
A Brief Introduction to the Inner Working of MapReduce

As a data engineer, you probably have heard about Hadoop. It is one of the most popular frameworks for distributed processing of large data sets. It is less costly and more secure than other frameworks. At its center is a programming model called MapReduce. Today we will take a closer look at MapReduce to understand the inner working of Hadoop.
As suggested by its name, MapReduce has two main steps: Map and Reduce. In addition to these two steps are three intermediate steps: Combine, Partition, and shuffle. Let’s go through them with an example of a data processing task that seeks to compile a word count report for a document. In order to keep it simple, our source document only contains three lines, each of which has three words.

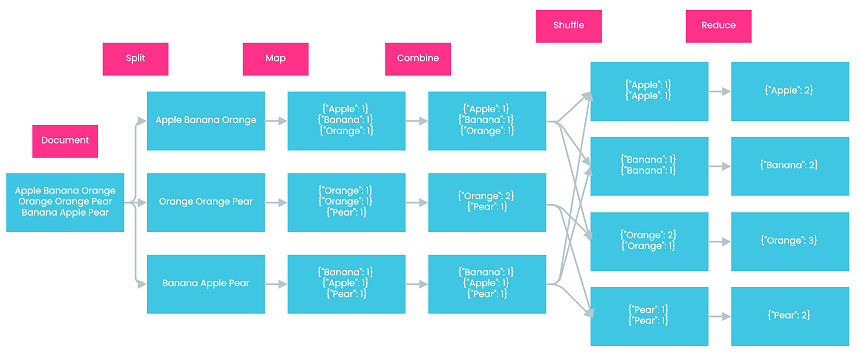
Split In the Split Step, Hadoop splits the input data into smaller chunks. This step aims to distribute data to individual map nodes to facilitate subsequent parallel processing. In our example, Hadoop splits the source document into three chunks, each containing one line from the source document.
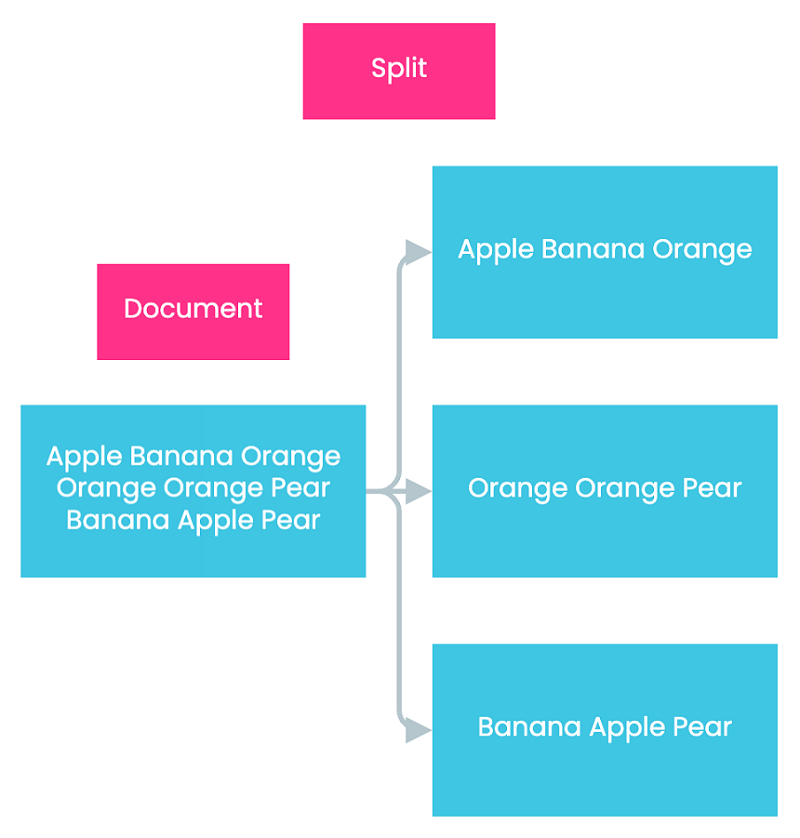
Map In the Map step, Hadoop assigns a mapper to process each data chunk. The output of each mapper’s computation is a list of key-value pairs. In our example, Hadoop assigns three mappers to process our data chunks, since there are three data chunks in total. Each mapper then generates three key-value pairs. The value of each key-value pair is one, denoting that each word appears exactly once within the scope of itself.
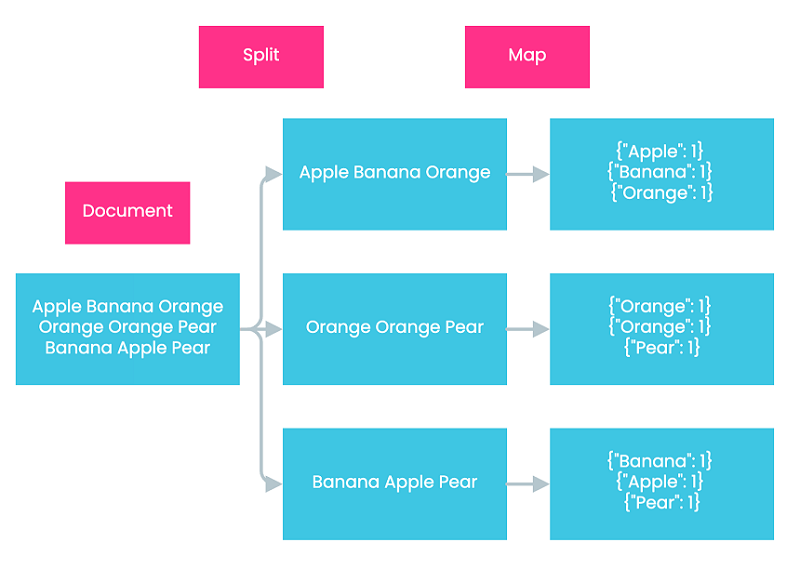
Combine The Combine step is an optional step that involves the use of a combiner. A combiner is essentially a reducer that runs individually on a mapper. It further reduces the data on each mapper to a more simplified form to facilitate computation in later steps, usually achieved by combining values corresponding to identical keys. Let’s assume that our example involves the Combine step in Hadoop. In the second mapper, we have two key-value pairs with the same key “orange.” Therefore, we combine them into one and add up their values, which results in {“orange”: 2}, denoting that the word “orange” has appeared twice in the second mapper. All the other mappers don’t contain key-value pairs with identical keys. Therefore, no combination is performed on them.
