
Unlocking Aurora DSQL with AWS Lambda: A Seamless Solution for Serverless, Scalable, and Event-Driven Architectures

AWS re:Invent has begun and there are tons of new service and feature announcement from the AWS CEO Matt Garman’s Keynote ( check my x/bluesky thread from the keynote updates)
In this blog we will investigate about Amazon Aurora DSQL which is serverless, distributed SQL database with virtually unlimited scale, high availability, and zero infrastructure management claiming 99.99% single-Region and 99.999% multi-Region availability.
My intentions for this blog is to make you understand the architecture, innovation and core components and provide you a completely serverless solution to manage Aurora DSQL using AWS Lambda function with working code 🔥
Motivation

December 4, 2024 4AM (JST) In the Day 2 re:Invent 2024, AWS released an exciting update introducing Amazon Aurora DSQL(Preview)!!!
What does this Update Mean for You?
Here are the key reasons why Amazon Aurora DSQL is a game-changer:
- Unlimited Scalability: Effortlessly scale reads, writes, compute, and storage to handle any workload without sharding or instance upgrades.
- High Availability: Aurora DSQL’s active-active serverless design automates failure recovery, ensuring seamless Multi-AZ and multi-Region availability with strong consistency, eliminating concerns about failovers or data loss.
- Fastest Performance: Offers the fastest distributed SQL reads and writes, making it ideal for high-performance applications.
- Zero Infrastructure Management: Fully serverless design eliminates the need for patching, upgrades, and maintenance downtime, saving time and resources.
- Strong Data Consistency: Aurora DSQL is optimized for transactional workloads that benefit from ACID transactions and a relational data model.
- PostgreSQL Compatibility: Simplifies development with a familiar and widely-used SQL interface, reducing learning curves.
- Developer-Friendly: An intuitive experience that enables rapid application development without operational complexities.
Cost of Aurora DSQL
- Aurora DSQL is currently available in preview at no charge.
Core Components in Aurora DSQL
Distributed Architecture
Aurora DSQL is designed as a distributed database, meaning its parts work together across multiple locations (Availability Zones) to ensure high availability and fault tolerance. It has four main components:
- Relay and Connectivity: Handles how data moves within the system and connects users to the database.
- Compute and Databases: Manages the actual processing of queries and database logic.
- Transaction Log and Isolation: Ensures safe, consistent handling of multiple simultaneous operations (e.g., no data conflicts).
- User Storage: Stores the actual data securely.
A control plane oversees and coordinates these components, which are designed to self-heal and scale automatically if something fails.
Aurora DSQL Clusters
- Single-Region Clusters:
- Your data is synchronized across multiple data centers (AZs) within a single Region.
- This setup avoids issues like replication delays or database failovers.
- Strong consistency ensures all users see the same data no matter where they connect.
- If part of the system fails, requests automatically shift to healthy infrastructure without your intervention.
- Supports ACID transactions (ensuring reliability, consistency, and durability).
- Multi-Region Linked Clusters:
- These extend the above features across multiple Regions, offering two endpoints (one in each Region) that act as a single database.
- Both Regions can handle reads and writes simultaneously while ensuring strong consistency.
- Ideal for global applications where performance and resilience are crucial.
PostgreSQL Compatibility
Aurora DSQL is built on PostgreSQL 16, a popular open-source
How Data Resiliency and Backup is supported
Backup and Restore
- Currently, backup and restore is not supported during the preview phase.
- Aurora DSQL plans to integrate with the AWS Backup console, enabling full backup and restore capabilities for both single-Region and multi-Region clusters.
Replication
- Transaction Logs:
- Aurora DSQL commits all writes to a distributed transaction log and replicates data synchronously across three AZs.
- Multi-Region Replication:
- Provides cross-Region replication for both read and write Regions.
- Uses a witness Region for encrypted transaction log storage, requiring no manual configuration or storage overhead.
- Data Management:
- Automatically splits, merges, and replicates data based on access patterns and primary key ranges.
- Dynamically scales read replicas based on read demand.
- Self-Healing:
- Redirects access during AZ impairments and repairs missing data asynchronously.
