. Methods such as map(), filter(), and intersection() are transformations. Map transforms the rows in the original DataFrame and returns a new DataFrame with the same number of rows. Filter returns a new DataFrame containing rows that match the criteria. Intersection combines two DataFrames and returns a new DataFrame containing rows present in both source DataFrames. Despite the differences in their functionalities, they share the same return type: DataFrame.
As for actions, we have examples like count(), collect(), and write(). Count retrieves the number of rows in a DataFrame. Collect returns all the data in a DataFrame. Write saves the data represented by a DataFrame. Different as they are, they all involve retrieving the actual data, which makes them more time-consuming and compute-intensive than representations.
Transformations can be further divided into two category: narrow transformations and wide transformations. In narrow transformations, all the rows required to compute the rows in the same partition in the output data (represented by the output DataFrame) come from the same partition in the input data (represented by the input DataFrame). In other words, the records in one partition in the input data only contribute to one partition in the output data. Therefore, there is no need to move data around to facilitate the generation of partitions in the output DataFrames, which means narrow transformations are fast in general. Some examples of narrow transformations include map() and filter().
In wide transformations, however, the rows required to compute the rows in the same partition in the output data (represented by the output DataFrame) might come from different partitions in the input data (represented by the input DataFrame). In other words, the records in one partition in the input data might contribute to multiple partitions in the output data. Thus, to generate partitions in the output DataFrame, Spark might need to shuffle data around different nodes when producing the output DataFrame. This data shuffling requires extra computational resources in addition to what is required by the transformation process and might slow down the entire ETL process, especially when the data size is huge. Therefore, it is best to avoid wide transformations as much as possible. Some of the most commonly used wide transformations include groupByKey() and aggregateByKey().
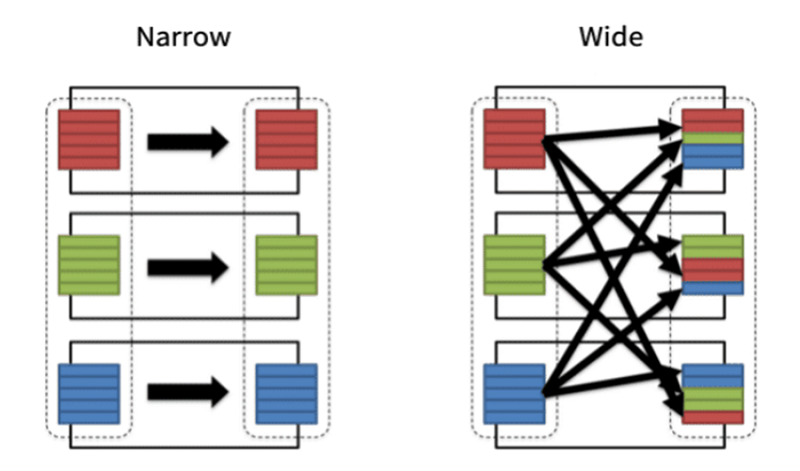
To summarize, to design high-performance ETL processes, it is vital that we fully understand the differences between actions and transformations, and between narrow transformations and wide transformations. Actions involve extracting and loading the actual data, whereas transformations only produce representations of the actual data. Therefore, actions are more compute-intensive than transformations and should only be incorporated into the ETL processes when necessary. Narrow transformations do not involve data shuffling, whereas wide transformations do. Thus, overusing wide transformations might worsen the performance of your ETL process and should be avoided as much as possible.
As long as you keep these differences in mind when building your ETL process, a fully optimized ETL process is no longer a distant dream. Thank you for reading this article, and I hope it is helpful to your Spark journey.