
A Brief Introduction to Kafka

There’s no denying that we have already ushered in the era of big data. An enormous amount of information is generated every second. While decision-makers can gain invaluable insights from this ever-growing data, its sheer volume also poses considerable challenges to data engineers–greater demand for storage spaces, the need to handle increasingly complex data formats, and highly unpredictable network traffic. Luckily, recent years have witnessed the creation of various technologies devoted to efficiently digesting big data, and Kafka is one of them. Today, I will demonstrate how Kafka works to help kick-start your Kafka journey.
First, let’s start with a brief introduction to Kafka. Kafka, or Hadoop Kafka, is a distributed streaming platform that facilitates the publishing and consuming of data streams. It was originally developed by LinkedIn and is now maintained by the Apache Software Foundation. Kafka is fault-tolerant and scalable, which makes it a perfect tool for building real-time data pipelines and streaming applications.
Some of you might ask, “why is Kafka fault-tolerant, scalable, and suitable for processing data streams?” To answer this question, we need to dive deep into the inner-working of Kafka.
Important Components in Kafka
- Topic: A topic is a category or stream name to which Kafka publishes messages, namely the data it receives. If you are familiar with relational databases, you can think of a topic as a table. There can exist multiple topics in a system, each storing data on a specific entity. Kafka further splits each topic into multiple partitions, each of which can be hosted on a different broker (server).
- Broker: A broker is a server that can host partitions for one or more topics. Distributing partitions across multiple brokers has the following merits. First, it allows Kafka to handle large volumes of data and support high throughput. Second, it enables Kafka to replicate data across partitions. This is especially useful when a broker is down because then Kafka can transfer data hosted by the non-functional broker to another broker, which ensures the overall system’s fault tolerance. Third, it makes scaling out such an effortless task for Kafka, thus ensuring Kafka’s horizontal scalability.
- Cluster: A Kafka cluster is a collection of brokers that work together to manage and store the data in Kafka.
Now that we have covered the inner working of the most crucial components in Kafka and why Kafka derives its most desirable traits from them, let’s closely inspect how Kafka fits in with big data processing with an easy example.
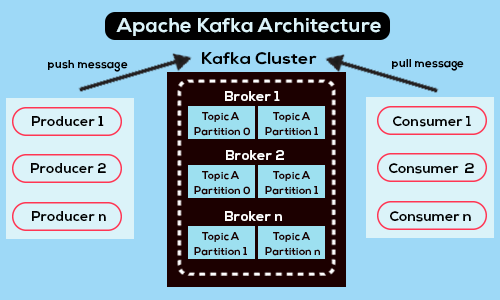
Source: https://www.projectpro.io/article/apache-kafka-architecture-/442
Assume that we have a data producer and a data consumer, and we intend to use Kafka to help the data consumer digest the data generated by the data producer. Also, assume that the data consumer has subscribed to the topic (referred to as Topic A henceforth) to which the data producer publishes data. At the beginning of the workflow, the data producer generates some data. Then, the data producer sends the data to Kafka as a message, specifying that it intends to post to Topic A. Kafka then publishes the message to Topic A. Kafka might store the message in more than one partition of Topic A, allowing the same message to exist in multiple brokers. After that, the data consumer attempts to pull the message from Topic A because it has subscribed to Topic A. It will send a request to the cluster containing the brokers that host Topic A. The cluster then locates the message and commands the broker storing the message to deliver it to the data consumer, completing the workflow.
To ensure that the data consumer can process all the data consistently and predictably, Kafka brokers deliver messages to the data consumer in the order the messages are received. The data consumer also utilizes offsets, namely unique identifiers assigned to each message in a topic, to keep track of the progress of its data consumption. By committing an offset, the data consumer indicates to Kafka that it has already processed the message corresponding to the offset, and is ready to receive the subsequent messages.
It is worth noting that we can use Kafka to facilitate data transfer between multiple data producers and consumers, which makes Kafka a truly powerful tool for easing data processing in a complicated system.
In a nutshell, I have touched upon the most vital components of Kafka and why they make Kafka the highly scalable and fault-tolerant tool that it is. In addition, I have also demonstrated how Kafka acts as a middleman between data producers and data consumers, helping data producers transfer the data they generate to data consumers for further consumption. I hope this article has assisted you in embarking on your Kafka journey!