- Repaired replicas are added back to the storage quorum automatically.
High Availability
- Active-Active Design:
- Both single-Region and multi-Region clusters are active-active, with fully automated recovery.
- Eliminates the need for traditional primary-secondary failover processes.
- Multi-AZ Replication:
- Ensures synchronous replication across three AZs, avoiding risks of data loss or lag.
- Regional Endpoints:
- Single-Region clusters offer a redundant endpoint for consistent reads and writes across three AZs.
- Multi-Region clusters provide two Regional endpoints for zero-lag, strongly consistent access across Regions.
- Use Amazon Route 53 for managed global endpoints if needed.
Using AWS Lambda with Aurora DSQL
Ofcourse its re:Invent and I would explain my readers a innovative way to connect to Aurora DSQL Database and perform Database operations like creating table and inserting some data using AWS Lambda function
During preview, you can interact with clusters in us-east-1 – US East (N. Virginia) and us-east-2 – US East (Ohio).
Create Aurora DSQL database
- Search Aurora DSQL in console
- For this blog I am creating single region database and keeping other confgiraution as default. In the preview, name of the cluster is configured using Name Key-Value Tags.
- Select create cluster and after creation copy the endpoint url of DB.
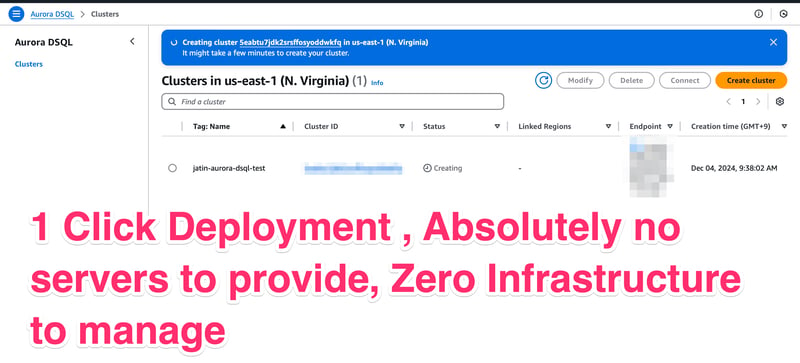
- That’s it nothing else to manage, provision. That’s 1 click deployment of Aurora DSQL for you!!!
Create Lambda function
This lambda function will connect to Aurora DSQL database, create table, insert some data and then verify that data by reading it back. Yes a truly server less operation using Lambda and Aurora DSQL
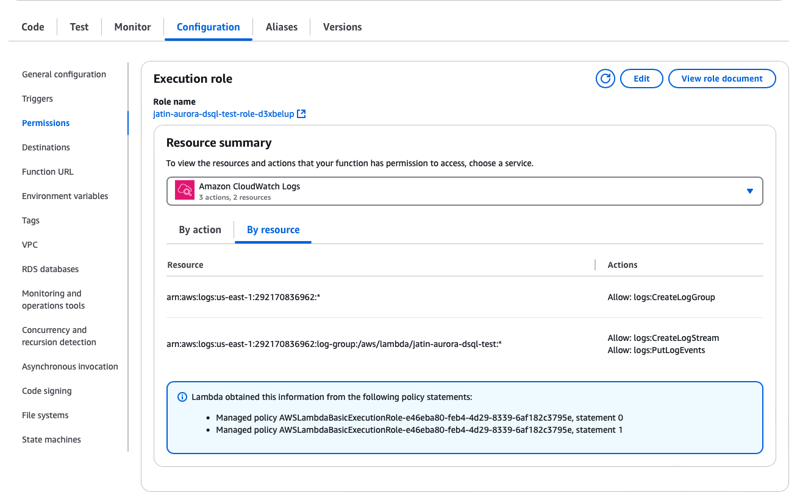
- Authorize your Lambda execution role to connect to your cluster by adding inline policy Admin role as inline Policy to all the resources.
