
ETL vs. ELT: Pick the Most Suitable Data Integration Method for Your Project

As a data engineer, you probably have heard of the data integration methodology called ETL (Extract-Transform-Load). It has been around for a while, and many data engineers have used this methodology to build data pipelines. However, ETL is not the only option up our sleeves. Recently, ELT has also been gaining a lot of popularity. In this article, I will compare ETL and ELT to help you understand their respective advantages and drawbacks so that you can choose the methodology more suitable for your project.

Let’s first look at how ETL works. An ETL process typically starts with extracting data from a data source. Then, it proceeds to perform some transformations on the data previously extracted. Lastly, it loads the transformed data to a repository for future use. The fact that data transformation takes place before loading in ETL processes contributes to most of ETL’s advantages, which are as follows.
First, ETL allows for immediate access to readily transformed data after the ETL processes are complete. Such instantaneous access enables us to do little to no preparation before consuming the data. Second, the data lineage of an ETL process is transparent and easily understandable because, for each ETL process, the data transformation process is predefined and remains the same. Third, ETL is compliance-friendly. Sometimes, we might need to conform to privacy compliance, which requires us not to load private information to the final destination. ETL is suitable for such compliance requirements because it can mask, encrypt, or remove sensitive information in the transformation stage before storing data.
Nevertheless, ETL has its fair share of shortcomings: First, ETL processes can be rather time-consuming. Since all the data transformation needs to finish before data loading takes place, data won’t be available for consumption until the data transformation completes. Depending on the complexity of the data transformation process, the final data might not be accessible for long. Second, ETL has the problem of rigidity. Since the transformation process is predetermined, it is hard to modify ETL pipelines in response to ad-hoc requirements. Third, ETL can be brittle. Performing data transformation before loading data to the final data storage means that ETL pipelines save no data if anything goes wrong in the transformation stage.
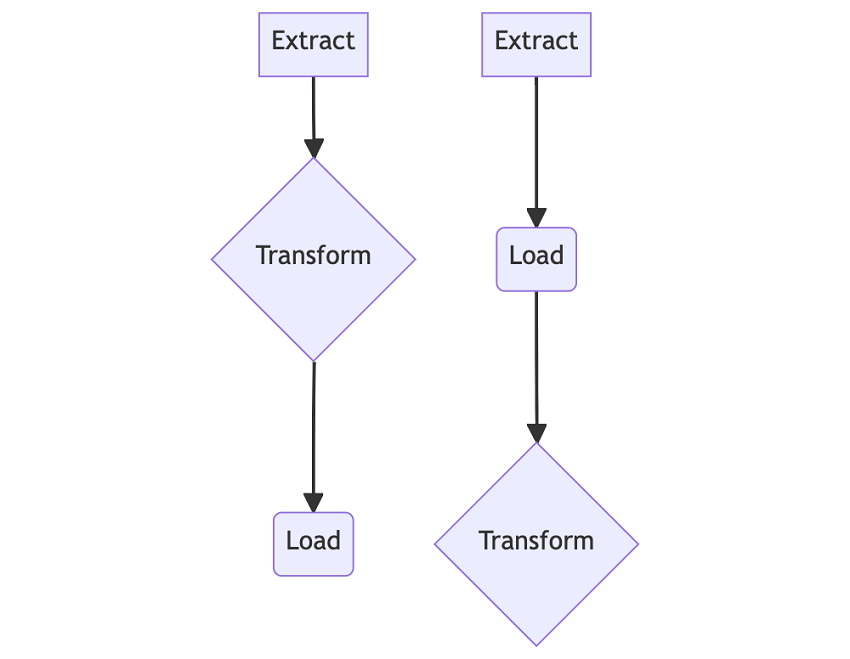
To overcome ETL’s shortcomings, data scientists devised a new data integration methodology, namely ELT. ELT stands for extraction, loading, and transformation. While ETL and ELT share the same basic steps, the orders in which they perform these steps are different. Unlike ETL, ELT processes load the entirety of the extracted data before performing data transformation, which brings about the following benefits of ELT.
First, ELT pipelines allow us to instantly access the data, albeit untransformed, thanks to their loading of the extracted data before data transformation. Second, ELT has more flexibility. If we adopt the ELT methodology, we can customize the data transformation process every time based on our changing requirements for data consumption because we have access to all the data extracted from the initial data sources. Third, it is easy to store unstructured data with ELT pipelines. Even if we do not have the time or computation resources to transform or structure the initial data, we can still save all of it and worry about transformation and structuring later on.
In summary, ETL and ELT contain the same basic steps: extraction, transformation, and loading. Their respective pros and cons mainly stem from whether data transformation is performed before or after loading. Now that you thoroughly understand the differences between ETL and ELT, it should be easier for you to pick the most suitable data integration methodology for your projects. Here is a rule of thumb: choose ETL over ELT when you have structured small-sized source data and the required format of your target data remains relatively consistent. On the other hand, pick ELT over ETL when you have unstructured large-sized source data and the requirements for your target data are ever-changing. Thank you for reading this article, and I wish you all the best with your data engineering journey.
Further readings: ETL vs ELT Overview