

If you have been in the world of big data long enough, you probably have heard about Parquet files. You might even have used it while thinking to yourself: “why can’t we just use CSV files?” Today, I will debunk the mystery of Parquet files and explain why a growing number of data scientists prefer Parquet files to CSV files.
Let’s start with an example. Assume that we have a dataset with 100 columns and millions of rows (such datasets are common in the field of big data). However, we only need to extract five columns for our data analysis project. In addition, we need to filter out rows that do not fit a certain set of criteria. We have three options for data storage formats: CSV, ORC, and Parquet.
CSV is one of the most commonly used file formats for storing data. It stores data in a row-based manner (as shown in the image below), meaning rows are stored one after another. Such a structure is great for selecting rows since rows can be easily sorted. However, when it comes to selecting columns, reading data from CSV files is inefficient and time-consuming. In our case, we need to scan through all the columns in the table, even though we only need ten columns.
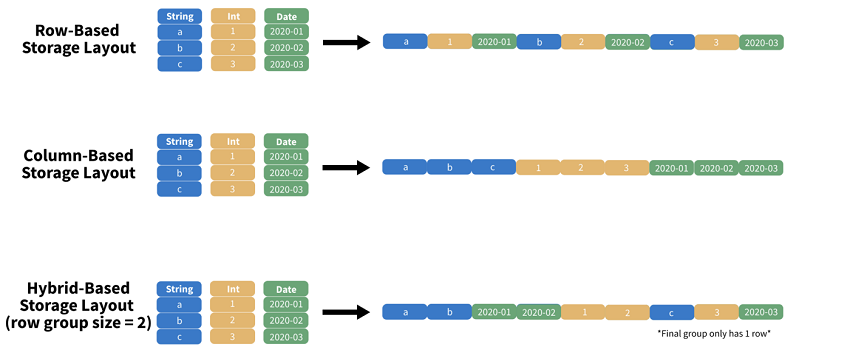
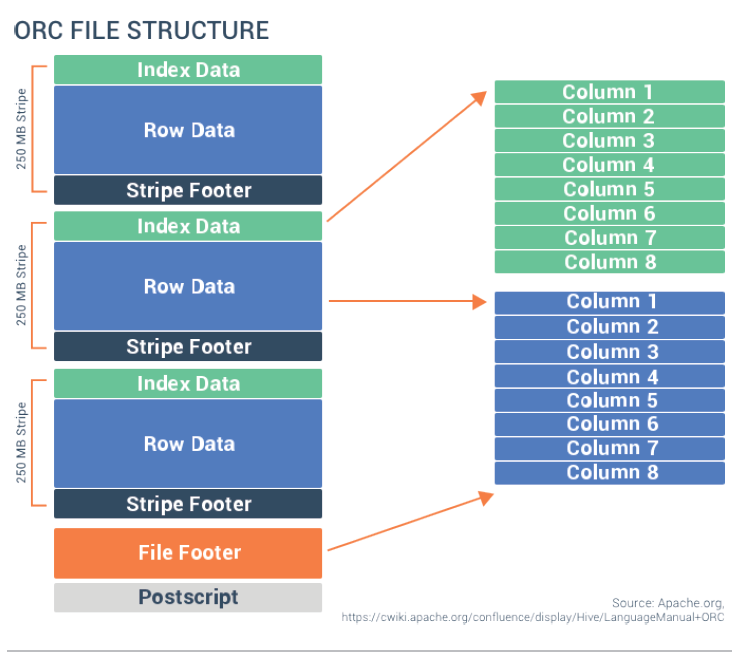
Our second option is ORC. ORC is a column-oriented data storage format. It stores data in columns one after another (as shown in the image below). As a result, selecting columns from ORC files is an efficient process. Nevertheless, row selection in ORC involves interacting through all the rows, which hinders its performance.
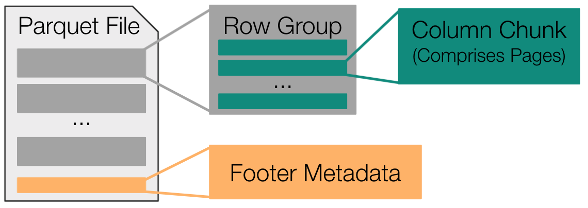
Last but not least, we can also choose Parquet to store data. Parquet is a hybrid-based data storage format. It is hybrid in the sense that it combines characteristics of both column-based and row-based data storage formats (as shown in the image below). Here is how this hybrid style of structuring data works: Every parquet file is divided into several row groups, each containing several rows. Every row group consists of several column chunks, each of which corresponds to a column in the original table.
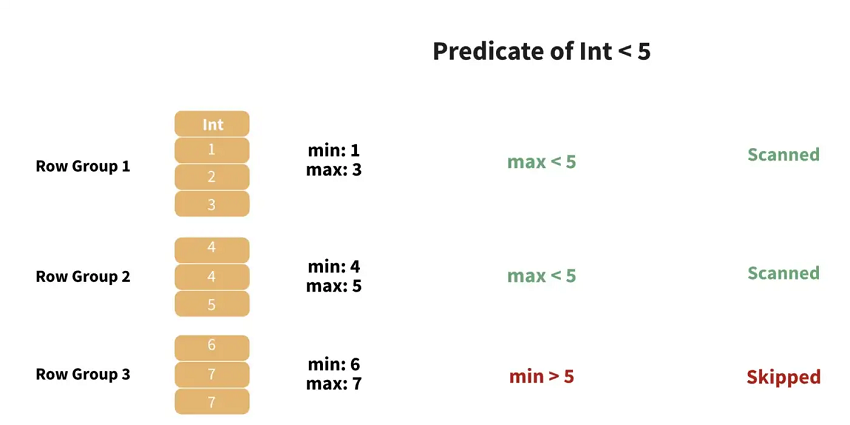
In terms of column selection, irrelevant columns can be easily skipped when collecting data from each row group. As for row selection, Parquet makes use of the maximum and minimum values of each column chunk in the row groups to skip over unwanted rows. A row group won’t be scanned if there exists at least one column whose maximum and minimum values do not meet the given criteria (as shown in the image below). Thanks to the above mechanisms for column and row selection, we can avoid scanning unnecessary data in both dimensions, which results in Parquet’s top-notch data extraction performance.
As shown above, Parquet files outperform CSV files in terms of the speed of data retrieval. Does it mean that Parquet files to occupy more space to achieve the decrease in time complexity? The answer is no. Quite the contrary, Parquet files take up less space than CSV files to store the same amount of data. The reason behind this is because Parquet employs various algorithms to compress data, including run length encoding, dictionary encoding, and delta encoding.
All in all, Parquet files are superior to CSV files in almost all aspects. First, data selection in Parquet is more efficient due to its hybrid-based (both row-based and column-based) storage format. In addition, Parquet also requires less space thanks to the compression algorithms it employs. Therefore, Parquet should definitely be your go-to file format if you’re a data scientist trying to build efficient data processing systems.
Recommended reading: What is Parquet (Detailed performance comparison) Understanding the Parquet file format (compression) What is the Parquet File Format? Use Cases & Benefits