- Lambda -> Configuration -> Permissions -> add inline policy
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement1",
"Effect": "Allow",
"Action": ["dsql:DbConnectAdmin"],
"Resource": ["*"]
}
]
}
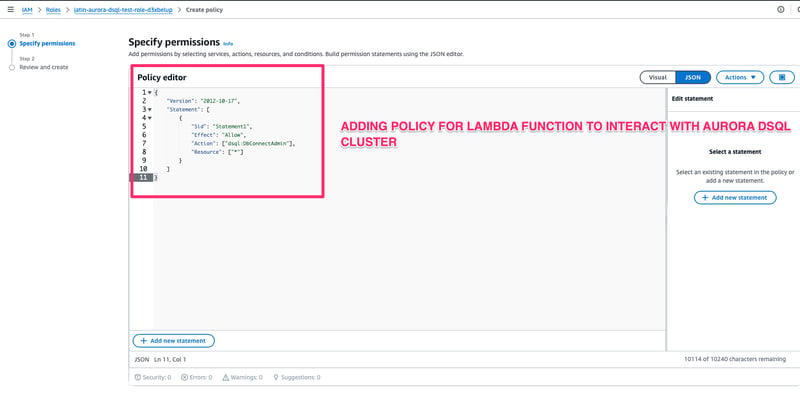
Note: You shouldn’t use a admin database role for your production applications, doing this for the blog
- If you have worked with Lambda then you know we need to upload a zip package. I have shared the lambda code in my repository
- Use the following commands after forking and pulling the repository to your local machine
npm install. //generates package-lock.json
cd ~/path-to-code
zip -r pkg.zip .
- Upload the package
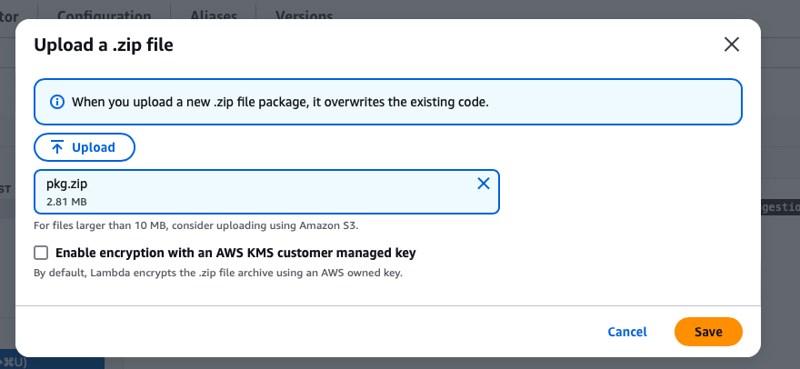
- In your Lambda function’s Test tab, use the following Event JSON modified to specify your cluster’s endpoint.
{"endpoint": "replace_with_your_cluster_endpoint"}
You can also use Environment Variables then you need to change code and refer endpoint as
process.env.ENDPOINT
Test the the truly serverless operations (LAMBDA + Aurora DSQL)
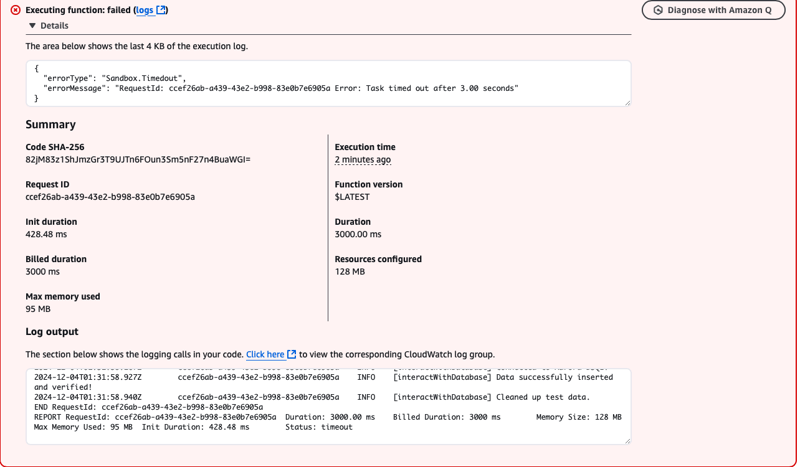
- Implementation worked but it failed
- Lets use Amazon Q to diagnose it and fix it for us
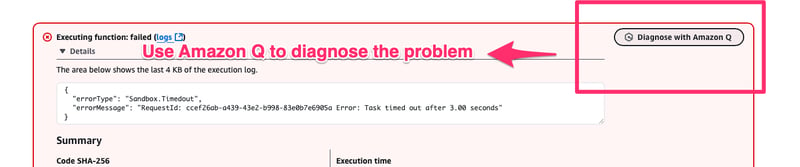
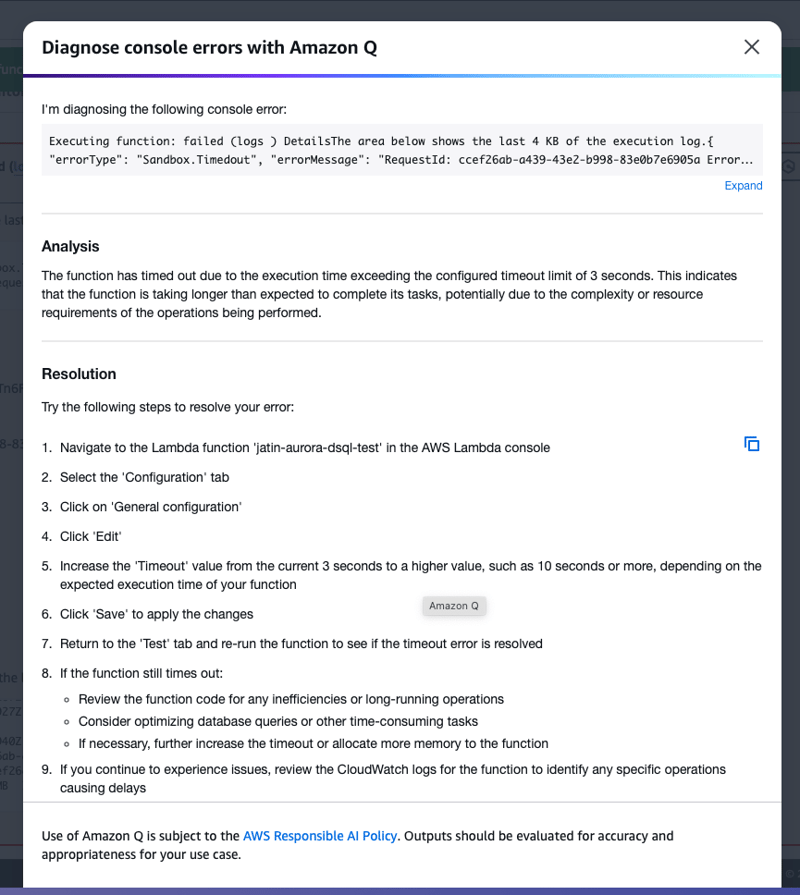
- Increasing Lambda timeout to 10 seconds from default 3 seconds
- Voila it worked.
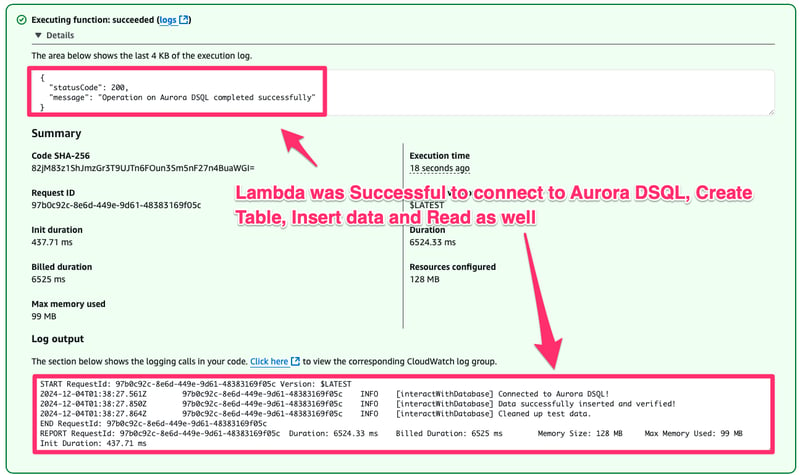
**Note:**TO verify Data we are using the following code within our Lambda Function
assert.strictEqual(result.rows[0].city, "Anytown");
assert.notStrictEqual(result.rows[0].id, null);
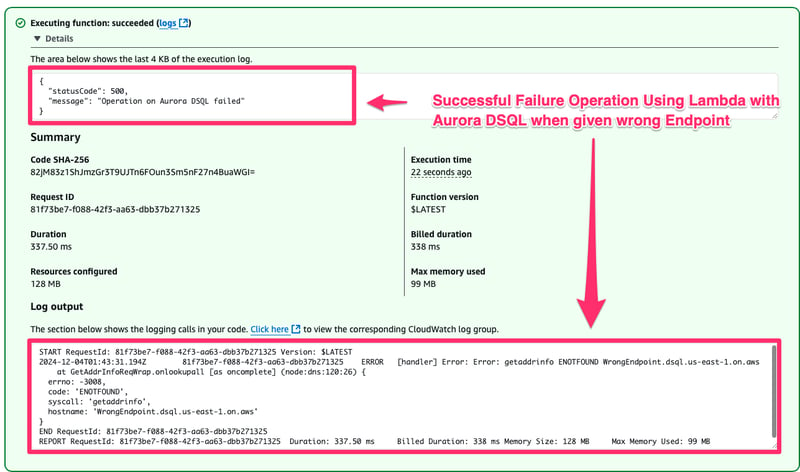