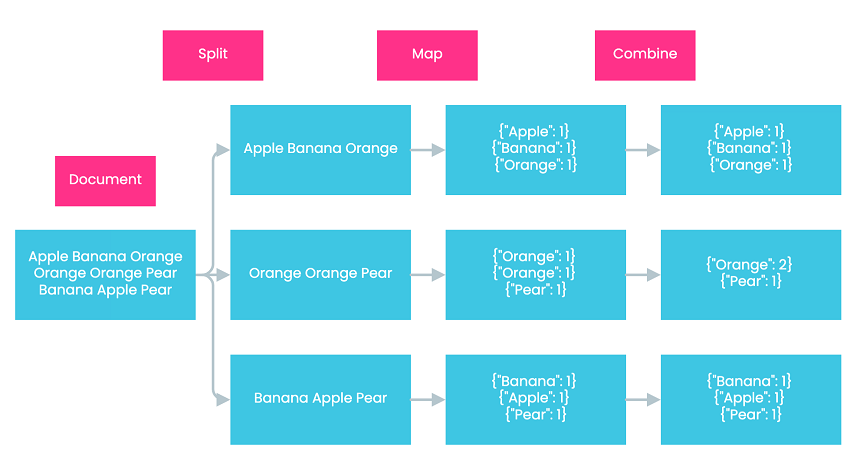
Shuffle In the shuffle step, Hadoop sends the key-value pairs generated by mappers to their corresponding reducers. Key-value pairs with the same keys are sent to the same reducers. In our example, since there are four different keys, Hadoop generates four reducers. Each reducer is responsible for one key and only receives key-value pairs with that key. For example, the third reducer only receives key-value pairs with the key “orange.”
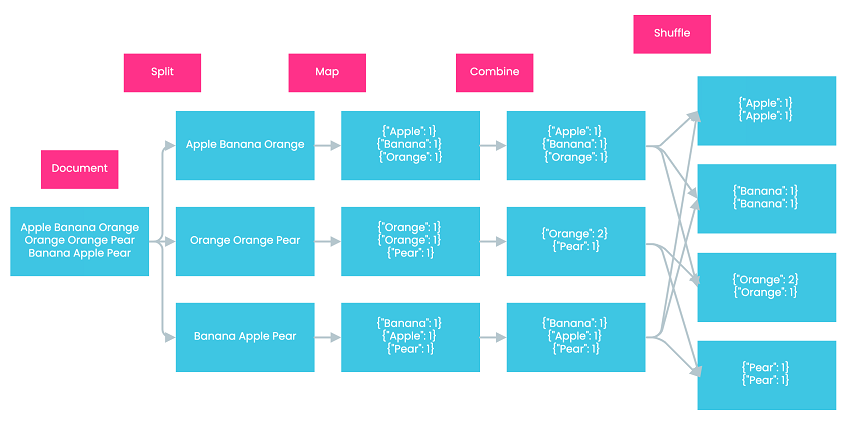
Reduce In the reduce step, each reducer consolidates its assigned key-value pairs to generate the final output for each key. In our example, each reducer reduces the key-value pairs by adding their values to calculate the final count for each word. For instance, the third reducer reduces {“orange”: 2} and {“orange”: 1} to {“orange”: 3}, indicating that the word “orange” has appeared in the document three times in total.
After the reduce step, Hadoop combines the outputs of all reducers to generate the final result. In our case, the final result is {“Apple”: 2, “Banana”: 2, “Orange”: 3, “Pear”: 2}.
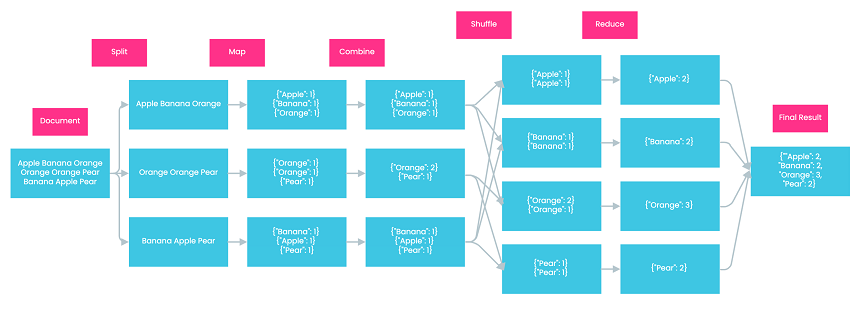
In brief, MapReduce consists of five main steps: Split, Map, Combine, Shuffle, and Reduce. Although each of these steps only performs a simple task individually, together they enable Hadoop to process large amounts of data efficiently. I hope this article has helped you gain a deeper understanding of how MapReduce works under the hood.