

Few would disagree that the word “lazy” has a negative connotation. We usually describe someone who is not willing to work hard as lazy. However, not all laziness is undesirable, and sometimes we prefer laziness to diligence, especially in the computer science world. One example is lazy evaluation. Today, we will closely inspect why lazy evaluation is essential to Spark’s high performance and how lazy evaluation works in Spark.
Let’s start with the definition of lazy evaluation. According to Wikipedia, lazy evaluation is an evaluation strategy that delays the evaluation of an expression until its value is needed. In other words, if an expression is lazily evaluated, then its value won’t be calculated until necessary. You might ask, why can’t we evaluate the expression as soon as we encounter it, i.e., eagerly evaluating it? The reasons are twofold:
First of all, lazy evaluation helps improve Spark’s efficiency. Spark uses a catalyst optimizer to automatically look for the most efficient way to execute data operations. If we were to eagerly evaluate all expressions in Spark, then the catalyst optimizer would separately optimize the execution plans for the calculation of all intermediate expressions. Thus, the catalyst optimizer could not produce a globally optimal execution plan. On the contrary, if we adopt the lazy evaluation strategy and skip the calculation of all intermediate expressions, then the catalyst optimizer can analyze the entire chain of operations, thus obtaining the information necessary for generating a globally optimal execution plan.
An easy example would be adding a new column to a DataFrame and removing it. If we lazily evaluate the final expression, then the catalyst optimizer can analyze the overall chain of operations. Since the addition and removal of a new column are equivalent to no operation at all, the catalyst optimizer will instruct Spark not to change the initial DataFrame when extracting its data, thus making the entire process highly efficient. However, if we were to eagerly evaluate all the expressions, including the intermediate ones, then the catalyst optimizer would not have enough information to eliminate the addition and removal operations, resulting in overall inefficiency.
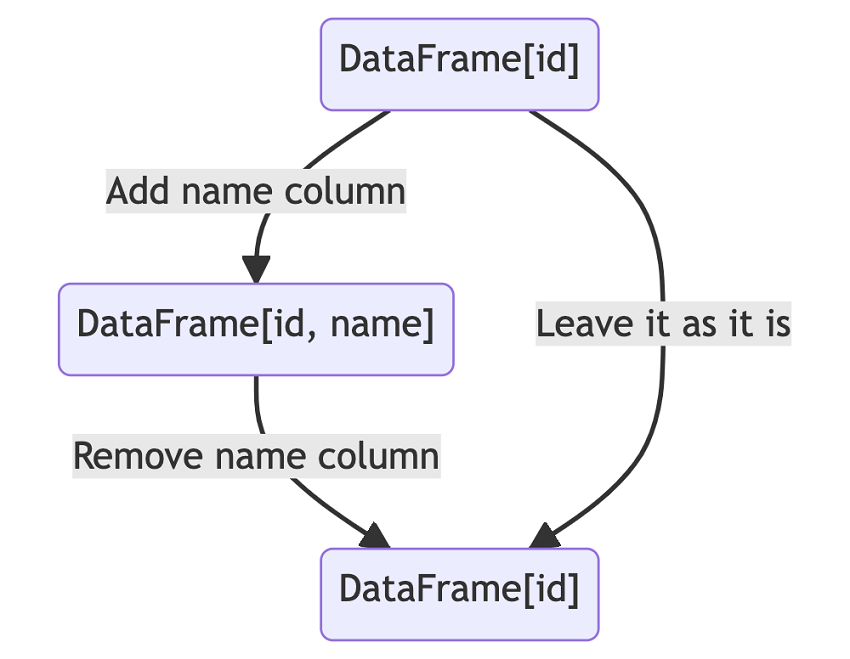
Second, lazy evaluation reduces the total space required to store the data. If Spark eagerly evaluated all the intermediate expressions, then these expressions needed to occupy some space. In contrast, lazy evaluation helps reduce the temporary storage used to store intermediate expressions. As a result, lazy evaluation also improves the overall space utilization of Spark.
Now that we have established that lazy evaluation is crucial to Spark’s effort to improve overall efficiency, let’s look at how lazy evaluation works in Spark. Instead of eagerly evaluating all expressions and calculating the data corresponding to each expression, Spark uses DataFrames to represent data. These DataFrames are essentially DAGs (Directed Acyclic Graphs), containing information about all the data sources and modifications necessary to generate the data described by these DataFrames. As we can see, DataFrames are essential to Spark’s actualization of lazy evaluation.