- Now lets try to fail the lambda by giving wrong endpoint

Understanding authentication and authorization for Aurora DSQL
- Aurora DSQL uses IAM roles and policies for cluster authorization and authentication. You associate IAM roles with PostgreSQL database roles for database authorization.
- When you connect, instead of providing a credential, you use a temporary authentication token (valid for 1 hour).
- For authentication:
- *If you’re using the admin role:* IAM identity should have the policy action of
dsql:DbConnectAdmin - *If you’re using the custom database role:* IAM identity should have the policy action of
dsql:DbConnect
- *If you’re using the admin role:* IAM identity should have the policy action of
Interact with your database using PostgreSQL database roles and IAM roles
- For Database Authorization:
- Use PostgreSQL database roles for database-level authorization.
- Aurora DSQL provides two types of roles:
- Admin Role: Pre-created by Aurora DSQL, unmodifiable, and used for administrative tasks like creating custom roles.
- Custom Roles: Created by you and assigned PostgreSQL permissions as needed.
- Role Association:
- Link custom database roles with IAM roles to allow IAM identities to connect to the database.
- Authentication and Authorization:
- Use the admin role to connect to clusters and manage custom roles.
- Use the AWS IAM GRANT command to associate IAM identities with custom roles for database access.
For detailed steps, refer to:
Exploring Aurora DSQL: Access, Development, and Best Practices
