
All You Need to Know about Isolation Levels and Read Inconsistencies

Just like real life, the world of computer science is replete with trade-offs. Relational databases are no exception. When interacting with relational databases, we face the dilemma between data consistency and transaction concurrency. The former guarantees the data is trustworthy, while the latter ensures relational databases can conduct transactions swiftly. Both are desirable qualities of relational databases, but we cannot simultaneously achieve them to the fullest extent. Today, I will discuss how isolation levels can help us structure our decision-making regarding this dilemma.
Read Inconsistencies
Before diving into isolation levels, I will first introduce three common read inconsistencies in relational databases: dirty read, non-repeatable read, and phantom read. They are data inconsistencies caused by concurrent transactions. They are crucial to understanding isolation levels because whether they are present or absent in an isolation level determines its degree of data consistency.
Dirty Read
A dirty read is essentially a read of uncommitted data. It occurs when a transaction reads data modified by another transaction but not committed yet.
Here is an example: Suppose there are two transactions: T1 and T2. They both interact with the same table called “BankAccount.” This table contains the following row.

T1 reads the above row in the BankAccount table, while T2 modifies it.
-- T1's SQL Statement:
SELECT balance FROM BankAccount WHERE account_number = 88;
-- T2's SQL Statement:
UPDATE BankAccount SET balance = 800 WHERE account_number = 88;
So far, the entire process sounds like a series of innocuous database operations. However, the problem is that when T1 reads the row, T2 has already modified it but has not committed it yet, which causes T1 to end up reading dirty data. It might cause an even more serious issue if we use T1’s dirty data for further operation when the database rolls back the modifications made by T2 due to some failures.
Non-Repeatable Read
A non-repeatable read occurs when two reads of the same row within a transaction have different results. The reason is that another committed transaction has modified that row after the first and before the second read of the former transaction.
Here’s an example: Suppose there are two transactions: T1 and T2. They both interact with the same table called “Book.” This table contains the following row.

T1 reads the above row in the Book table twice, while T2 modifies it.
-- T1's SQL Statement:
SELECT price FROM Book WHERE id = 1; SELECT price FROM Book WHERE id = 1;
-- T2's SQL Statement:
UPDATE Book SET price = 20 WHERE id = 1;
T1’s first read successfully retrieves the original price (15) of The Great Gatsby. Then T2 updates the row and modifies the price before T1’s second read begins. In the end, T1’s second read obtains the latest price (20), resulting in T1’s inconsistency between its two reads of the same row.
Phantom Read
Similar to a non-repeatable read, a phantom read is also a type of read inconsistency within the same transaction. It occurs when two identical reads within the same transaction return different numbers of rows. The reason is that another committed transaction has inserted or deleted some rows after the first and before the second read of the former transaction.
Here’s an example: Suppose there are two transactions: T1 and T2. They both interact with the same table called “Book.” This table contains the following row.

T1 reads all the rows in the Book table twice, while T2 inserts a new row into the Book table.
-- T1's SQL Statement:
SELECT * FROM Book; SELECT * FROM Book;
-- T2's SQL Statement:
INSERT INTO Book (id, title, price) VALUES (2, 'Pride and Prejudice', 20)
T1’s first read retrieves the only row (The Great Gatsby) in the Book table. Then T2 inserts a new row (Pride and Prejudice) into the Book table before T1’s second read starts. In the end, the result of T1’s second read consists of two rows (The Great Gatsby and Pride and Prejudice), including the new one inserted by T2.
Isolation Levels
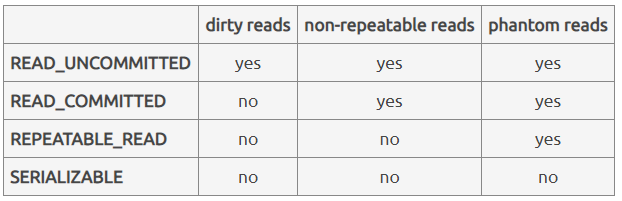
Next, let’s dive into SQL transactions’ four isolation levels. I will start with the lowest isolation level and examine the rest in ascending order.
Read Uncommitted
Read Uncommitted is the lowest level of isolation. It also corresponds to the highest level of transaction concurrency, placing no restrictions on transactions concurrently accessing and modifying the database. All the read inconsistencies I mentioned above (dirty reads, non-repeatable reads, and phantom reads) are possible.
Read Committed
Read Committed is the second lowest level of isolation. It allows concurrent transactions as long as transactions do not read uncommitted data. Due to this restriction, Read Committed eliminates the possibility of dirty reads at the cost of concurrency. Nonetheless, non-repeatable reads and phantom reads might still occur.
Repeatable Read
Repeatable Read is the second highest isolation level. In addition to the restriction placed by Read Committed, Repeatable Read bans two reads of the same row within the same transaction from having different results. It achieves this restriction by placing shared locks on all data read by each statement in a transaction. The database won’t release the shared locks until their corresponding transaction is complete. As a result, other transactions are not able to make changes to the locked data. This additional restriction further decreases the level of transaction concurrency. Thanks to this restriction, Repeatable Read renders non-repeatable reads impossible. However, Repeatable Read still faces the risk of phantom reads.
Serializable
Serializable is the highest isolation level. As its name suggests, it allows transactions to occur concurrently only if the results they produce are the same as if they are executed serially. In addition to the restrictions placed by the previous two isolation levels, it further disallows two identical reads within the same transaction to return different numbers of rows. It achieves this restriction by placing range locks in the range of data that match the search conditions of all statements in a transaction. The database holds all the range locks before their corresponding transaction finishes. This restriction drops transaction concurrency to the lowest, but it helps Serializable achieve the highest level of data consistency. All three read inconsistencies (dirty reads, non-repeatable reads, and phantom reads) are out of the question.
Tips on Which Isolation Level to Choose
Now that we have covered the four isolation levels, some of you might ask, “which isolation level should I pick for my relational database then?” This question essentially boils down to how much concurrency you are willing to forego in exchange for data consistency.
Read Uncommitted
A rule of thumb is to avoid using Read Uncommitted because dirty read is the most undesirable type of data inconsistency. The only exception is when performance is way more important than data consistency.
Read Committed
Read Committed is the default isolation level in most databases. It provides a good balance between concurrency and consistency. If you are unsure about which isolation to choose, you can safely start by experimenting with Read Committed.
Repeatable Read
Repeatable Read offers great data consistency at the cost of concurrency. The only read inconsistency that plagues this isolation level is phantom read. You should choose Repeatable Read when you value data consistency over the performance of your system.
Serializable
Serializable boasts the highest level of data consistency. In return, it suffers from the lowest level of transaction concurrency and hence the worst performance. Serializable is an appropriate choice when you have a zero-tolerance policy against data inconsistency, but please remember your system’s performance will take a hit consequently.
In this blog, I covered three types of read inconsistencies (Dirty Read, Non-Repeatable Read, and Phantom Read) and four isolation levels (Read Uncommitted, Read Committed, Repeatable Read, and Serializable). Each isolation level tolerates some read inconsistencies while forbidding others. Choosing between these isolation levels is essentially a trade-off between concurrency and consistency. I hope this article is helpful to you.