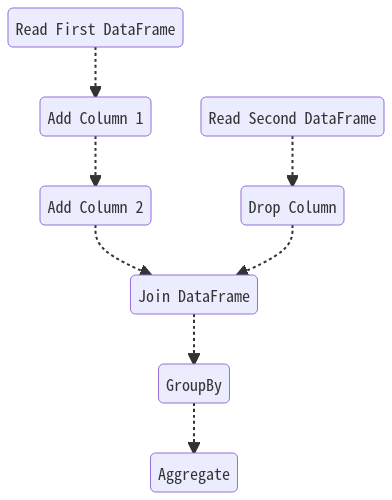
In order to alter the data represented by a DataFrame, we can apply transformations to it. Transformations specify how to modify a DataFrame without performing the actual modifications. Spark does not execute the modifications until it calls an action on a DataFrame. Unlike transformations, actions are eagerly evaluated. They involve extracting the actual data represented by the DataFrame. (You can read more about transformations and actions in this blog.)
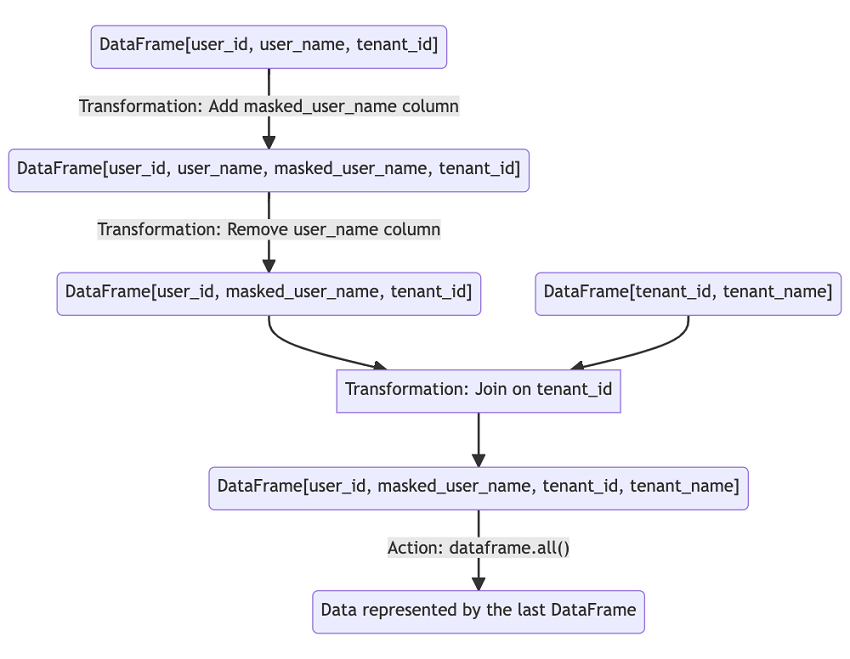
Let’s take a look at another example. As shown in the flowchart below, we start with a DataFrame containing three columns: user_id, user_name, and tenant_id. Our first transformation is to add masked_user_name column to the DataFrame. After the transformation, we end up with a DataFrame containing four columns: user_id, user_name, masked_user_name, and tenant_id. Then, we perform another transformation to remove the user_name column, which results in a DataFrame containing three columns: user_id, masked_user_name, and tenant_id. Lastly, we join the DataFrame with another DataFrame containing two columns: tenant_id and tenant_name. It might seem like we have done a lot of calculations up to this point. However, the truth is that we have merely performed DataFrame transformations without involving any evaluation, since DataFrames are lazily evaluated. The evaluation only starts after the all() method is called on the final DataFrame, which is the only action in the entire process.
To sum up, lazy evaluation facilitates Spark’s effort to optimize time and space performance, and Spark relies on DataFrames and Transformations to achieve lazy evaluation. I hope this article helps improve your understanding of Spark and lazy evaluation.
Further readings: Catalyst Optimizer : The Power of Spark SQL Deep Dive into Spark SQL’s Catalyst Optimizer Directed Acyclic Graphs Actions, Narrow Transformations, and Wide Transformations