I am very happy and satisfied with the documentation for the Aurora DSQL. It’s to the points and really well written.
When working with aurora there will certain topics which would be of interest like:
- Accessing Aurora DSQL
- Working with Amazon Aurora DSQL
- Programming with Aurora DSQL
- Utilities, tutorials, and sample code in Amazon Aurora DSQL
- Security and its best practices : It is important to understand both Detective Best practices as well as Preventive security Best Practices
- At the writing of this blog there are unsupported PostgreSQL features in Aurora DSQL which should be considered too
From Solutions Architect Perspective
- We saw in this blog how we can create Aurora DSQL cluster with just one click. It is truly serverless.
- We also saw how an example of a truly serverless solution for managing Aurora DSQL database using AWS Lambda functions making Aurora DSQL is ideal for application patterns of microservice, serverless, and event-driven architectures
- Amazon Aurora is a game changer for developers, offering serverless architecture with automatic scaling, high availability, and resilience. It eliminates the need for manual database management, allowing developers to focus on building applications. With Aurora, developers can innovate faster while ensuring reliability and efficiency.
- Aurora DSQL is PostgreSQL compatible, so you can use familiar drivers, object-relational mappings (ORMs), frameworks, and SQL features.
Did you tried the Lambda solution presented in the blog and do you think this will be game changer for serverless event driven and micrservice architectures?